 membase默认bucket写入问题及解决
membase默认bucket写入问题及解决







 在项目中遇到membase默认bucket无法写入数据的问题,通过对比生产环境和开发环境,发现membase服务器版本不同是关键因素。进一步跟踪发现,membase默认bucket在初始化时未正确设置身份验证信息,导致请求验证失败。通过手动配置身份验证信息,成功解决了默认bucket的写入问题,并介绍了使用MemcachedClient进行初始化的替代方案。
在项目中遇到membase默认bucket无法写入数据的问题,通过对比生产环境和开发环境,发现membase服务器版本不同是关键因素。进一步跟踪发现,membase默认bucket在初始化时未正确设置身份验证信息,导致请求验证失败。通过手动配置身份验证信息,成功解决了默认bucket的写入问题,并介绍了使用MemcachedClient进行初始化的替代方案。
最近项目中使用的membase发现出了点问题,生产环境中读写各种数据都正常,可是新搭建的开发环境下,只有default bucket写不进去数据,调用store总是返回FALSE,配置文件也是一模一样,实在不知道哪里出问题了,其他的几个bucket都正常读写,而且,在开发环境的membase上在新建一个bucket也是正常读写的。最后发现生产上windows版本的membase,而开发环境是Linux(centos)版本,怀疑可能跟server版本有关系,于是新装了一个windows版本的,果然,一切正常。至于Linux版本的(couchbase)为什么出这个问题,还是得花时间找找原因的。
项目使用的dll:membase.dll 2.14.0.0,Enyim.Caching.dll 2.11.0.0,反编译是可以看到代码的,但是不好调试,可以在网上找到相应的源码:
第二个是把membase的源码包在了LightFramework.Caching项目中,我就是那这个代码来查原因的。
既然是store失败,那我们单步跟踪,看看default的bucket和其他bucket在store方法中有哪里不一样。
public bool Store(StoreMode mode, string key, object value) { ulong tmp = 0; return this.PerformStore(mode, key, value, 0, ref tmp); }
可以看到实际调用的是PerformStore方法,跟进去后发现var node = this.pool.Locate(hashedKey);会返回null,也就是没有找到对应的bucket了,那还写什么数据啊。
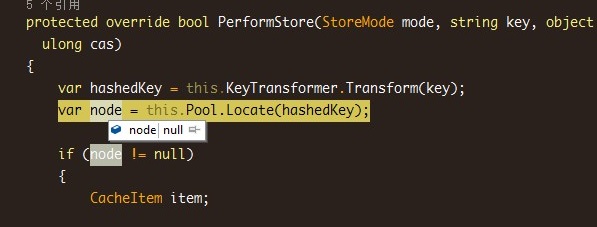
查查为什么返回是null,我们发现在初始化membaseclient实例时,需要向注册的serverurl获取该bucket信息(是否合法,状态是否正常等),调用ResolveBucket方法,结果异常了。401错误,未授权!
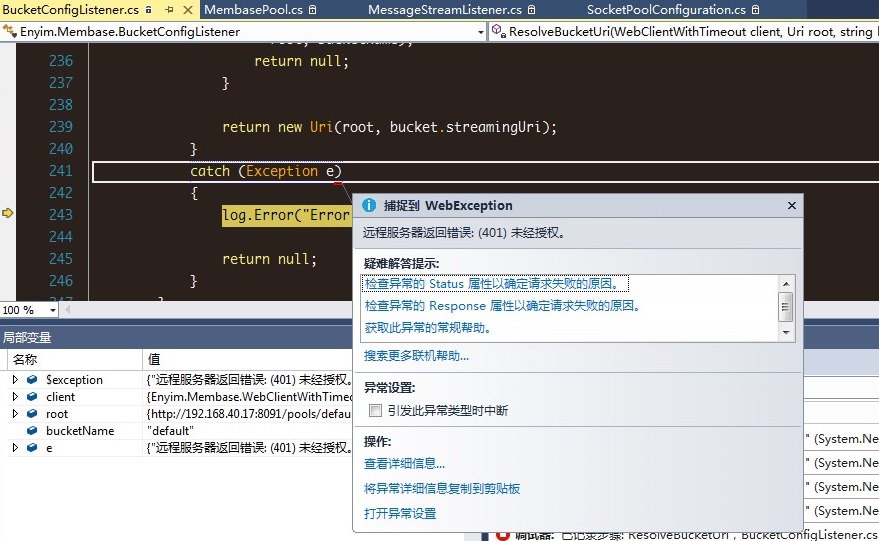
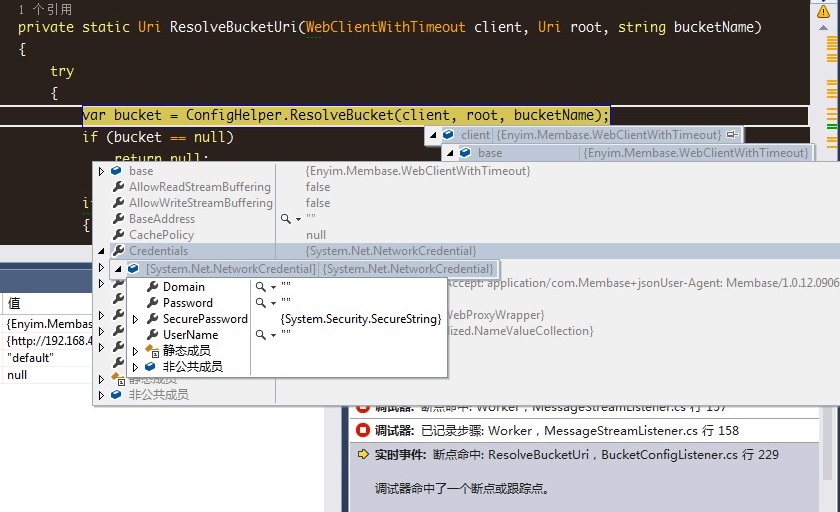
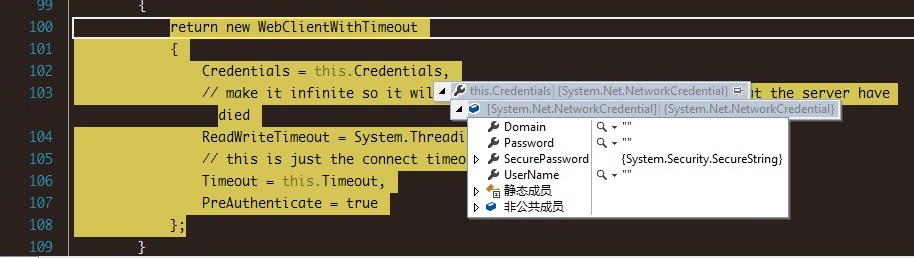
我们使用其他bucket初始化时,发现该方法的client参数中credential是有值的(username、password),而default的bucket却都是null。应该就是这个原因导致的。手动将credential的username设为default,再次请求bucket验证信息,果然,正确返回了。
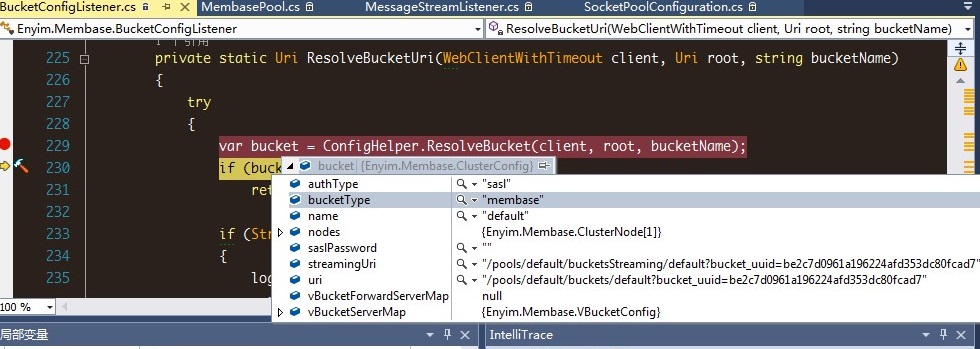
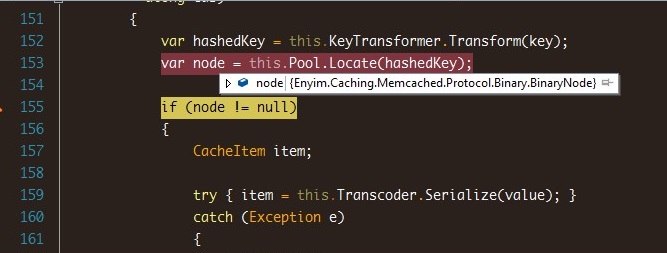
纳闷了,不是默认的default不能设置密码的么,怎么这里有需要验证呢?Google相关的问题,发现不少人都不知道怎么破,甚至说是membase的bug:
- http://grokbase.com/t/gg/enyim-memcached/11anh26mtr/membase-client-401-getting-config-from-pool-url
- https://issues.couchbase.com/browse/MB-2166
- http://qnalist.com/questions/5796245/membase-client-401-getting-config-from-pool-url
- http://grokbase.com/t/gg/enyim-memcached/11anh26mtr/membase-client-401-getting-config-from-pool-url
在查找问题的过程中,我发现如果bucket是default,membase.dll会将其bucketname和password都置空,意思是不需要身份验证,走的是特殊端口11210(其他bucket走的是11211验证),既然注释都这么讲了,那为毛在bucket验证信息的请求中还需要身份验证呢?
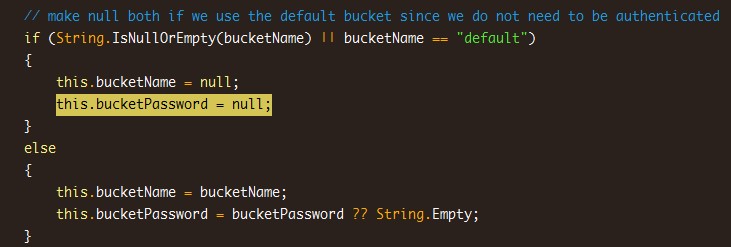
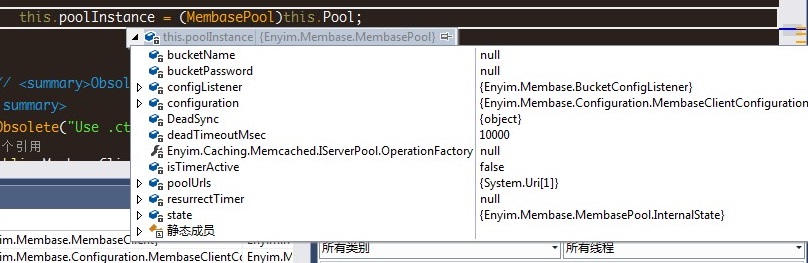
Default无法写入的问题就是由上面的原因导致的,对于windows版本的membase server是不存在的,我测试过,对于default bucket没有身份验证的限制。而对于Linux版本,通过源码跟踪过程中,将身份验证信息手动改好,也是可以正常读写的,可惜的是,无法在外部初始化membaseclient时将其credential配置正确。有另一个解决方案,就是使用MemcachedClient,因为membase是兼容memcached sdk的,所以可以按照下面的方式初始化操作实例:
var config = new MemcachedClientConfiguration(); config.AddServer("192.168.1.12",11211); var client = new MemcachedClient(config); client.Store(StoreMode.Set, DateTime.Now.ToString("HHmmss"), "testValue");
这种方式读写default bucket也是正常的。

















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









