



作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
本次作业是在期中大作业的基础上利用hadoop和hive技术进行大数据分析
1. 准备数据(下图为SCV截图):
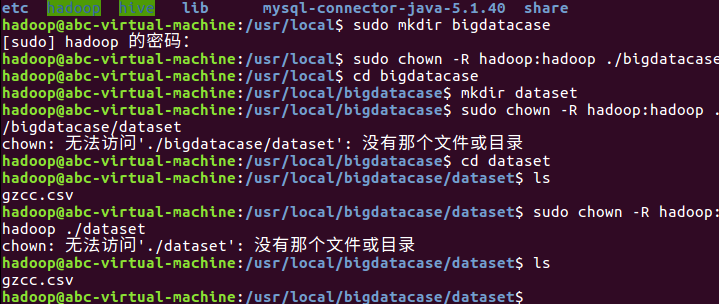
把CSV添加到/bigdatacase/dataset中
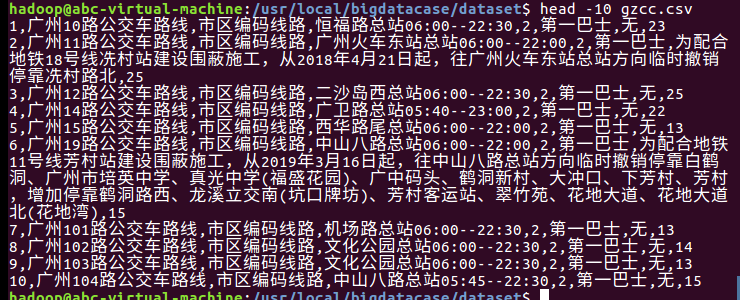
查看前十条数据看是否添加成功
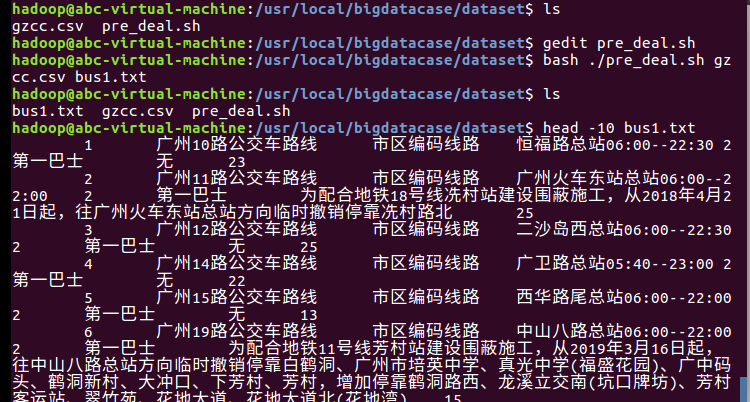
编辑pre_deal.sh以进行文件预处理:

查看是否与处理成功:
把文件上传到Hadoop上:
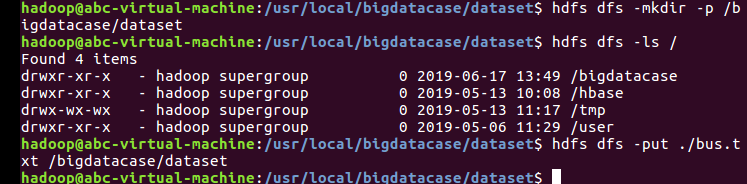
把hdfs中“/bigdatabase/dataset”目录下的数据加载到了数据仓库的hive中:
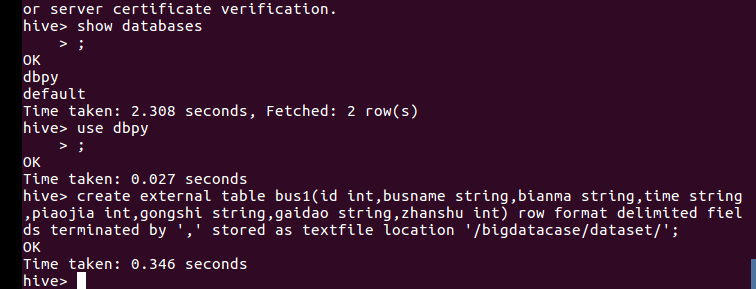
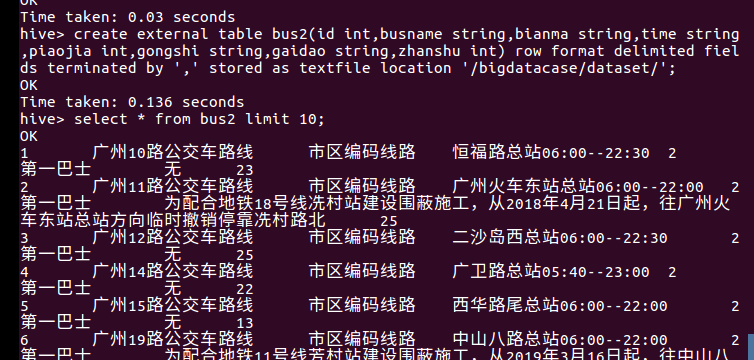
3.用Hive对爬虫大作业产生的进行数据分析(10条以上的查询分析)
1、查询票价前十的站点及公交车号
select busname,time,piaojia from bus2 ORDER BY(piaojia) DESC;
这些车如果坐的站少会很亏喔!
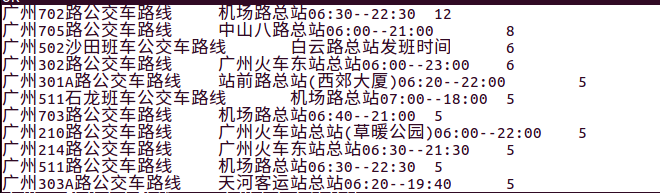
2、查询普遍票价为多少钱
select piaojia,count(piaojia) from bus2 group by(piaojia);
图中开出很明显两元的票价最为普遍。
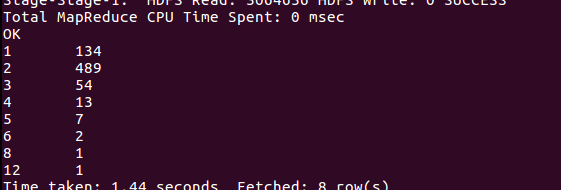
3、公交车经过站数情况
select busname,zhanshu from bus2 ORDER BY(zhanshu) DESC;
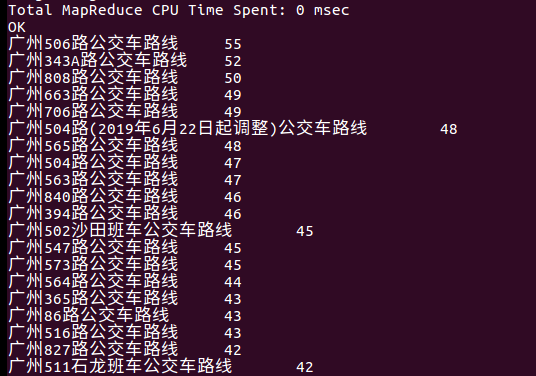
广州最多的一条线有55个站,身为经历过345A煎熬的广商学生也才31个站。
4、站数和票价的关系
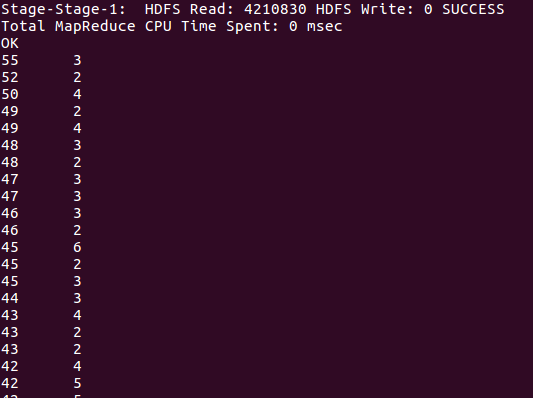

由图中看出站数和票价没有实际联系。
5、广州汽车公司种类
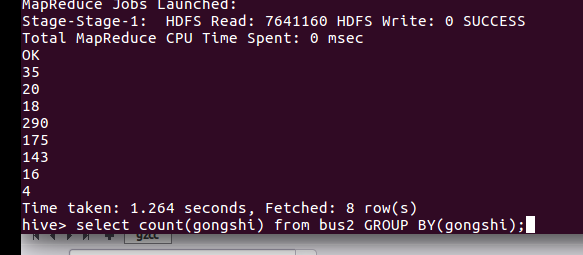
广州有8个巴士公司。
6、各种汽车公司规模
select gongshi,count(gongshi) from bus2 group by(gonshi);
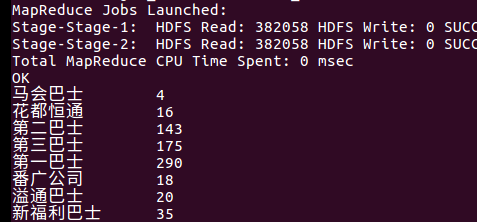
由图可知第一巴士公司是广州的汽车龙头公司拥有的线路最多,第二和第三差不多,最少线路是马会巴士。
7、各公司汽车的票价情况
第一巴士票价情况:
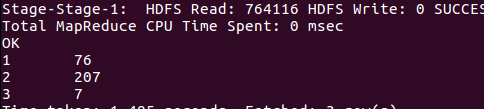
第二巴士票价情况:
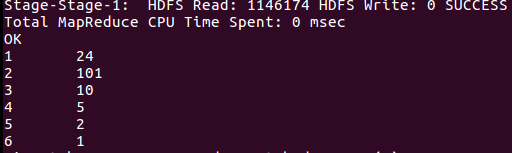
第三巴士票价情况
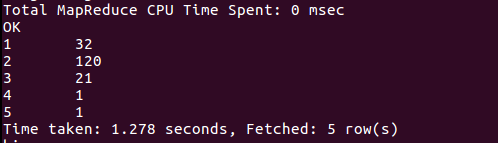
马会巴士票价情况:
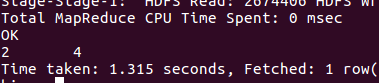
花都恒通票价情况:
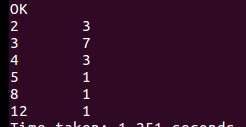
番广公司票价情况:
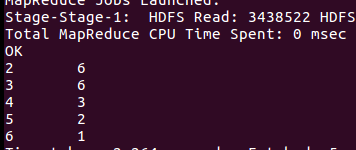
沙溢巴士票价情况:
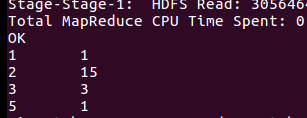
新福利巴士票价情况:
规模最大的第一巴士票价在1-3元并不是越大的公司就有越贵票价的路线,而规模小的公司反而有票价贵的路线。说明票价和公司规模无关。
综合上面的分析汽车票价只与路段有关。
8、各路公交车发车时间情况
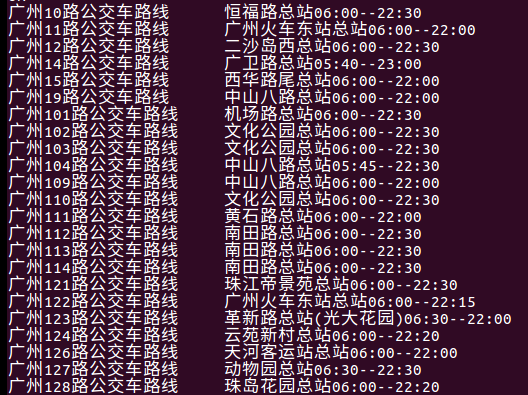
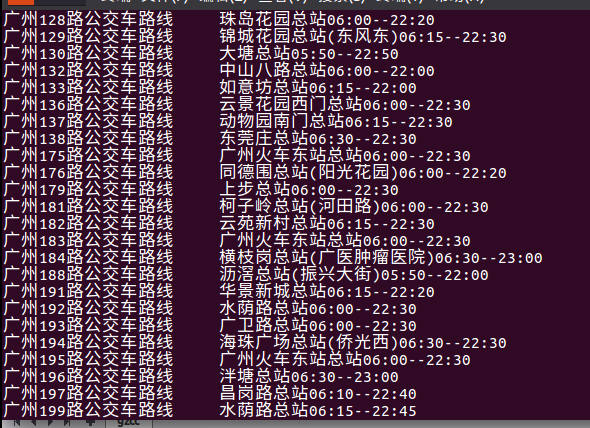
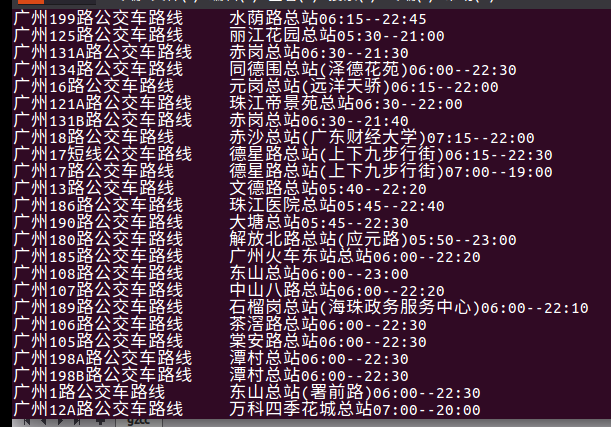
公交开的时间都很早,一般到晚上10点多就结束。
9、汽车改变道路的原因
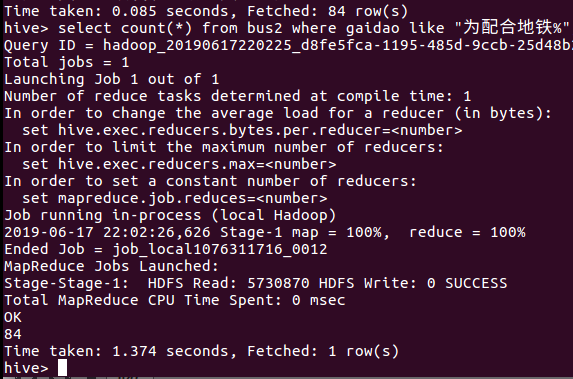
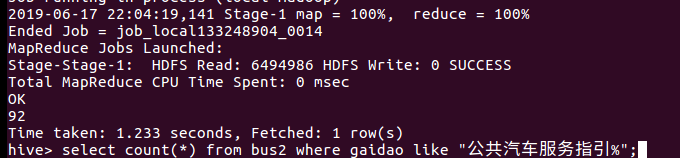

配合地铁,公共汽车服务指引和公共中小巴服务指引在该表车道的原因中占比较大。
10、广州公交种类数
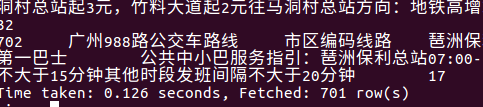
广州有701种公交线路。
以上就是我分析的全部内容。

















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









