






 CTPN是一种先进的文本检测算法,利用VGG16和RNN在自然场景中精确提取文本。它通过固定宽度的anchor预测垂直坐标,结合BLSTM增强识别准确性。
CTPN是一种先进的文本检测算法,利用VGG16和RNN在自然场景中精确提取文本。它通过固定宽度的anchor预测垂直坐标,结合BLSTM增强识别准确性。
Connectionist Text Proposal Network
简介
CTPN是通过VGG16后在特征图上采用3*3窗口进行滑窗,采用与RPN类似的anchor机制,固定width而只预测anchor的y坐标和高度,达到比较精准的text proposal效果。同时,文章的亮点在于引入了RNN,使用BLSTM使得预测更加精准。CTPN在自然场景下文本提取的效果很不错,不同于传统的bottom-up方法,传统方法通过检测单个字符然后再去连接文本线,其准确性主要依赖于单个字符的识别,而且错误会累积,其使用的仅仅是low-level的feature;而本文采用的方法提取的是深度的特征,采用anchor机制做的精准预测,然后用循环神经网络对anchor识别的区域进行连接,精度要高很多。
结构:
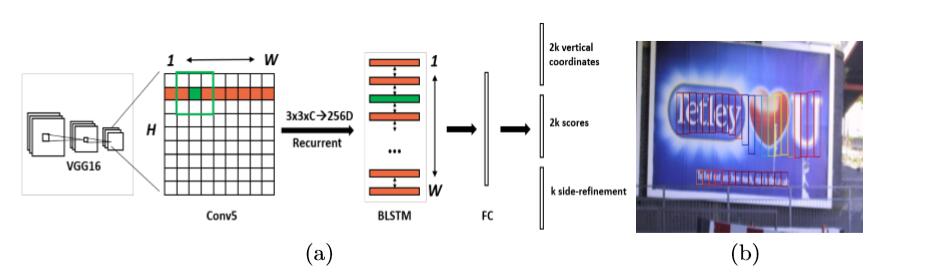
Detecting Text in Fine-scale Proposals
detection过程很简单,直接在vgg-16后面用3*3的滑窗去滑feature map的最后一个卷积层,固定感受野大小为228pixels,total stride为16pixels,这样每个anchor对应在原图中的间隔就是16pixels。total stride和感受野的大小都是由网络结构决定的,也就是说,在网络结构确定的情况下,我们可以人为地去设置感受野的大小和total stride,由于total stride = s *2 *2 *2 *2,由于设置的total stride =16 ,所以可以确定3*3的stride是1,也就是后面每个anchor的水平距离在原图中对应的是16pixels。
之后,作者修改了原始的rpn,去预测长度固定为16pixels的区域,与rpn不同的是,本文只预测区域的y轴坐标和高度,此外,还输出anchor是或不是文字区域的二分类结果。由于上面确定了每次anchor移动的距离恰好是total stride,所以这里对应上了。然后对每个特征点设计了10种vertical anchor,这些anchor的宽度都为16pixels,高度从11 到 273pixels(每次除以0.7),让这10个anchor独立地预测中心点坐标(vc)和高度(vh),定义如下:
对每个预测而言,水平坐标和k个anchor的位置是固定的,这些都是可以预先在图像进来之后计算出来的,而分类器输出的结果是text/non-text的得分和预测的k个anchor的y轴坐标(v)。而识别出来的text proposals 是从那些text/non-text的得分大于0.7,然后再经过MNS得到的。这样只预测纵坐标的做法比rpn的准确率提升了很多,因为其提供了更多的监督信息。
Recurrent Connectionist Text Proposals
本文的亮点就在于使用了循环神经网络来连接text proposals,为了提升定位的准确率,作者把文本线看成是一连串的text proposals,然后去单独预测,但是这样做发现很容易错将非文字区域识别为文字区域。由于RNN对处理上下文很好,而文字有着很强的上下文关联,所以作者顺理成章的引入RNN,将conv5层的feature的每个window扫描后的结果作为RNN的输入,然后循环更新这个隐状态定义如下:

作者使用的是双向LSTM作为RNN的结构,因此每个window都具有他之前的window的上下文信息,每个window的卷积特征作为256D的 双向lstm的输入,然后将每个隐状态全连接到输出层,预测第t个proposal。
使用RNN后,明显减少了错误的识别,将很多之前没识别到的地方也识别到了,说明上下文信息对预测确实很有帮助。
Side-refinement
由于预测的text proposal 可能与ground truth在最左和最右两边不一定重叠度高,所以可能被弃掉,因此提出了边框修正,来修正这一点,如果不修正,那么预测到的proposal的文字区域可能在两边有缺失。

结果如下

Outputs And Loss Functions
模型一共有三个输出,分别是text/non-text scores、竖直坐标v(包括anchor在原图中对应的竖直坐标和高度)以及修正系数o。对于每个特征点k个anchor,分别输出2k,2k,k个参数,而文章也是采用了多任务学习来进行优化模型参数,模型的loss functions定义如下:

分类误差用的是softmax计算的,回归误差用的是smooth L1函数计算的,两个λ是为了调整loss的权重。

















 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









