




 本文提出一种用于任意形状文本检测的深度关系推理图网络(DRRG),通过建立局部图和深度关系推理,实现端到端的文本检测。该方法在多个数据集上表现优异,特别是在Total-Text、CTW1500和TD500数据集上。
本文提出一种用于任意形状文本检测的深度关系推理图网络(DRRG),通过建立局部图和深度关系推理,实现端到端的文本检测。该方法在多个数据集上表现优异,特别是在Total-Text、CTW1500和TD500数据集上。
[论文阅读]Deep Relational Reasoning Graph Network for Arbitrary Shape Text Detection
用于任意形状文本检测的深度关系推理图网络
文章收录于2020 CVPR
[论文地址]https://arxiv.org/abs/2003.07493
[代码地址]https://github.com/GXYM/DRRG
摘要
本文针对形状文本检测提出了一种新的统一关系推理图网络。局部图(local graph)建立起了基于CNN的text proposal模型和基于GCN(Graph Convolutional Network)的深度关系推理网络之间的关系,使模型可以端到端训练。
简介
目前一些方法,例如TextSnake[17]和CRAFT[1]为了解决任意形状文本检测,采用了Connected Component (CC)策略(一些列的组件定位字符,最后合并组件)。这样的缺点就是,无法获得文字组件之间的更丰富的关系,从而无助于文本实例的划分。
对于CC策略来讲,一项重要的工作就是划分文本实例。现有的方法常采用:预定义规则(pre-defined rules)、链接映射(link map)、嵌入映射(embedding map)。对于长文本和弯曲文本,一般来讲,链接映射和嵌入映射比预定义规则更加鲁棒。
链接映射与嵌入映射的方法大多基于CNN,且CNN不适合处理这些独立的组件(非欧几里得数据),即不能够从两个不相邻的组件中学习相互之间的关系。
而这些非欧几里得数据可以被表示为图,如图1所示,本文选择一个文本组件作为一个节点,选择一个节点作为中枢,将中枢周围的节点连起来形成局部图。局部图(节点之间的边缘)中包含的上下文信息可为估计枢纽节点与其他节点之间的链接可能性提供信息。

本文首先将每一个文本实例,切分为文本组件。使用基于CNN的text proposal network预测这些文本组件的几何属性(高、宽、方向),然后利用这些几何属性采用了图卷积网络来执行深度关系推理,从而对这些组件进行分组聚合。
相关工作
基于回归的方法:此类方法使用单词级别(word level)或者行级别(line level)的ground-truth,通过基于框回归的文本检测框架。
- RRD[11]调整SSD [13]的锚定比,以适应非规则形状的宽高比变化。
- Textboxes ++ [10]修改了卷积核和锚定框,以有效地捕获各种文本形状。
- EAST [42]直接推断候选单词的像素级四边形,而无需锚定机制和proposal检测。
基于分割的方法:受语义分割思想的启发,通过估计单词边界区域来检测文本。
- PixelLink [3]通过预测像素与其相邻像素之间的链接关系,对属于同一实例的像素进行分类。
- PSENet [30]采用多种尺度渐进扩展网络,利用ground truth生成一系列不同大小的mask,最终提高了不规则文本的检测能力。
- Tian等人[28]将每个实例文本视为一个聚类,通过嵌入映射对像素进行聚类。
- TextField [34]采用深度方向域(deep direction field)来链接相邻像素并生成候选文本部分。
基于CC的方法:首先通常检测单个文本部分或字符,然后通过链接或者分组的后续处理生成最终的文本。
- CTPN [27]使用了一个基于Faster R-CNN [20]修改的网络,来提取具有固定宽度的文本,以轻松连接密集的文本组件并生成水平文本行。
- SegLink [21]将每个场景文本分解为两个可检测的元素,即段和链接,其中链接指示一对相邻的段属于同一单词。
- CRAFT [1]通过探索每个字符与字符之间的亲和关系来检测文本区域。
- TextDragon[4] 首先检测文字的局部区域,然后根据边界框的几何关系对其进行分组
关系推理:对于局部卷积算子的限制,CNN不能直接捕获远距离分量区域之间的关系。最近,Wang等人[33]为了解决这种问题,提出了基于频谱的GCN方法来聚类人脸。在复杂情况下,设计的GCN可以合理地链接属于同一个人的不同面部实例。
方法
概述
首先,通过基于CNN的text proposal network利用共享特征来估计文本组建的几何属性;然后局部图可以大致建立不同文本组建的链接;然后使用深度关系推理网络将进一步推断出文本组件与其相邻组件之间的链接可能性;最后根据推理结果将文本组件聚合为整体的文本实例。
其网络框架如图2所示;文本组件提议网络(text component proposal network)和深层关系推理图网络共享卷积特征,并且共享卷积使用VGG-16 和FPN [12]作为主干,如图3所示。


文本组件预测
如图4所示,(a)展示了一系列的文本组件,每个文本组件 D D D由(x,y,h,w,sin θ \theta θ,cos θ \theta θ)组成。其中 h h h为文本组件的高度,由(c )图中的h1和h2两部分组成。 w w w则是根据 h h h的大小确定的。
(b)中展示了文本组建的中心域,为了确定文本中心域(text center region 记为TCR)与文本组件的方向,本文采用了[17]中的方法来计算文本域的head和tail,如图4(a)中黑色箭头所示。
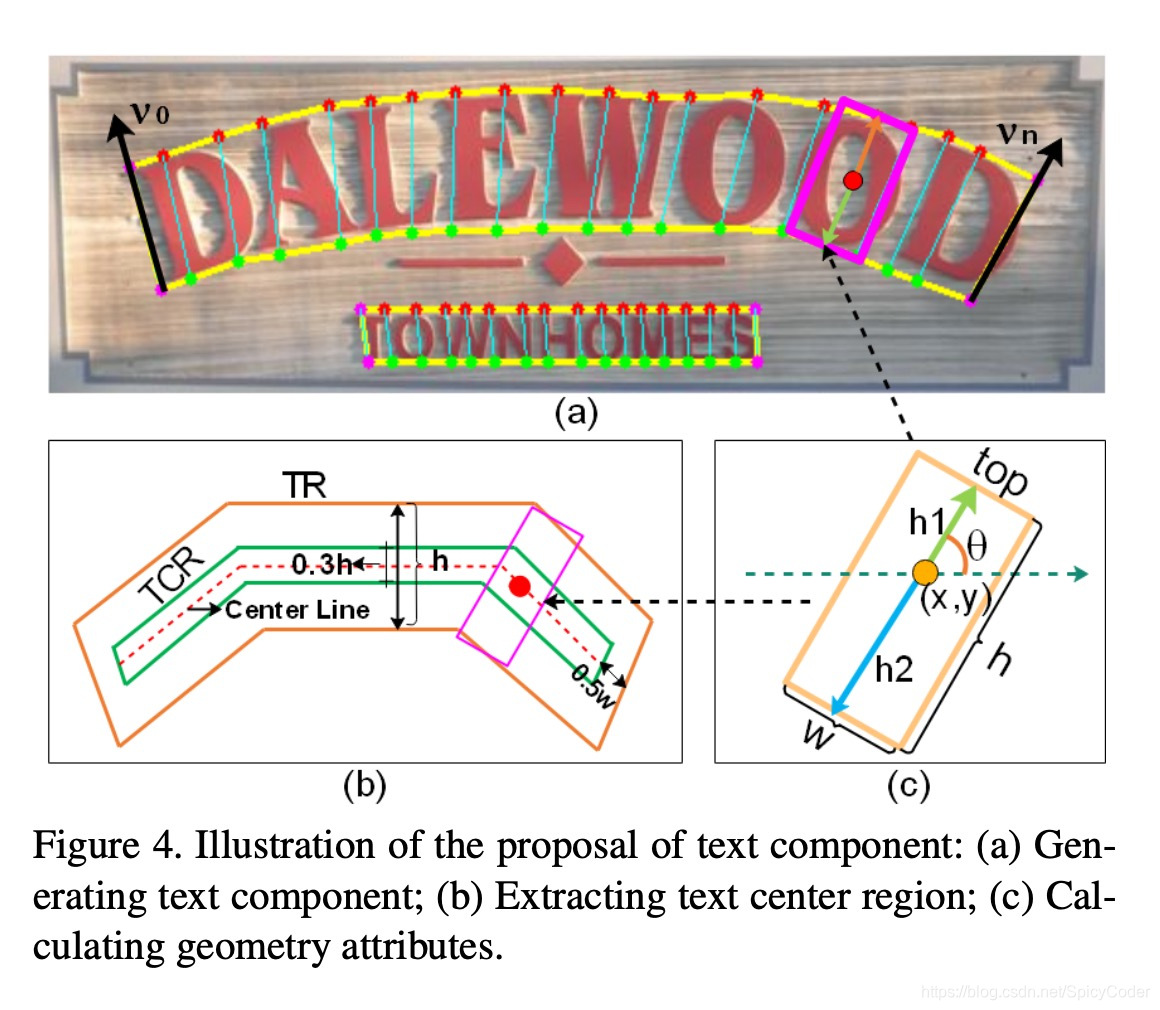
本文根据下列公式确定图4(a)中的上下两组点 P 1 = { t p 0 , t p 1 , . . . , t p i , . . . , t p n } P1= \left\{tp0,tp1,...,tpi,...,tpn\right\} P1={
tp0,tp1,...,tpi,...,tpn}和 P 2 = { b p 0 , b p 1 , . . . , b p i , . . . , b p n } P2= \left\{bp0, bp1, ..., bpi, ..., bpn\right\} P2={
bp0,bp1,...,bpi,...,bpn}。
p = ∑ i = 0 n sin ( v i ) , v i ∈ V p=\sum_{i=0}^{n} \sin \left(v_{i}\right), v_{i} \in V p=i=0∑nsin(vi),vi∈V
其中 V = { t p 0 − b p 0 , . . . , t p i − b p i , . . . , t p n − b p n } V = \left\{tp0 − bp0,...,tpi − bpi,...,tpn − bpn\right\} V={
tp0−bp0,...,tpi−bpi,...,tpn−bpn},向量 v i v_i vi的角度表示文本分量的方向 θ θ θ
TCR是通过缩小文本域(text region 记为TR)得到的,其计算步骤:1. 计算文本中心行 2.将中心行两端缩小0.5 w w w像素,使网络更容易分离相邻的文本实例并降低NMS的计算成本。 3.将文本中心行高度扩展0.3 h h h。
再提取共享特征之后,通过两个卷积层来计算CR(Classification and Regression),即文本组件的几何属性, C R = conv 1 × 1 ( conv 3 × 3 ( F share ) ) C R=\operatorname{conv}_{1 \times 1}\left(\operatorname{conv}_{3 \times 3}\left(F_{\text {share}}\right)\right) CR=conv1×1(conv3×3(Fshare))
其中CR是一个 H ∗ W ∗ 8 H*W*8 H∗W∗8大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









