






 本文深入探讨了ELECTRA和BERT两种预训练模型的区别,通过生动的例子解释了它们的工作原理。ELECTRA通过引入判别器和生成器的结构,有效提升了模型效率和准确性,相较于BERT,在相同资源下展现出更优的性能。
本文深入探讨了ELECTRA和BERT两种预训练模型的区别,通过生动的例子解释了它们的工作原理。ELECTRA通过引入判别器和生成器的结构,有效提升了模型效率和准确性,相较于BERT,在相同资源下展现出更优的性能。
举个形象的例子来描述一下BERT和ELECTRA的区别(之前在网上看到的),学习语文的时候,老师为了加深你对汉语的理解,给你一段话,BERT就像老师会随机把文章中的词去掉,让你根据上下文来填空,我们会根据常识和上下文之间的联系填好空缺词。ELECTRA就像老师加大了难度,把这篇文章的某些词替换掉(ELECTRA的生成器generator),让你指出哪些地方用词不当(ELECTRA的判别器discriminator)。
简介
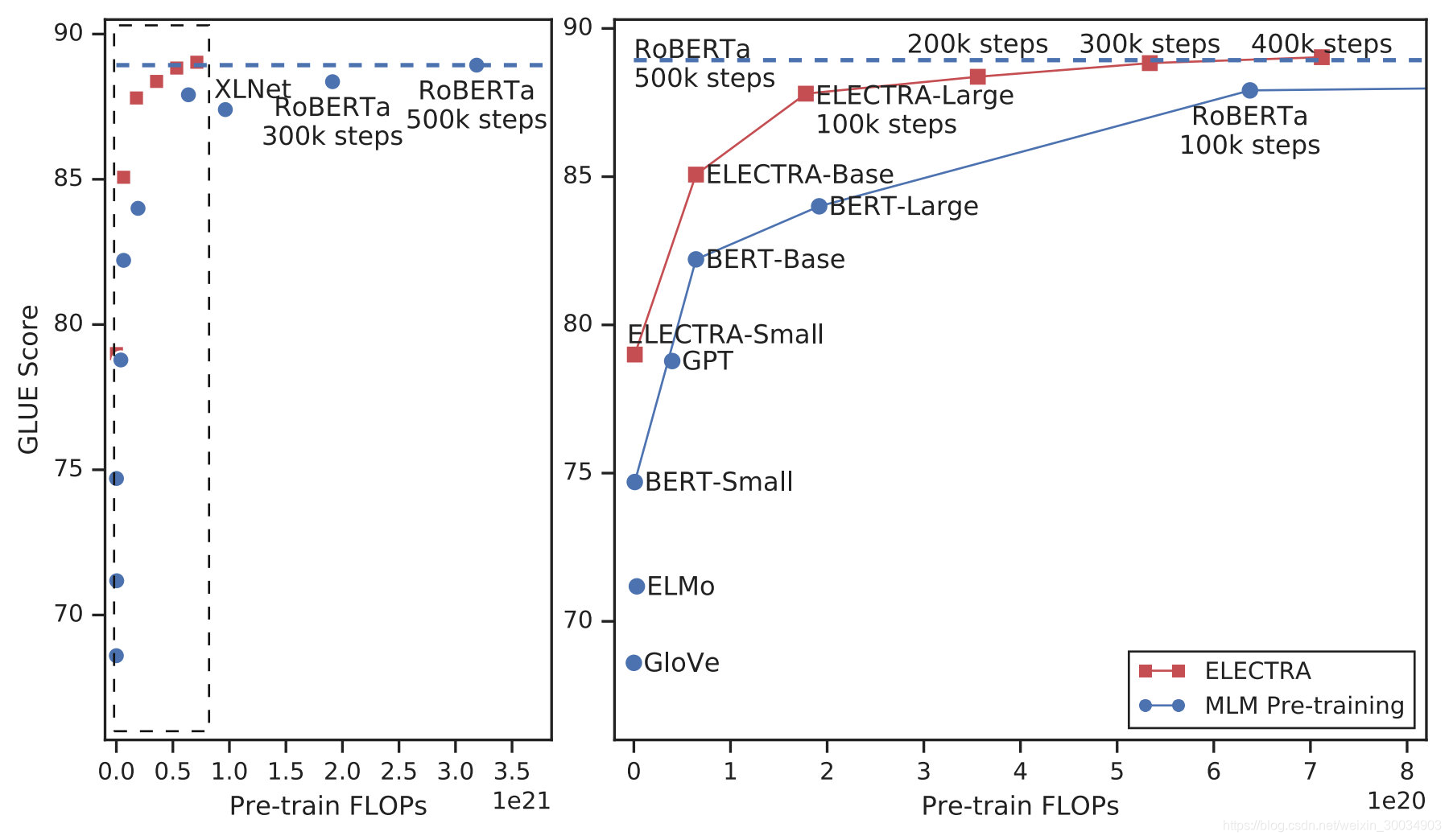
ELECTRA 是 Efficiently Learning an Encoder that Classifies Token Replacements Accurately 的简写,模型以 GLUE Score 作为性能指标。从图中 可以看出,在相同的模型大小、数据和计算条件下,ELECTRA 的性能明显优于基于 BERT 和 XLNet 的基于 MLM 的方法。ELECTRA-Small(可以在4天内用1块GPU上完成训练)不仅比 BERT-Small 要好,甚至还优于更大的 GPT 模型。而在更大规模下,模型取得了和 RoBERTa 相匹配的性能,但是只使用了不到 1/4 的计算量并且参数量更少。
模型结构
ELECTRA跟BERT的区别在于把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。
Generator-Discriminator
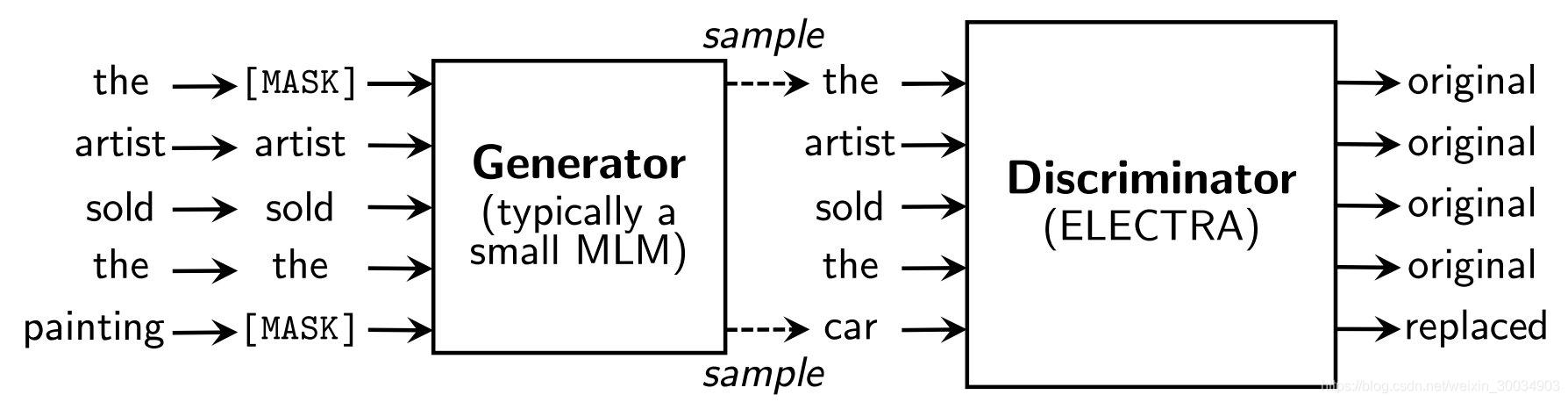
BERT使用MLM任务进行训练,其中有15%的token会被Mask掉,BERT只会对这15%的token进行预测,由于只关注这15%的输入,其他的信息全部成了空气,而ELECTRA还会关注剩下的85%的信息。直观上看就是 Bert利用了15%,而ELECTRA利用了100%。
ELECTRA和BERT的Mask的概率一样,都是15%。首先,Electra使用Generator(生成器)对Mask掉的文本进行预测,例如:
the chef cooked the meal -> [MASK] chef [MASK] the meal
经过Generator进行预测,这句话可能变成:
the chef ate the meal
然后我们把这句话输入到Discriminator(判别器)中,Discriminator(判别器)判断这些Token中那些被替换了,输出的结果应该是:
1 1 0 1 1
1表示是原始文本,0表示被替换了。
Generator(生成器)的作用是是选择性的过滤(或者说筛选)负样本,Generator(生成器)还原错误的token当成负样本,丢给Discriminator(判别器),增加Discriminator(判别器)的学习难度。也就是选择性的负采样。
Discriminator(判别器)巧妙地将LM(Language Model)任务转化成了分类任务(序列标注任务),可以看成是All Tokens的二分类问题。Discriminator(判别器)可以learn from all tokens,计算所有token的loss,缓解了bert中出现的mismatch问题。((mismatch问题指的是bert中预训练方式masked LM中,模型的输入有[MASK],但是下游任务并没有[MASK]))
在这里,可能会有人问,Generator(生成器)是不是越强大越好呢?不是的。Generator(生成器)如果太过强大,那么大部分被Mask掉的token会被正确的预测,造成Discriminator(判别器)的负样本比例太少,且负样本难度较大,学习效果不好。因此作者建议Discriminator(判别器)的关键参数量(比如多头注意力的头数,hidden的维度等)是Discriminator(判别器)的四分之一到二分之一最好。
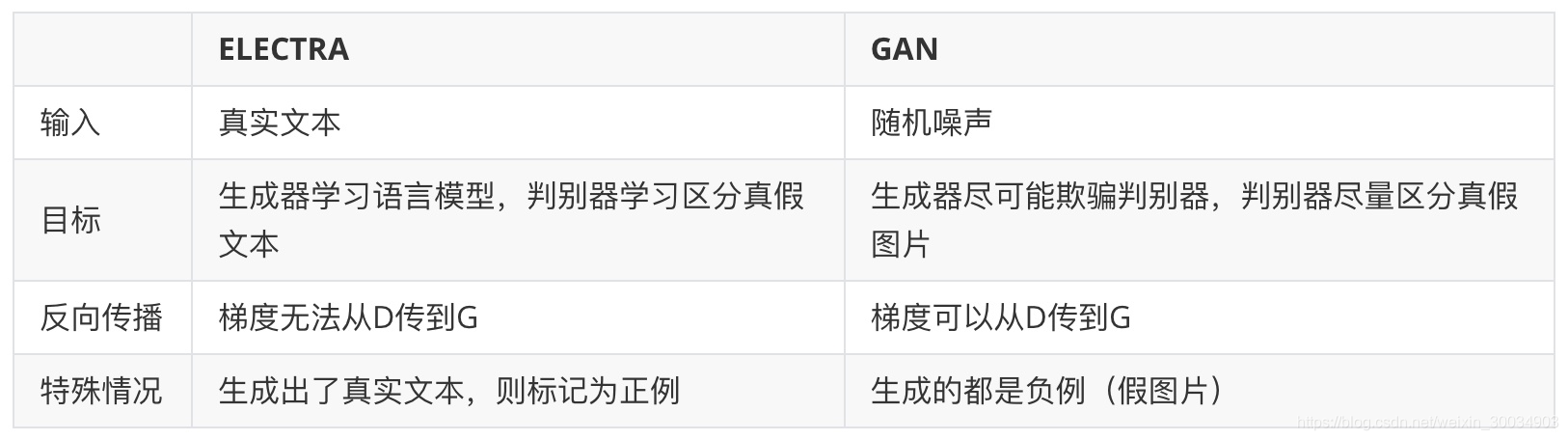
需要注意的是,Generator-Discriminator的结构跟GAN还是有区别的,区别如下:
Replaced Token Detection
输入句子经过Generator(生成器),输出改写过的句子,由于句子的字词是离散的,所以梯度在这里就断了,Discriminator(判别器)的梯度无法传给Generator(生成器),所以Generator(生成器)的训练目标是MLM,Discriminator(判别器)的训练目标是序列标注,两者同时训练,目标函数如下:
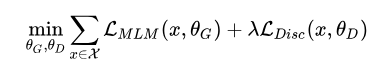
因为判别器的任务相对来说容易些,RTD loss相对MLM loss会很小,因此加上一个系数,作者训练时使用了50。
embedding sharing
Generator(生成器)和Discriminator(判别器)的token embedding是共享的,原因在于Discriminator(判别器)自己每次只能更新Generator(生成器)送过来的负样本+原有正样本的token embedding,更新数量太有限,但是Generator(生成器)可以更新整个词表的 token embedding,因此共享token embedding可以让Generator(生成器)帮助Discriminator(判别器)加快更新token embedding。
参考文章:
https://zhuanlan.zhihu.com/p/89763176
https://zhuanlan.zhihu.com/p/89763176
https://www.zhihu.com/question/354070608

















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









