







一、背景
- bert 进行文本分类,当 max_seq_length 设置为 256 时,模型过于庞大,因此在长文本分类时,需要找寻效果相似,且更为快速的模型,因此找到了 ELECTRA
二、官方文档
三、使用
- git clone https://github.com/ymcui/Chinese-ELECTRA.git
- 下载中文预训练模型:
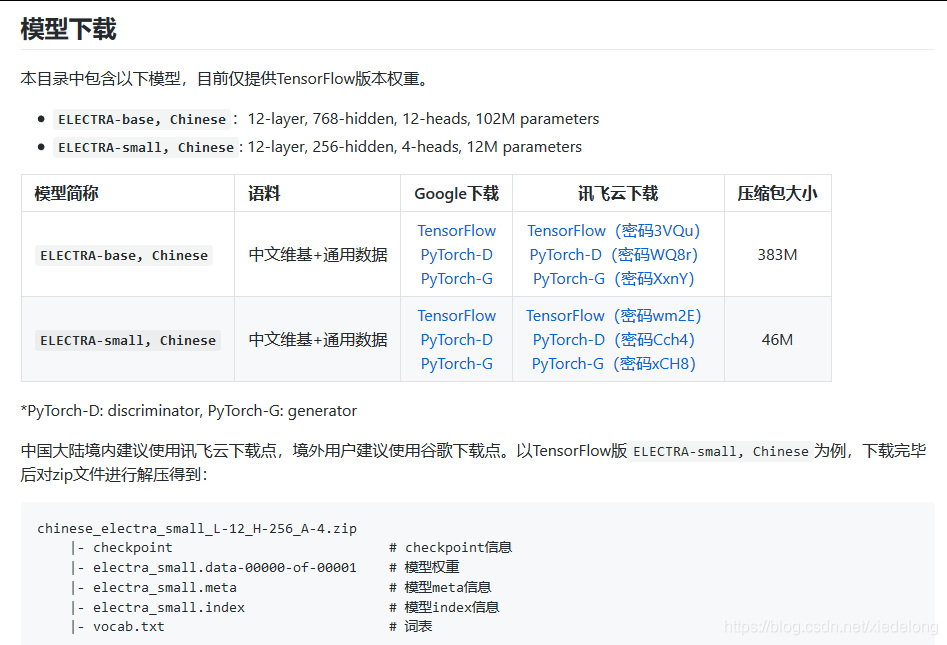
使用方法
用户可以基于已发布的上述中文ELECTRA预训练模型进行下游任务精调。
在这里我们只介绍最基本的用法,更详细的用法请参考ELECTRA官方介绍。
本例中,我们使用ELECTRA-small模型在CMRC 2018任务上进行精调,相关步骤如下。假设,
data-dir:工作根目录,可按实际情况设置。model-name:模型名称,本例中为electra-small。task-name:任务名称,本例中为cmrc2018。本目录中的代码已适配了以上六个中文任务,task-name分别为cmrc2018,drcd,xnli,chnsenticorp,lcqmc,bqcorpus。
第一步:下载预训练模型并解压
在模型下载章节中,下载ELECTRA-small模型,并解压至${data-dir}/models/${model-name}。
该目录下应包含electra_model.*,vocab.txt,checkpoint,共计5个文件。
第二步:准备任务数据
- 下载CMRC 2018训练集和开发集,并重命名为
train.json和dev.json。
将两个文件放到${data-dir}/models/${task-name}。
我自己的 ${data-dir} = train ${task-name} = cmrc2018
通过一步步查看代码,发现两个文件应该是放到
train/finetuning_data/cmrc2018
但是我在train/models/cmrc2018下也放了一份
- 在根目录下存放文件:
params_cmrc2018.json,在本例中的params_cmrc2018.json包含了精调相关超参数,例如:
{
"task_names": ["cmrc2018"],
"max_seq_length": 512,
"vocab_size": 21128,
"model_size": "small",
"do_train": true,
"do_eval": true,
"write_test_outputs": true,
"num_train_epochs": 2,
"learning_rate": 3e-4,
"train_batch_size": 32,
"eval_batch_size": 32,
}
bugfix
解决UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position
# 解决办法:修改 `utils.py` 文件中:
def log(*args):
msg = " ".join(map(str, args)).encode('utf-8')
sys.stdout.write(str(msg) + "\n")
sys.stdout.flush()
第三步:运行训练命令
python run_finetuning.py \
--data-dir ${data-dir} \
--model-name ${model-name} \
--hparams params_cmrc2018.json
其中data-dir和model-name在上面已经介绍。hparams是一个超参数 JSON 词典
python run_finetuning.py --data-dir \train --model-name chinese_electra_small_L-12_H-256_A-4 --hparams params_cmrc2018.json
在上述JSON文件中,我们只列举了最重要的一些参数,完整参数列表请查阅configure_finetuning.py。
运行完毕后,
- 对于阅读理解任务,生成的预测JSON数据
cmrc2018_dev_preds.json保存在${data-dir}/results/${task-name}_qa/。可以调用外部评测脚本来得到最终评测结果,例如:python cmrc2018_drcd_evaluate.py dev.json cmrc2018_dev_preds.json - 对于分类任务,相关accuracy信息会直接打印在屏幕,例如:
xnli: accuracy: 72.5 - loss: 0.67
四、定义自己的分类任务(new task)
The easiest way to run on a new task is to implement a new finetune.task.Task, add it to finetune.task_builder.py, and then use run_finetuning.py as normal. For classification/qa/sequence tagging, you can inherit from(继承) a finetune.classification.classification_tasks.ClassificationTask, finetune.qa.qa_tasks.QATask, or finetune.tagging.tagging_tasks.TaggingTask.
For preprocessing data, we use the same tokenizer as BERT.
- 因为这里是分类任务,因此在
classification_tasks.py中增加一个类(仿照Class CoLA来写,同属于分类任务)如:MyClassifier
class MyClassifier(ClassificationTask):
"""Corpus of qunar chat."""
def __init__(self, config: configure_finetuning.FinetuningConfig, tokenizer):
# [str(i) for i in range(len(labels)] 表示分类任务的类别数量,并转为 str
super(MyClassifier, self).__init__(config, "myclassifier", tokenizer, [str(i) for i in range(len(labels)])
def _create_examples(self, lines, split):
return self._load_glue(lines, split, 1 if split == "test" else 0,
None, 1, split == "test")
def get_scorer(self):
return classification_metrics.MCCScorer()
class CoLA(ClassificationTask):
"""Corpus of Linguistic Acceptability."""
def __init__(self, config: configure_finetuning.FinetuningConfig, tokenizer):
super(CoLA, self).__init__(config, "cola", tokenizer, ["0", "1"])
def _create_examples(self, lines, split):
return self._load_glue(lines, split, 1 if split == "test" else 3,
None, 1, split == "test")
def get_scorer(self):
return classification_metrics.MCCScorer()
- 在
task_builder.py中增加task-name
def get_task(config: configure_finetuning.FinetuningConfig, task_name,
tokenizer):
"""Get an instance of a task based on its name."""
if task_name == "cola":
return classification_tasks.CoLA(config, tokenizer)
elif task_name == "myclassifier":
return classification_tasks.MyClassifier(config, tokenizer)
elif task_name == "mrpc":
return classification_tasks.MRPC(config, tokenizer)
elif task_name == "mnli":
return classification_tasks.MNLI(config, tokenizer)
# ......
- 在根目录增加
params_myclassifier.json文件
{
"task_names": ["myclassifier"],
"max_seq_length": 512,
"vocab_size": 21128, // 不可以修改,因为 electra 的 embedding 层是这个维度
"model_size": "small",
"do_train": true,
"do_eval": true,
"write_test_outputs": true,
"num_train_epochs": 2,
"learning_rate": 3e-4,
"train_batch_size": 32,
"eval_batch_size": 32
}
- 将
train.tsv, dev.tsv, test.tsv放在${data-dir}目录下(\t分隔的两列分别为query \t label的文件),我自己的${data-dir} = train,${task-name} = myclassifier,同样的 通过一步步查看代码,发现两个文件应该是放到train/finetuning_data/myclassifier
python run_finetuning.py --data-dir \train --model-name chinese_electra_small_L-12_H-256_A-4 --hparams params_myclassifier.json


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









