



 本文详细介绍了如何使用Hadoop的MapReduce框架进行词频统计,包括自定义Mapper、Reducer类的实现,数据类型的选择,以及Combiner优化。通过示例展示了从读取输入文件到输出结果的完整过程。
本文详细介绍了如何使用Hadoop的MapReduce框架进行词频统计,包括自定义Mapper、Reducer类的实现,数据类型的选择,以及Combiner优化。通过示例展示了从读取输入文件到输出结果的完整过程。
定义Mapper实现
WordCountMapper extends Mapper
public class Mapper {
......
}
KEYIN : mapping 输入 key 的类型,即每行的偏移量offset(每行第一个字符在整个文本中的位置),Long 类型,对应 Hadoop 中的 LongWritable 类型;
VALUEIN : mapping 输入 value 的类型, 即其实就是一行行的字符串,即每行数据;String 类型,对应 Hadoop 中 Text 类型;
KEYOUT :mapping 输出的 key 的类型,即每个单词;String 类型,对应 Hadoop 中 Text 类型;
VALUEOUT:mapping 输出 value 的类型,即每个单词出现的次数;这里用 int 类型,对应 IntWritable 类型。
WordCountMapper
package com.bigdata.hadoop.mr.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//把value按照指定的分割符分开
String[] words=value.toString().split("\t");
for(String word: words){
context.write(new Text(word),new IntWritable(1));
}
}
}
自定义Reducer实现
public class WordCountReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
}
}
Text数据类型 :字符串类型 String
IntWritable : reduce阶段的输入类型 int
Text : reduce阶段的输出数据类型 String类型
IntWritable : 输出词频个数 Int型
WordCountReducer
package com.bigdata.hadoop.mr.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class WordCountReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count=0;
Iterator iterator = values.iterator();
while(iterator.hasNext()){
IntWritable value = iterator.next();
count += value.get();
}
context.write(key,new IntWritable(count));
}
}
自定义Driver类实现
package com.bigdata.hadoop.mr.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//使用MR统计HDFS上的文件对应的词频
//Driver: 配置Mapper,Reducer的相关属性
public class WordCountApp {
public static void main(String[] args) throws Exception{
System.setProperty("HADOOP_USER_NAME","hadoop");
Configuration configuration= new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.1.200:8020");
//创建一个job
Job job = Job.getInstance(configuration);
// 设置Job对应的参数:设置 Mapper 和 Reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//设置Job对应的参数:Mapper输出Key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置job对应的参数:Reducer输出的key和value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置job对应的参数:作业输出的的路径
FileInputFormat.setInputPaths(job,new Path("/map/input"));
FileOutputFormat.setOutputPath(job,new Path("/map/output8"));
// 将作业提交到群集并等待它完成,参数设置为 true 代表打印显示对应的进度
boolean result=job.waitForCompletion(true);
// 根据作业结果,终止当前运行的 Java 虚拟机,退出程序
System.exit( result ? 0:-1);
}
}
[hadoop@hadoop000 hadoop-2.6.0-cdh5.15.1]$ hadoop fs -cat /map/input/local.txt
helloworld
hellohello
hello
world
[hadoop@hadoop000 hadoop-2.6.0-cdh5.15.1]$
[hadoop@hadoop000 hadoop-2.6.0-cdh5.15.1]$ hadoop fs -ls /map/output8
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2020-08-27 16:01 /map/output8/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 19 2020-08-27 16:01 /map/output8/part-r-00000
[hadoop@hadoop000 hadoop-2.6.0-cdh5.15.1]$ hadoop fs -cat /map/output8/part-r-00000
1
hello4
world2
[hadoop@hadoop000 hadoop-2.6.0-cdh5.15.1]$
本地方式运行
package com.bigdata.hadoop.mr.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//使用MR统计HDFS上的文件对应的词频
//Driver: 配置Mapper,Reducer的相关属性
public class WordCountLocalApp {
public static void main(String[] args) throws Exception{
Configuration configuration= new Configuration();
Job job = Job.getInstance(configuration);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path("input"));
FileOutputFormat.setOutputPath(job,new Path("output"));
boolean result=job.waitForCompletion(true);
System.exit( result ? 0:-1);
}
}
重构代码
问题,当输出目录存在的时候会报错
//如果路径存在就删除
FileSystem fs=FileSystem.get(new URI("hdfs://192.168.1.200:8020"),configuration,"hadoop");
Path output=new Path("/map/outpu");
if(fs.exists(output)){
fs.delete(output,true);
}
//设置job对应的参数:作业输出的的路径
FileInputFormat.setInputPaths(job,new Path("/map/input"));
FileOutputFormat.setOutputPath(job,new Path("output"));
问题区分大小写
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//把value按照指定的分割符分开
String[] words=value.toString().split("\t");
for(String word: words){
//.toLowerCase()
context.write(new Text(word.toLowerCase()),new IntWritable(1));
}
}
Combiner操作
combiner是 map 运算后的可选操作,它实际上是一个本地化的 reduce 操作,它主要是在 map 计算出中间文件后做 一个简单的合并重复 key 值的操作 。这里以词频统计为例:
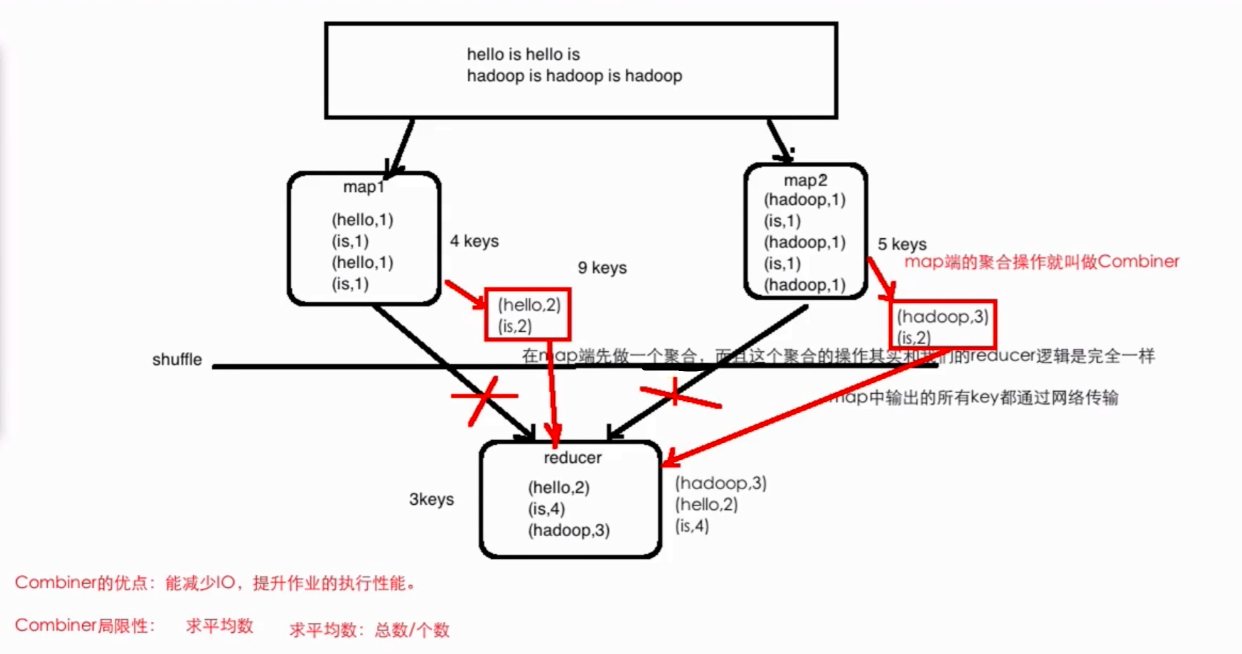
map 在遇到一个 hadoop 的单词时就会记录为 1,但是这篇文章里 hadoop 可能会出现 n 多次,那么 map 输出文件冗余就会很多,因此在 reduce 计算前对相同的 key 做一个合并操作,那么需要传输的数据量就会减少,传输效率就可以得到提升。
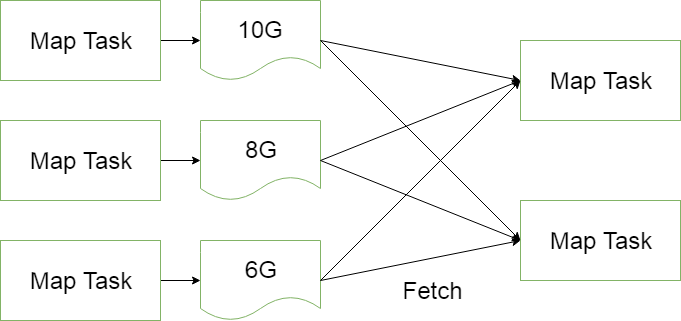
为了避免map任务和reduce任务之间的数据传输而设置的,Hadoop允许用户针对map task的输出指定一个合并函数。即为了减少传输到Reduce中的数据量。它主要是为了削减Mapper的输出从而减少网络带宽和Reducer之上的负载。
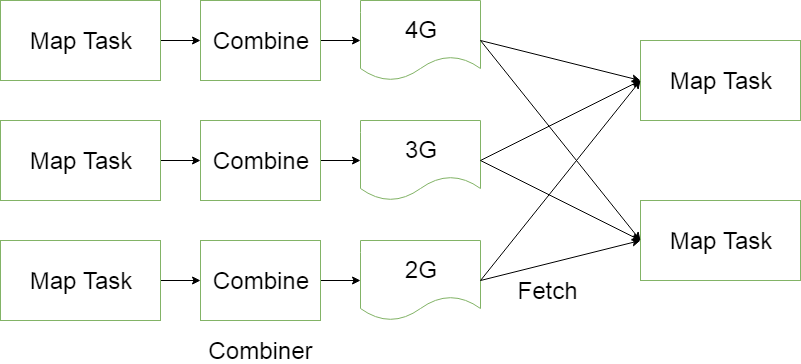
//添加Combiner的设置的即可
job.setCombinerClass(WordCountReducer.class);
但并非所有场景都适合使用 combiner,使用它的原则是 combiner 的输出不会影响到 reduce 计算的最终输入,例如:求总数,最大值,最小值时都可以使用 combiner,但是做平均值计算则不能使用 combiner。


















 8137
8137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









