





 这篇博客介绍了每个数据科学家都应该掌握的20个NumPy操作,重点在于如何遍历矩阵的每一行进行特定的数据处理,帮助提升Python编程效率和数据分析能力。
这篇博客介绍了每个数据科学家都应该掌握的20个NumPy操作,重点在于如何遍历矩阵的每一行进行特定的数据处理,帮助提升Python编程效率和数据分析能力。
numpy遍历每行操作
Everything about data science starts with data and it comes in various formats. Numbers, images, texts, x-rays, sound, and video recordings are just some examples of data sources. Whatever the format data comes in, it needs to be converted to an array of numbers to be analyzed. Hence, it is crucial to effectively store and modify arrays of numbers in data science.
有关数据科学的所有内容都始于数据,并且格式多种多样。 数字,图像,文本,X射线,声音和视频记录只是数据源的一些示例。 无论输入哪种格式的数据,都需要将其转换为要分析的数字数组。 因此,在数据科学中有效地存储和修改数字数组至关重要。
NumPy (Numerical Python) is a scientific computing package that provides numerous ways to create and operate on arrays of numbers. It forms the basis of many widely used Python libraries related to data science such as Pandas and Matplotlib.
NumPy (数字Python)是一种科学计算程序包,它提供了许多创建和处理数字数组的方法。 它构成了许多与数据科学相关的广泛使用的Python库的基础,例如Pandas和Matplotlib。
In this post, I will go over 20 commonly used operations on NumPy arrays. These operations can be grouped under 4 main categories:
在本文中,我将介绍NumPy数组的20多个常用操作。 这些操作可以分为4个主要类别:
- Creating arrays 创建数组
- Manipulating arrays 操纵数组
- Combining arrays 合并数组
- Linear algebra with arrays 带数组的线性代数
We first need to import NumPy:
我们首先需要导入NumPy:
import numpy as np创建数组 (Creating arrays)
Random integers in a specific range
特定范围内的随机整数

The first parameter determines the upper bound of the range. The lower bound is 0 by default but we can also specify it. The size parameter is used to specify the size, as expected.
第一个参数确定范围的上限。 下限默认为0,但我们也可以指定它。 size参数用于指定大小,如预期的那样。

We created a 3x2 array of integers between 2 and 10.
我们创建了一个3x2的2到10整数数组。
2. Random floats between 0 and 1
2.随机浮点数介于0和1之间

A 1-dimensional array of floats between 0 and 1. It is useful to create random noise data.
浮点数的1维数组,介于0和1之间。创建随机噪声数据非常有用。
3. Sample from a standard normal distribution
3.来自标准正态分布的样本
Np.random.randn() is used to create a sample from a standard normal distribution (i.e. zero mean and unit variance).
Np.random.randn()用于根据标准正态分布(即零均值和单位方差)创建样本。

We created an array with 100 floats.
我们创建了一个包含100个浮点数的数组。
4. Matrix with ones and zeros
4.具有一和零的矩阵
A matrix can be considered as a 2-dimensional array. We can create a matrix with zeros or ones with np.zeros and np.ones, respectively.
矩阵可以视为二维数组。 我们可以分别创建一个零矩阵或np.zeros和np.ones的矩阵。

We just need to specify the dimension of the matrix.
我们只需要指定矩阵的尺寸即可。
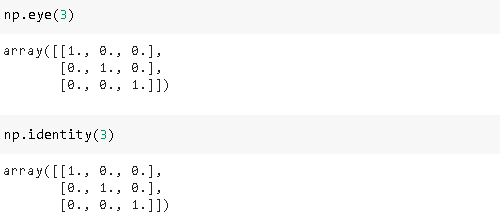
5. Identity matrix
5.身份矩阵
An identity matrix is a square matrix (nxn) that has ones on the diagonal and zeros on every other position. Np.eye or np.identity can be used to create one.
一个单位矩阵是一个方矩阵(nxn),对角线上有一个,其他位置上有零。 Np.eye或np.identity可用于创建一个。
6. Arange
6.范围
Arange function is used to create arrays with evenly spaced sequential values in a specified interval. We can specify start value, stop value, and step size.
Arange函数用于创建在指定间隔内具有均匀间隔的顺序值的数组。 我们可以指定起始值,终止值和步长。
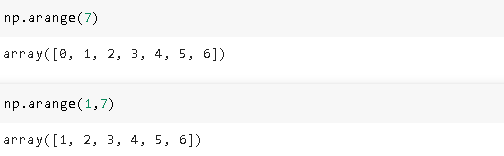
The default start value is zero and the default step size is one.
默认起始值为零,默认步长为一。

7. Array with only one value
7.只有一个值的数组
We can create an array that has the same value at every position using np.full.
我们可以使用np.full创建一个在每个位置都具有相同值的数组。

We need to specify the size and the number to be filled. Also, the data type can be changed using dtype parameter. The default data type is integer.
我们需要指定大小和要填充的数字。 另外,可以使用dtype参数更改数据类型。 默认数据类型是整数。
操纵数组 (Manipulating arrays)
Let’s first create a 2-dimensional array:
首先创建一个二维数组:

8. Ravel
8.拉威尔
Ravel function flattens the array (i.e. convert to a 1-dimensional array).
拉威尔函数拉平数组(即转换为一维数组)。

By default, an array is flattened by adding row after row. It can be changed to column-wise by setting the order parameter as F (Fortran-style).
默认情况下,通过逐行添加来展平数组。 通过将订单参数设置为F(Fortran样式),可以将其更改为列方式。
9. Reshape
9.重塑
As the same suggests, it reshapes an array. The shape of A is (3,4) and the size is 12.
就像暗示的那样,它重塑了数组。 A的形状为(3,4),大小为12。

We need to preserve the size which is the product of the sizes in each dimension.
我们需要保留尺寸,该尺寸是每个尺寸中尺寸的乘积。

We don’t have to specify the size in every dimension. We can let NumPy to figure out a dimension by passing -1.
我们不必在每个维度上都指定尺寸。 我们可以让NumPy通过传递-1来确定尺寸。

10. Transpose
10.移调
Transposing a matrix is to switch rows and columns.
转置矩阵是为了切换行和列。

11. Vsplit
11. Vsplit
Splits an array into multiple sub-arrays vertically.
垂直将数组拆分为多个子数组。

We split a 4x3 array into 2 sub-arrays with a shape of 2x3.
我们将一个4x3数组分成2个形状为2x3的子数组。
We can access a particular sub-array after splitting.
拆分后,我们可以访问特定的子数组。

We split a 6x3 array into 3 sub-arrays and get the first one.
我们将一个6x3数组分成3个子数组,然后得到第一个。
12. Hsplit
12. Hsplit
It is similar to vsplit but works horizontally.
它与vsplit类似,但可水平工作。

If we apply hsplit on a 6x3 arrays to get 3 sub-arrays, resulting arrays will have a shape of (6,1).
如果将hsplit应用于6x3数组以获得3个子数组,则所得数组的形状将为(6,1)。

合并数组 (Combining arrays)
We may need to combine arrays in some cases. NumPy provides functions and methods to combine array in many different ways.
在某些情况下,我们可能需要组合数组。 NumPy提供了以多种不同方式组合数组的函数和方法。
13. Concatenate
13.串联
It is similar to the concat function of pandas.
它类似于熊猫的concat功能。
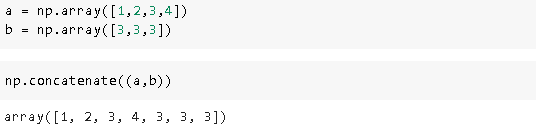
We can convert these arrays to column vectors using the reshape function and then concatenate vertically.
我们可以使用reshape函数将这些数组转换为列向量,然后垂直连接。

14. Vstack
14. Vstack
It is used to stack arrays vertically (rows on top of each other).
它用于垂直堆叠阵列(行彼此重叠)。

It also works with higher dimensional arrays.
它也适用于高维数组。

15. Hstack
15. Hstack
Similar to vstack but works horizontally (column-wise).
与vstack相似,但水平(列方式)工作。

具有NumPy数组的线性代数(numpy.linalg) (Linear algebra with NumPy arrays (numpy.linalg))
Linear algebra is fundamental in the field of data science. NumPy being the most widely used scientific computing library provides numerous linear algebra operations.
线性代数是数据科学领域的基础。 NumPy是使用最广泛的科学计算库,可提供许多线性代数运算。
16. Det
16. Det
Returns the determinant of a matrix.
返回矩阵的行列式。

A matrix must be square (i.e. the number of rows is equal to the number of columns) to calculate the determinant. For a higher-dimensional array, the last two dimensions must be square.
矩阵必须为正方形(即行数等于列数)才能计算行列式。 对于高维数组,最后两个维必须为正方形。
17. Inv
17. Inv
Calculates the inverse of a matrix.
计算矩阵的逆。

The inverse of a matrix is the matrix that gives the identity matrix when multiplied with the original matrix. Not every matrix has an inverse. If matrix A has an inverse, then it is called invertible or non-singular.
矩阵的逆矩阵是与原始矩阵相乘时给出单位矩阵的矩阵。 并非每个矩阵都有逆。 如果矩阵A具有逆,则称其为可逆 或非奇异。
18. Eig
18.艾格
Computes the eigenvalues and right eigenvectors for a square matrix.
计算平方矩阵的特征值和右特征向量。

19. Dot
19.点
Calculates the dot product of two vectors which is the sum of the products of elements with regards to their position. The first element of the first vector is multiplied by the first element of the second vector and so on.
计算两个向量的点积,这是元素相对于其位置的乘积之和。 第一个向量的第一个元素乘以第二个向量的第一个元素,依此类推。

20. Matmul
20. Matmul
It performs matrix multiplication.
它执行矩阵乘法。

We have covered the basic yet fundamental operations of NumPy. There are more advanced operations on NumPy but it is always better to comprehend the basics first.
我们已经介绍了NumPy的基本但基本的操作。 NumPy上有更高级的操作,但是最好先理解基础知识。
Thank you for reading. Please let me know if you have any feedback.
感谢您的阅读。 如果您有任何反馈意见,请告诉我。
numpy遍历每行操作

















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









