






 本文介绍了如何在Python中使用随机森林进行多重插补,这是一种处理缺失数据的方法,源自一篇翻译自Towards Data Science的文章。
本文介绍了如何在Python中使用随机森林进行多重插补,这是一种处理缺失数据的方法,源自一篇翻译自Towards Data Science的文章。
随机森林多重插补数据
Missing data is a common problem in data science — one that tends to cause a lot of headaches. Some algorithms simply can’t handle it. Linear regression, support vector machines, and neural networks are all examples of algorithms which require hacky work-arounds to make missing values digestible. Other algorithms, like gradient boosting (lightGBM and xgboost specifically), have elegant solutions for missing values. However, that doesn’t mean they can’t still cause problems.
数据丢失是数据科学中的常见问题-往往会引起很多麻烦。 有些算法根本无法处理。 线性回归,支持向量机和神经网络都是算法的示例,这些算法需要巧妙的解决方法才能使缺失值易于消化。 其他算法,例如渐变增强(特别是lightGBM和xgboost),对于缺失值也有很好的解决方案。 但是,这并不意味着它们仍然不会引起问题。
There are several situations when missing data can result in bias predictions, even in models that have native handling of missing values:
在某些情况下,即使在具有本机处理缺失值的模型中,缺失数据也会导致偏差预测:
- Missing data is overwritten, and is only sometimes available at time of inference. This is especially common in funnel modeling, where more becomes known about the customer as they make it further in the funnel. 丢失的数据将被覆盖,并且有时仅在推断时可用。 这在渠道建模中尤为常见,因为随着客户在渠道中的不断发展,对客户的了解越来越多。
- The mechanism that causes missing data changes — examples would be new questions on a website, new vendor, etc. This is especially a problem if the mechanism is related to the target you ultimately want to model. 导致丢失数据更改的机制-例如网站,新供应商等上的新问题。如果该机制与您最终要建模的目标有关,则尤其是一个问题。
If only we could know what those missing values actually were, and use them. Well, we can’t. But we can do the next best thing: Estimate their values with Multiple Imputation by Chained Equations (MICE):
如果我们只能知道那些缺失值实际上是什么,并使用它们。 好吧,我们不能。 但是我们可以做下最好的事情:通过链式方程(MICE)的多重插补估算其值:
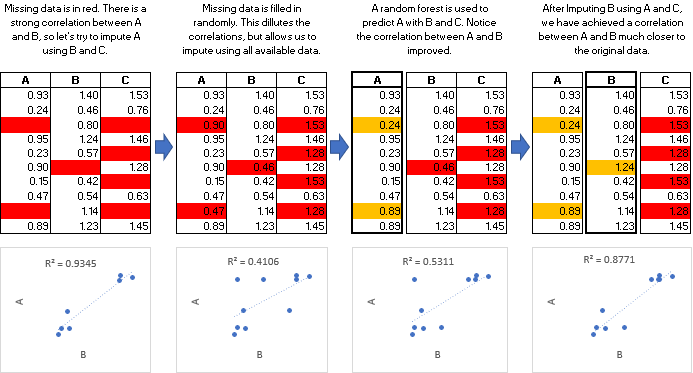
MICE算法 (The MICE Algorithm)
Multiple Imputation by Chained Equations, also called “fully conditional specification”, is defined as such:
链式方程的多重插补,也称为“完全条件规范”,其定义如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









