



 本文分析了《权力的游戏》系列中的对话,通过NLP技术识别关键角色并分类对话,揭示了提利昂·兰尼斯特的重要性和角色的情感倾向。
本文分析了《权力的游戏》系列中的对话,通过NLP技术识别关键角色并分类对话,揭示了提利昂·兰尼斯特的重要性和角色的情感倾向。
应聘对白
The following is a breakdown and explanation of a recent endeavor into NLP. To see my complete work and results please visit my GitHub repository for this project.
以下是最近对NLP的努力的细分和解释。 要查看我的完整工作和结果,请访问我的 GitHub存储库 中的该项目。
The overall intent and purpose of this project was to identify key important characters in the series and to attempt to classify lines of dialogue as the character most likely to speak them.
该项目的总体目的和目的是确定系列中的重要重要人物,并尝试将对话方式归类为最有可能说这些话的人物。
概要 (Synopsis)
Looking into dialogue line distribution and number of words per line it became very apparent that the show seemed to lean most heavily upon the character Tyrion who fairly consistently held the highest number of lines and most words spoken per season and often times per episode. The sheer number of unique characters that appear throughout the series proved to be a problem when trying to model for individual character identification as this ultimately reduced our data based upon the characters we were trying to classify. Initial modeling attempts provided overall accuracy around 24% for our characters with the most lines. Changing methods to classification by family name improved our results up to around 50% and removing all but the Lannisters and Starks gave us an accuracy of around 68%. As for sentiment analysis, most characters seem to average out to being mostly neutral with Sandor Clegane averaging out to be the most typically negative character and both Petyr Baelish and Varys being the most typically positive. Interestingly enough, Tywin Lannister also proved to be almost perfectly neutral.
观察对话行的分布和每行的单词数,很明显,该节目似乎最依赖角色提利昂,后者始终保持着最多的行数和每个季节讲最多的单词,并且每集经常出现次数。 在尝试为单个字符识别建模时,整个系列中出现的大量唯一字符被证明是一个问题,因为这最终会减少我们基于要分类的字符的数据。 最初的建模尝试为线条最多的角色提供了大约24%的整体准确性。 更改姓氏分类方法将我们的结果提高了大约50%,除去Lannisters和Starks之外的所有元素,我们的准确性达到了68%。 至于情绪分析,大多数角色似乎平均表现为中立,而Sandor Clegane则平均表现为最典型的消极角色,而Petyr Baelish和Varys均为最典型的积极角色。 有趣的是,Tywin Lannister也被证明几乎是中立的。
分析 (Analysis)
Initial overview of the data found that there were some inconsistencies with the naming of several characters. Diving deeper into our list of unique characters the following were found to be corrected.
数据的初步概览发现,几个字符的命名存在一些不一致之处。 深入研究我们的独特字符列表后,发现以下问题已得到纠正。

Fixing these names reduced our total number of unique characters from 564 to 520. From here, I began work on an interactive dashboard to allow for easier insight to individual seasons, episodes, and even characters.
固定这些名称后,我们的独特角色总数从564个减少到520个。从这里开始,我开始在交互式仪表板上进行工作,以便更轻松地了解各个季节,剧集甚至角色。
Note that the application can take a few moments when creating word clouds as they are generated based upon all previous selections in the dashboard. For those interested the repository used to create the app, it can be viewed here.
请注意,创建词云时,该应用程序可能会花费一些时间,因为这些词云是根据仪表板中的所有先前选择生成的。 对于那些感兴趣的用于创建应用程序的存储库,可以在 此处 查看 。
Through the app it became apparent quite quickly that the show seemed to hinge upon Tyrion Lannister. This started early on in the show and with the exception of Season 7, he maintained the most spoken character. Especially so in the final episode where he accounted for over 40% of all spoken words. Interestingly enough, while he did tend to have the most lines and most words, the privilege of longest monologue went to Talisa in Season 2 Episode 8.
通过该应用程序,很快就可以看出该节目似乎与提利昂·兰尼斯特有关。 这始于节目的早期,除第7季外,他保持了说话最多的角色。 特别是在最后一集中,他占所有口语的40%以上。 有趣的是,尽管他确实倾向于拥有最多的台词和最多的单词,但最长的独白的特权却出现在第2季第8集中的Talisa。
情绪 (Sentiment)
Using nltk’s Vader sentiment, we then looked into analyzing character sentiment. Looking at our top characters average overall sentiment was interesting.
然后,使用nltk的Vader情感,我们分析了角色情感。 看看我们的主要角色,平均总体情绪很有趣。
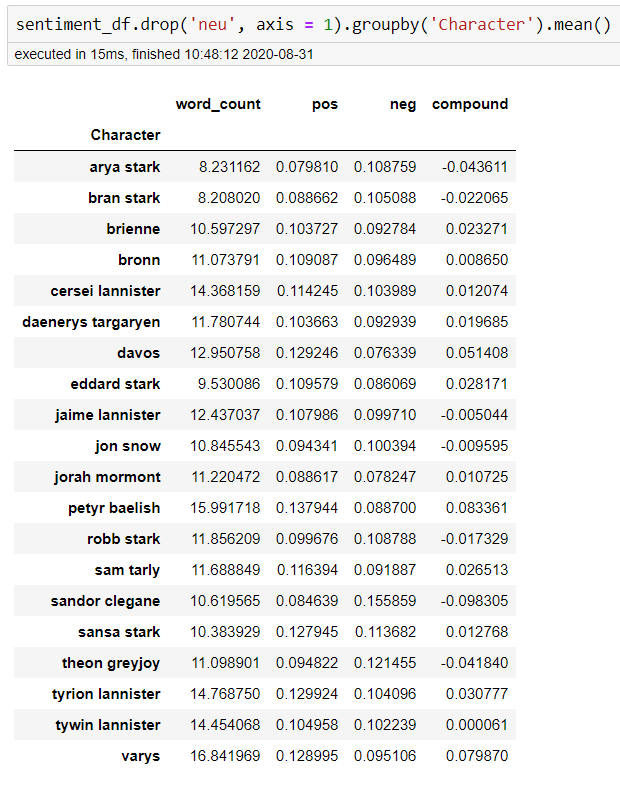
Sentiment aside, we saw that some characters, on average, had much more to say when they did speak than others. Both Varys and Petyr Baelish seemed to average more words than anyone else when they spoke, and they also seemed to average more positive words than others. This is based off of the average compound score, where 1 is extremely positive, and -1 is extremely negative. While everyone seems to average out very close to neutral, the two of them had the highest avg score indicating more positive dialogue overall. As for negativity, it seems that Sandor Clegane is our most negative character. What was also interesting was that Tywin Lannister appears to be almost perfectly neutral through the sentiment analysis. Broken down by season, we can also see some trends to confirm some of this.
除了情感,我们发现某些人物说话时平均要说的比其他人多得多。 Varys和Petyr Baelish说话时的平均话语似乎比其他任何人都多,而且似乎也比其他人平均的话多。 这是基于平均复合得分得出的,其中1表示正,-1表示负。 尽管每个人的平均得分似乎都非常接近中立,但他们两个的平均得分最高,表明总体上对话更为积极。 至于消极情绪,似乎桑多·克莱根(Sandor Clegane)是我们最负面的角色。 同样有趣的是,通过情感分析,泰温·兰尼斯特似乎几乎完全是中立的。 按季节细分,我们还可以看到一些趋势来确认其中的一些。
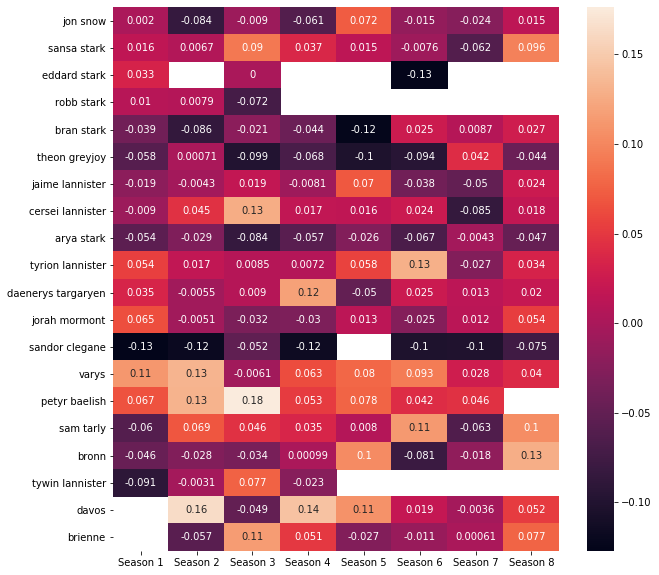
Note that the empty spaces indicate the character was not present that season, most likely due to being killed off.
请注意,空白处表示角色在那个季节不存在,很可能是由于被杀死。
Another thing to keep in mind is that this analysis is based upon a pre-trained sentiment model. I feel this may be in the ballpark, but still have reservations upon it’s validity based on specific examples like below.
要记住的另一件事是,该分析基于预先训练的情感模型。 我认为这可能是在球场上,但是根据下面的具体示例,它仍然会有所保留。

I personally think it’s somewhat debatable as to if this is actually a mostly positive sentiment and can be argued that this should probably be much more negative.
我个人认为这是否实际上是一种积极的看法尚有争议,可以说这可能是消极的。
造型 (Modeling)
Our initial goal was to attempt to classify which character is speaking. To start I created a language model based upon the ULMFiT method using all of the available dialogue. What I then tried was to separate out Season 8 and train our model upon the remaining 7 seasons. From here, I would have to then reduce our characters to only those that survived all the way to Season 8. Further filtering to only characters that had at least 300 lines to train with, reduced our classes from over 500 to 16. The character classifier wasn’t the best, achieving just shy of 25% overall accuracy.
我们最初的目标是尝试对说话的角色进行分类。 首先,我使用所有可用的对话框,根据ULMFiT方法创建了一个语言模型。 然后,我试图分离出第8季,并在剩下的7季中训练我们的模型。 从这里开始,我将不得不将字符减少到仅在第8季中一直存在的那些字符。进一步过滤到仅具有至少300行要训练的字符,将我们的类从500多个减少到16个。并不是最好的,总体准确率只有25%。
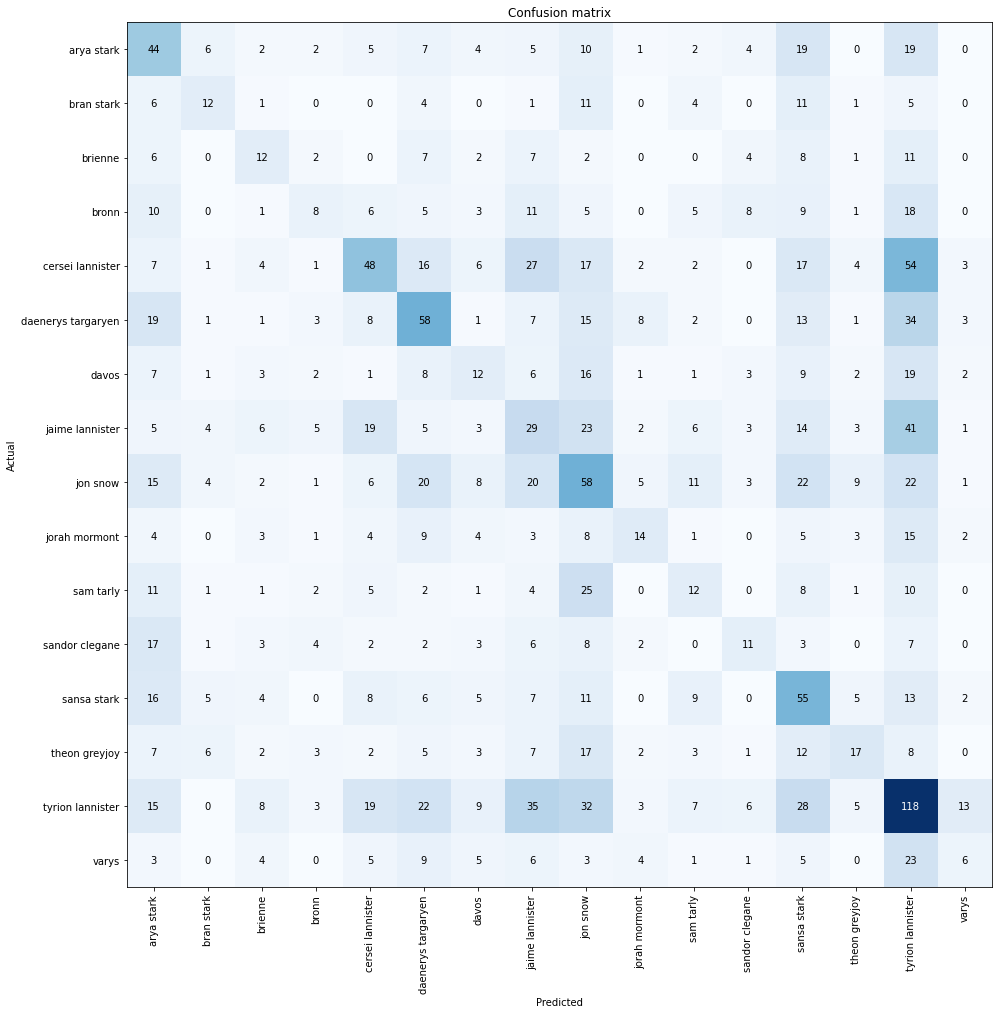
It did seem that Lannisters and Starks had higher probability of accuracte classification which would lead to my next modeling attempt at classifying dialogue by family.
Lannisters和Starks似乎确实有较高的准确度分类可能性,这将导致我下一次建模尝试按家庭分类对话。
Classifying by family did provide a signiciant improvement to 50% overall accuracy.
按家族分类确实使整体准确度提高了50%。
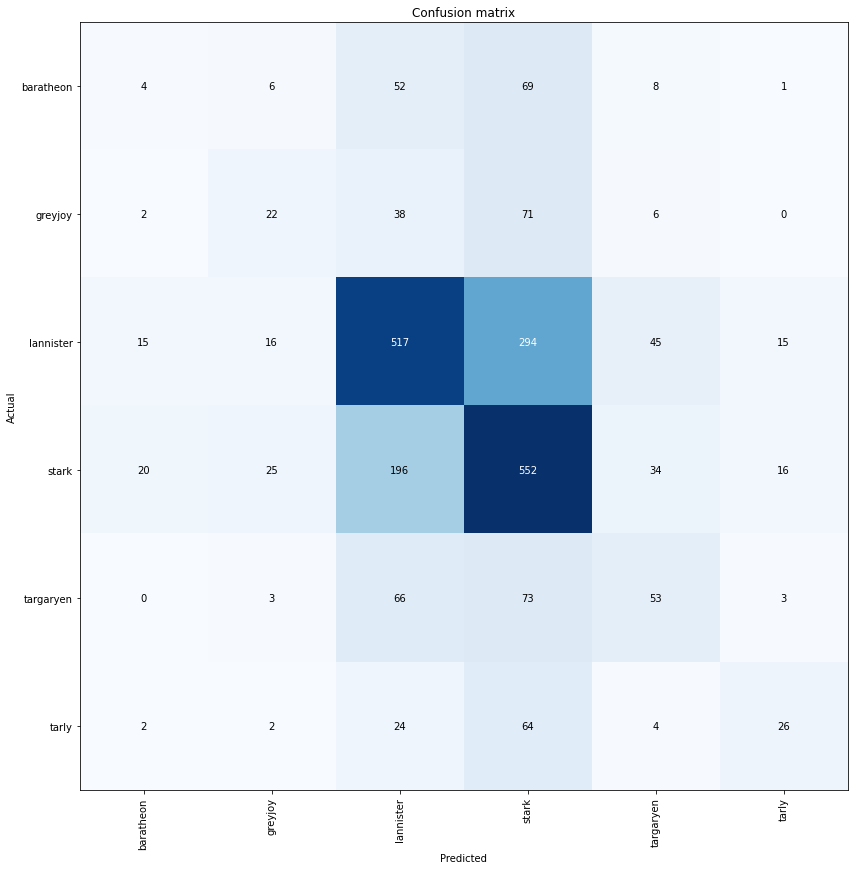
An interesting takeaway from this plot is the likelihood of classification for both Greyjoys and Tarlys. Both of these key characters spent close proximity with the Starks and both have significantly higher probabilities of being mis-classified as a Stark as opposed to any other family.
该图的一个有趣之处在于,对Greyjoys和Tarlys进行分类的可能性。 这两个关键人物都与Starks十分接近,而且与其他家族相比,被误认为Stark的可能性要高得多。
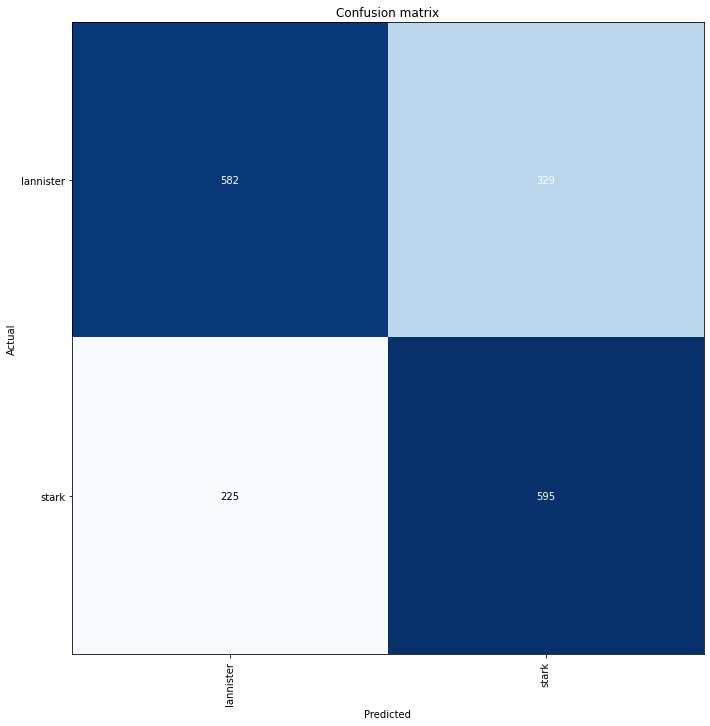
Finally, we’ll look at only classifying Starks and Lannisters. Further reducing our classes to a binary problem provides us with an overall accuracy of around 68%.
最后,我们将仅对Starks和Lannisters进行分类。 进一步将类简化为二进制问题,可以为我们提供68%左右的整体准确性。
结论 (Conclusion)
Individual character classification proved to be a more complex problem than initially thought; primarily due to the amount of data needed in order to be able to accurately classify a character and realistically only having data to properly identify maybe 2 of the over 500 unique characters in the show. Attempting classification by house and last name did provide better results and does leave some room for improvement as this will most likely be the best method of speech classification. In terms of our sentiment analysis, it does seem to be somewhat believable in its results. However, a healthy amount of skepticism should be used as it was obtained via a pre-trained model and unable to be retrained on the data in its current state without manually classifying script dialogue sentiment myself. As a fan of the show, Tyrion was always an enjoyable character. After this investigation though, it surprises me how heavily he was relied upon to carry the series. While assuming he’d have a significant percentage of the dialogue, I was surprised at just how much in numerous instances.
事实证明,单个字符分类比最初认为的要复杂得多。 主要是由于要能够准确地对角色进行分类所需的数据量,而实际上只有数据才能正确识别节目中500多个独特角色中的2个。 尝试通过房屋和姓氏进行分类确实提供了更好的结果,并且确实留有一些改进的余地,因为这很可能是语音分类的最佳方法。 就我们的情绪分析而言,其结果似乎确实令人信服。 但是,应该使用一种健康的怀疑态度,因为它是通过预先训练的模型获得的,并且如果不对自己的脚本对话情绪进行手动分类,就无法对其当前状态的数据进行重新训练。 作为节目的粉丝,提利昂一直是一个愉快的角色。 经过这次调查之后,令我惊讶的是他被如此多地依靠来进行系列赛。 假设他会在对话中占很大比例,但我惊讶于无数情况。
应聘对白

















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









