




 本文介绍了CUDA设备的存储结构,包括寄存器、共享内存、全局存储器、常量存储和L2缓存。重点讨论了寄存器和共享内存的高速访问特性,以及它们在CUDA程序优化中的重要性。线程块内的线程通过共享内存进行高效数据交换,而寄存器则用于保存线程私有的高频访问变量。理解这些存储设备的差异对于实现高效的CUDA计算至关重要。
本文介绍了CUDA设备的存储结构,包括寄存器、共享内存、全局存储器、常量存储和L2缓存。重点讨论了寄存器和共享内存的高速访问特性,以及它们在CUDA程序优化中的重要性。线程块内的线程通过共享内存进行高效数据交换,而寄存器则用于保存线程私有的高频访问变量。理解这些存储设备的差异对于实现高效的CUDA计算至关重要。
首先回顾一下Nvidia GPU的硬件结构:
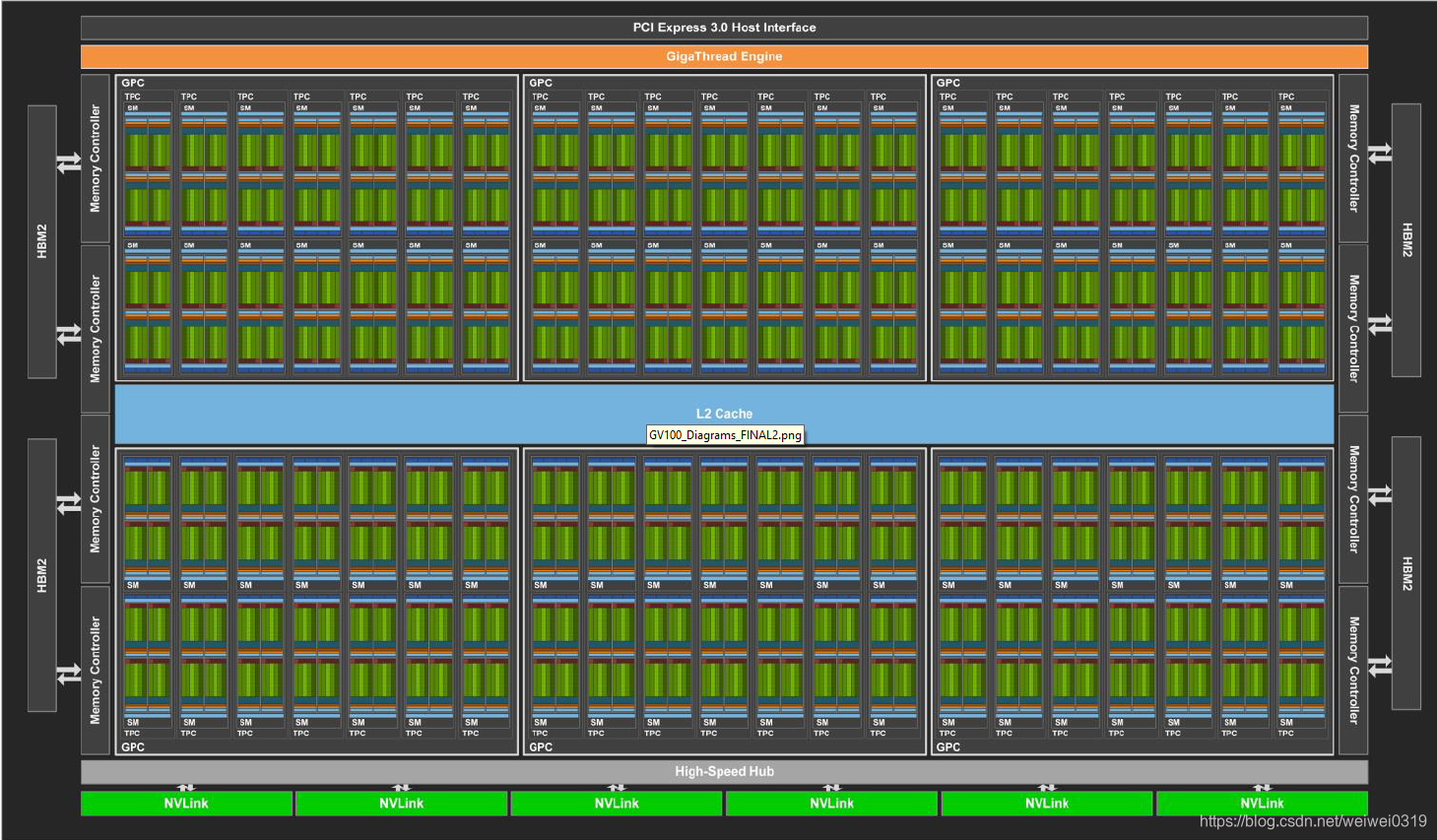
上图是Volta GV100的GPU结构全图,这我们只关注存储设备,可以看到所有的SM共享L2 Cache和全局存储器(通常说的显存),另外还有一个常数存储器也是所有SM共享的。
再看单个的SM的硬件结构:
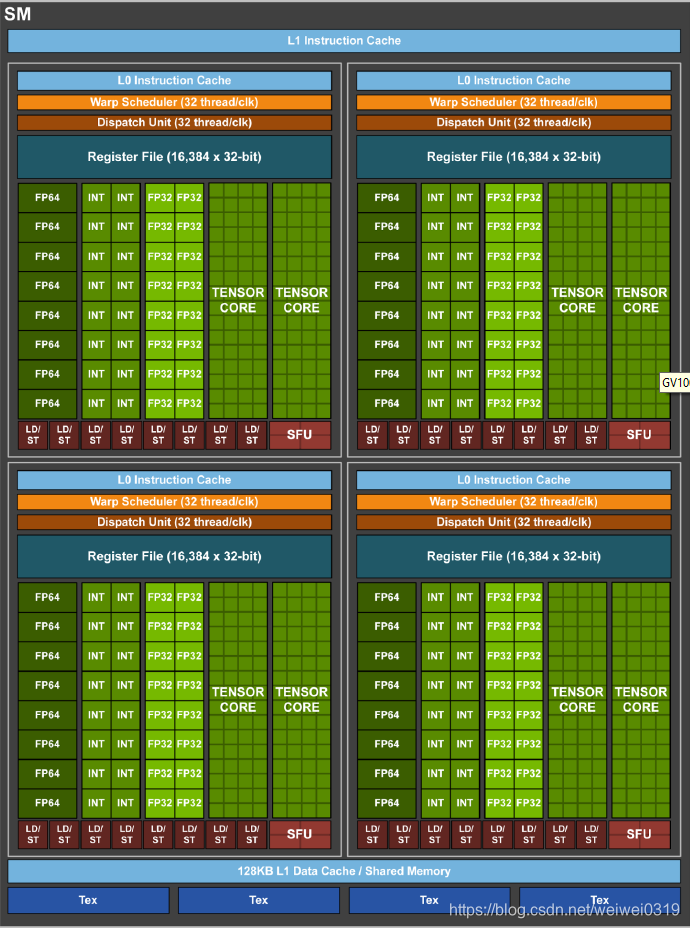
很明显,每个SM共享L1 Data和共享内存。另外每个CUDA Core拥有自己的寄存器(Register File)。
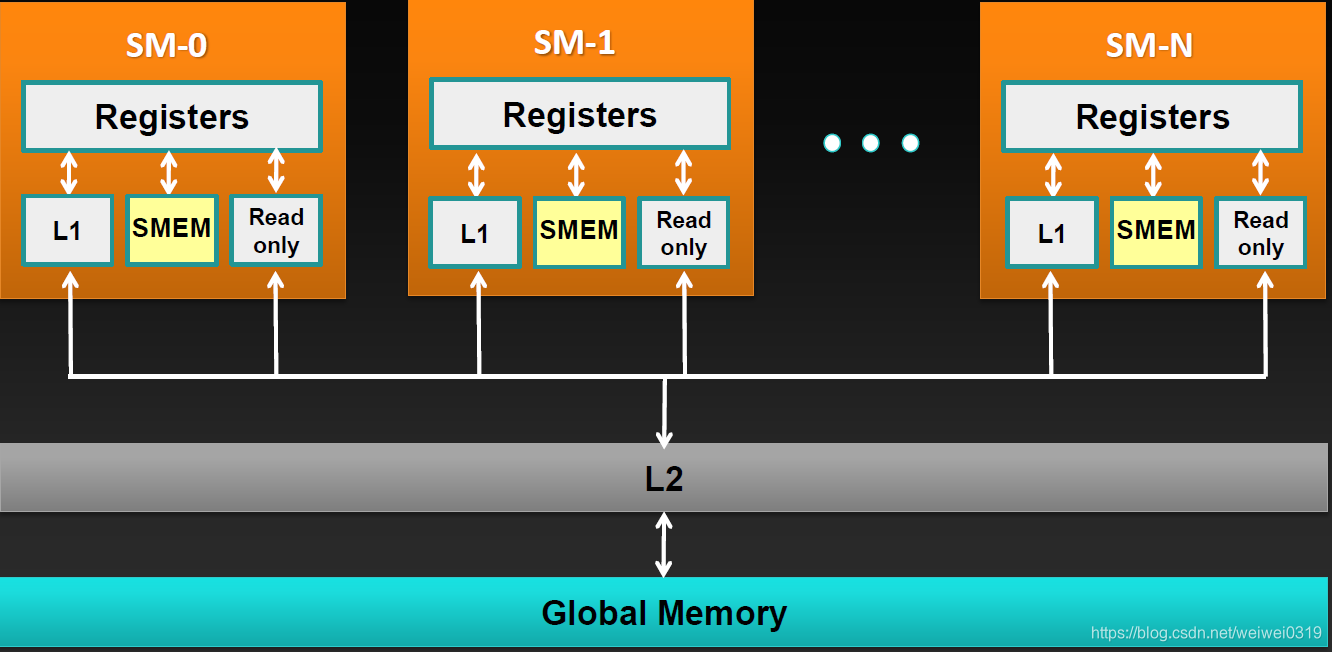
访问速度越靠近CUDA Core,访问速度越快,性能优化要做的就是访问全局内存少些,访问共享内存或者寄存器多些。
kernel在被调起时,按照线程块分配给SM,所以每个SM的共享内存实际上是给线程块共享的,即一个线程块中的所有线程共享同一个共享内存,可以基于此,线程块中的线程可以使用共享内存交换数据,是效率比较高的一种做法。
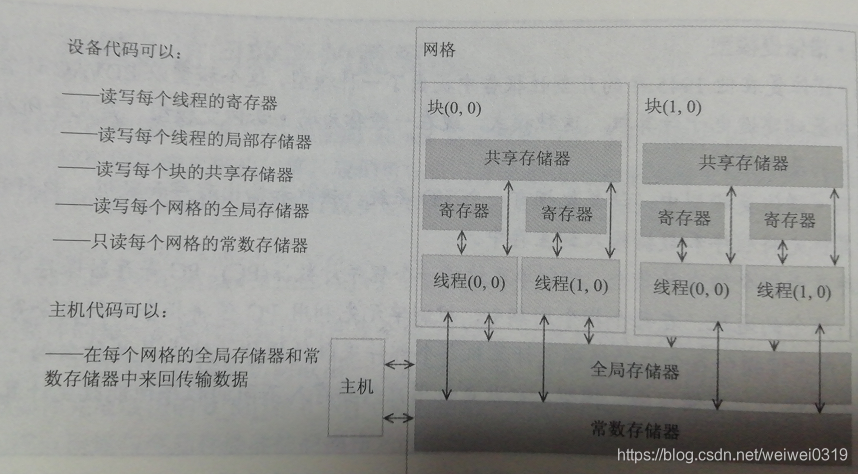
寄存器和共享存储器是片上存储器,具有高带宽,低延迟特点。驻留在这两种存储器中的变量可以以高度并行的方式高速访问。寄存器被分配给每个线程,而每个线程只能访问分配给自己的寄存器。kernel函数经常用寄存器保存那些需要频繁访问的变量,这些变量是每个线程私有的。
共享存储器分配给线程块,同一个块中的所有线程都可以访问共享存储器中的变量,如果是同一个变量,那么需要做好线程同步。共享存储器是一种用于线程协作的高效方式,方法是共享其中的输入数据和其中的中间结果。在声明CUDA变量时,通过对CUDA存储器类型的选择,可以指定对应变量的可见性和访速度。
虽然CUDA设备中的共享存储器和寄存器都是片上存储器,相对全局存储器具有更高的带宽和耕地的延迟,但是他们之间在功能和访问成本上有很大的差异。当处理器访问共享存储器时,存储器需要执行内存加载操作,与访问全局存储器一样,由于共享存储器在芯片上,访问共享存储器比访问全局存储器有更低的延迟和更高的带宽。但是又由于需要执行内存加载操作,共享存储器比寄存器有较长的延迟和较低的带宽。
程序中的变量声明成不同类型的存储器CUDA语法如下:

- 自动变量 : 所有在kernel函数和设备函数中声明的自动标量变量,都存在寄存器中。每个线程都会创建变量的一个私有版本;每个线程只能访问变量的私有版本。如果kernel函数中声明一个单个线程作用域的变量,当使用100万个线程启动kernel函数时,就会创建该变量的100万个私有版本。当线程终止时,线程中的所有自动变量也不再存在。
- 自动数组变量:自动数组变量并不存寄存器中,相反,他们存储在全局存储器中。但他们的作用域仅限于单个线程。每个线程为每一个自动数组变量创建一个私有版本并使用它,他们全部存储在全局存储器中,一旦该线程终止,该自动数组变量也不再存在。
- 共享变量 :一个块中的所有线程看到的是一个共享变量的同一个版本。在执行kernel函数时,为每个块创建共享变量的一个私有版本并能使用它。当kernel函数终止时,其中的共享变量的内容也不再存在。
- 常量:常量的声明必须位于任何函数体外,所有网格中的所有线程看到的时常数变量的同一个版本。在整个应用程序执行期间一直存在。常数存储器访问速度非常快,但大小有很大的限制。
- 设备变量(__device__):全局变量,存放在全局存储器中,对于kernel函数的所有线程均可见。在整个应用程序执行期间一直存在。
总结一下,对于一块GPU设备,具有以下存储设备:
- 寄存器
存储每个线程的临时局部变量,由编译器管理
- 共享存储/L1 缓存
设备不同,容量不同,并且容量有限
程序可控制,程序中可以直接指定数据在共享存储器中
同一个线程块中的所有线程可以同时访问
低延迟,高带宽:~2.5 TB/s
- 只读缓存:
容量很小
常量存储
- L2 缓存
容量比共享存储器大,可以达到MB单位
所有线程共享
硬件控制,访问全局存储器数据时,需要先将数据加载到L2缓存
- 全局存储器
容量较大,可以达到GB单位
所有线程共享,主机CPU,同系统下的另外GPU均可访问
高延迟(400-800 时钟周期)
低带宽 250GB/s


















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









