




 AlphaZero是一种通用强化学习算法,它通过自我对弈在国际象棋、日本将棋和围棋中取得卓越表现。该算法结合了深度神经网络和蒙特卡洛树搜索(MCTS),在没有专家数据的情况下自我进化。经过短短几小时的训练,AlphaZero就能超越专业棋类程序。其网络结构基于Resnet,并使用MCTS的UCB算法进行高效的搜索。
AlphaZero是一种通用强化学习算法,它通过自我对弈在国际象棋、日本将棋和围棋中取得卓越表现。该算法结合了深度神经网络和蒙特卡洛树搜索(MCTS),在没有专家数据的情况下自我进化。经过短短几小时的训练,AlphaZero就能超越专业棋类程序。其网络结构基于Resnet,并使用MCTS的UCB算法进行高效的搜索。
文章目录
题目:A general reinforcement learning algorithm that masters chess, shogi and Go through self-play
1.概述
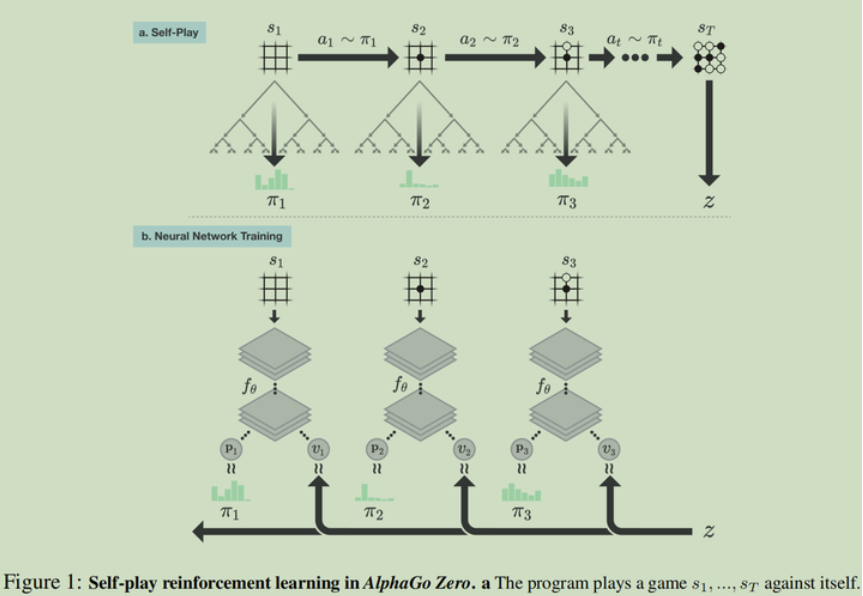
该论文是在alphaGO和alpha GO zero基础上提出,在不需要专家数据的前提下采用self-play的方式进行训练,在各类棋类游戏得到的强大性能!
- 在国际象棋中,AlphaZero训练4小时就超越了世界冠军程序Stockfish;
- 在日本将棋中,AlphaZero训练2小时就超越了世界冠军程序Elmo。
- 在围棋中,AlphaZero训练30小时就超越了与李世石对战的AlphaGo。
看具体算法还是看AlphaGo Zero:Mastering the game of Go without human knowledge
2.主要内容
AlphaGo Zero = 启发式搜索 + 强化学习 + 深度神经网络,你中有我,我中有你,互相对抗,不断自我进化。使用深度神经网络的训练作为策略改善,蒙特卡洛搜索树作为策略评价的强化学习算法。
2.1 网络部分
alpha zero的CNN架构其实就是Resnet的堆叠,值得注意是它的输入和输出:
使用的是一个19×19×17
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 240
240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









