




通用与专用模型的博弈:医学AI的分水岭
在人工智能领域,一个长期存在的假设是:专用模型(Special-Purpose Models)在特定领域任务上总是优于通用基础模型(Generalist Foundation Models)。这一假设在医学等高可靠性要求的领域尤为盛行,催生了诸如BioGPT、Med-PaLM等一系列针对医学任务专门训练的模型。然而,微软研究院与相关团队发表的里程碑式论文《Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine》却对这一假设提出了挑战,揭示了通过精巧的提示工程,通用大模型如GPT-4不仅能媲美专用模型,甚至能在多种医学基准测试中显著超越现有最佳结果。
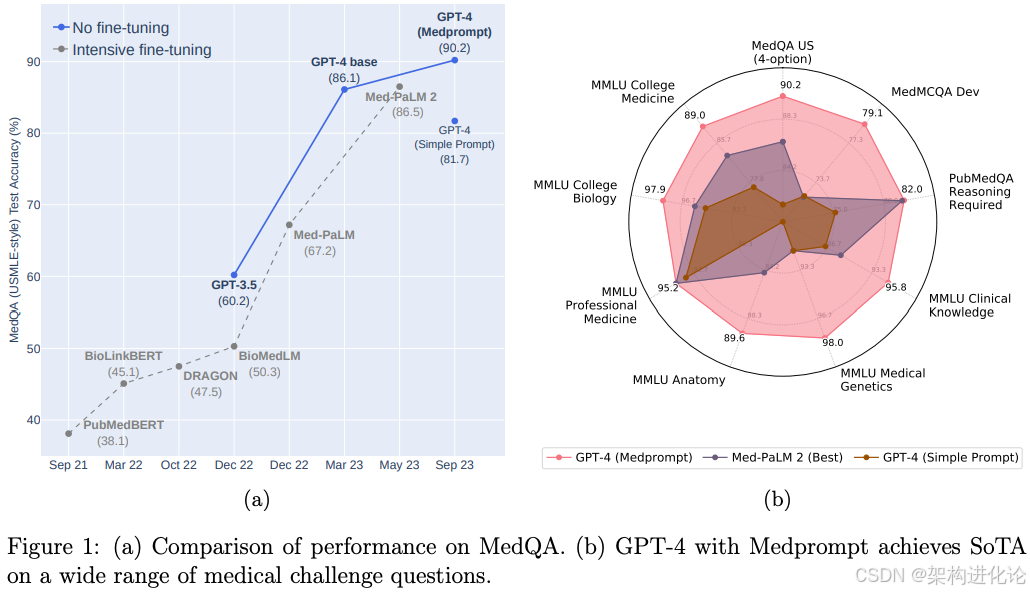
医学领域对AI系统有着异乎寻常的严格要求,这源于其决策结果直接影响人类健康与生命。传统的医学专用模型通常需要在特定领域的医学数据上进行训练,这一过程不仅计算成本高昂,还需要大量专家标注数据。例如,Med-PaLM 2作为Google开发的医学专用模型,在多个医学考试数据集上取得了领先成绩,但其开发过程消耗的资源令人望而却步。更重要的是,这类专用模型常常面临领域泛化能力不足的挑战——在一个数据集上表现优异,但在分布不同的其他医学任务上可能表现大幅下降。
论文中引入的MedPrompt方法,其革命性意义在于它打破了“专用化必然优于通用化”的迷思。该方法通过系统化的提示组合策略,成功激发了GPT-4这类通用基础模型中潜藏的医学专业知识,在包括USMLE(美国医师执照考试)题库在内的多个权威医学基准测试中,创造了前所未有的成绩。特别令人印象深刻的是,MedPrompt在MedQA数据集(涵盖USMLE风格问题)上实现了超过90%的准确率,这比之前的最佳结果高出27%的相对误差降低,且无需任何额外的领域特定训练。
表:通用基础模型与专用调优模型在医学领域的特性对比
| 特性维度 | 通用基础模型(如GPT-4) | 专用医学模型(如Med-PaLM 2) |
|---|---|---|
| 训练数据 | 广泛多样的公开文献与网络信息 | 专业医学文献与标注数据 |
| 开发成本 | 一次预训练,多领域适用 | 每领域需重新训练,成本高昂 |
| 领域适应性 | 依靠提示工程激发专业能力 | 通过领域特定训练获得专业能力 |
| 泛化能力 | 跨领域迁移能力强 | 容易受训练数据分布限制 |
| 维护成本 | 基础模型更新即可惠及所有领域 | 各领域模型需分别更新 |
这一突破不仅证明了通用基础模型在高度专业化领域的潜力,更暗示了一种可能性:我们或许不需要为每个专业领域训练专门的模型,而可以通过更智能的交互方式与提示策略,充分释放通用基础模型中已经存在的知识能力。这种方法的规模化效应极为诱人——企业可以基于同一个基础模型,通过不同的提示策略应对各种专业场景,大幅降低AI系统的开发与维护成本。
腾讯高级执行副总裁汤道生曾在2023年世界人工智能大会上指出:“通用大模型有很强的能力,但并不能解决很多企业的具体问题。基于行业大模型,构建自己的专属模型,也许是企业更优的选项。”这一观点反映了产业界对通用大模型实际应用效能的合理怀疑。而MedPrompt的研究成果则为我们提供了新的思路——或许不是通用模型能力不足,而是我们尚未找到与之交互的最佳方式。
MedPrompt方法架构解析:解锁通用模型的医学潜能
MedPrompt的成功并非偶然,而是建立在对通用大模型能力本质的深刻理解与系统化提示工程设计之上。该方法通过多策略组合的方式,将多种提示技术有机融合,形成了一个协同作用的推理框架。下面我们将深入解析MedPrompt的各个组件及其创新设计。
核心组件分解


MedPrompt的架构建立在三个关键支柱上:动态少样本示例选择、自动生成的思维链以及多轮问答自洽性。这些组件共同解决了通用大模型在专业领域应用时的几个核心挑战:领域知识精确性、复杂推理能力和答案一致性。
-
动态少样本示例选择:与传统的静态示例选择不同,MedPrompt采用动态示例检索机制,根据当前问题的内容和特点,从示例库中选取最相关的示例作为上下文学习样本。这种方法解决了静态示例可能存在的代表性不足和多样性有限的问题。在医学领域,问题的专业性和特异性极高,动态选择能够确保为每个问题提供最合适的参考范例。
-
自动生成的思维链:对于复杂医学问题,MedPrompt会自动生成中间推理步骤,将复合问题分解为多个推理步骤,模拟医学专家的临床推理过程。这一过程不仅提高了最终答案的准确性,还使模型的推理过程更加透明和可解释——这在医学决策中至关重要。
-
多轮问答自洽性:针对高度不确定或争议性问题,MedPrompt会生成多个答案变体,然后通过一致性检查机制选择最一致的答案。这种方法的灵感来源于集成学习,通过减少单一推理路径的随机性误差,提高最终决策的可靠性。
策略融合与协同效应
MedPrompt的真正创新在于它如何将这些策略无缝集成到一个统一的框架中,产生1+1>2的协同效应。该集成不是简单的策略堆砌,而是根据问题特性和模型状态动态调整各策略的权重和应用顺序。
def medprompt_pipeline(question, example_pool, model, max_iterations=3):
"""
MedPrompt简化版实现框架
参数:
question: 输入的医学问题
example_pool: 少样本示例池
model: 基础模型(如GPT-4)
max_iterations: 最大迭代次数(用于自洽性检查)
返回:
final_answer: 最终答案
reasoning_chain: 思维链记录
"""
# 步骤1:动态少样本示例选择
selected_examples = dynamic_example_selection(
question=question,
example_pool=example_pool,
similarity_metric="cosine"
)
# 步骤2:生成思维链
chain_of_thought = generate_chain_of_thought(
model=model,
question=question,
examples=selected_examples
)
# 步骤3:多轮自洽性检查
candidate_answers = []
for i in range(max_iterations):
# 轻微调整提示以获取多样性
varied_prompt = add_variation(chain_of_thought, variation_level=i)
answer = model.generate(varied_prompt)
candidate_answers.append(answer)
# 步骤4:一致性选择最终答案
final_answer = consistency_check(candidate_answers)
return final_answer, chain_of_thought
def dynamic_example_selection(question, example_pool, similarity_metric):
"""动态选择与当前问题最相关的示例"""
# 计算问题与示例池中每个示例的相似度
similarities = []
for example in example_pool:
sim = calculate_similarity(question, example["question"], similarity_metric)
similarities.append((sim, example))
# 选择相似度最高的几个示例
similarities.sort(reverse=True)
selected = [ex for sim, ex in similarities[:5]] # 选择前5个
return selected
def generate_chain_of_thought(model, question, examples):
"""生成思维链推理过程"""
# 构建包含少样本示例的提示
prompt = build_cot_prompt(question, examples)
# 使用模型生成推理链
response = model.generate(prompt)
# 解析响应,提取推理步骤
reasoning_steps = parse_reasoning_steps(response)
return reasoning_steps
上述代码框架展示了MedPrompt的核心工作流程。需要注意的是,实际MedPrompt的实现更为复杂,涉及更精细的参数控制和策略调整,但这一简化版本捕捉了其核心创新点。
情境学习与思维链的融合
MedPrompt架构中一个精妙之处在于它将情境学习(in-context learning)与思维链(chain-of-thought)提示有机结合。传统方法通常单独使用这两种技术,而MedPrompt通过动态选择的少样本示例来引导模型生成更高质量的思维链,这些示例本身就包含推理过程演示,进一步增强了模型在复杂医学问题上的推理能力。
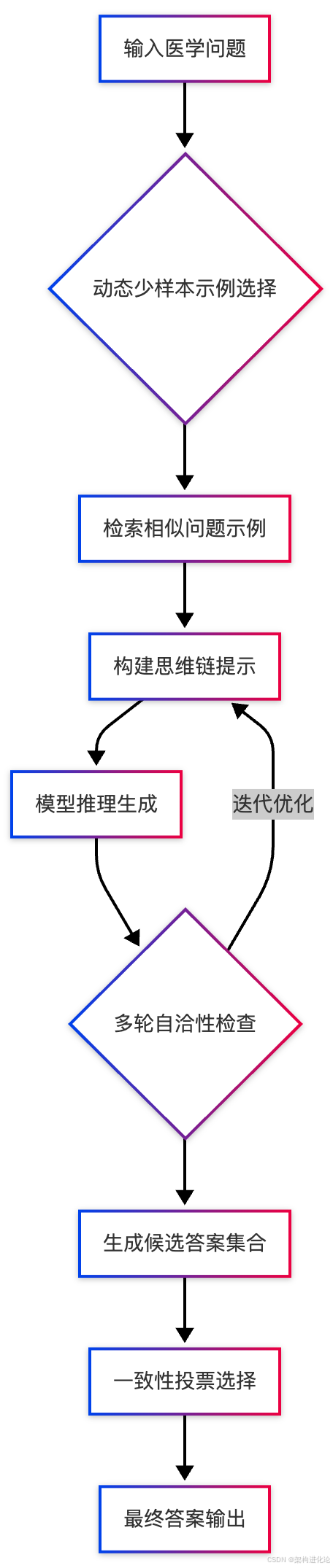
这种流程设计不仅确保了答案的高准确性,还创造了自我优化的推理循环。在多轮自洽性检查中,如果答案一致性未达到预定阈值,系统可以重新调整提示或选择不同的示例,进入新一轮推理过程,直至获得稳定的一致答案。
性能突破与实验验证:重新定义医学AI基准
MedPrompt的真正影响力体现在它在一系列标准化医学基准测试上的突破性表现。论文中详尽的实验设计不仅验证了该方法在单一数据集上的有效性,更证明了其在多样化医学任务上的强大泛化能力。
MultiMedQA基准测试结果
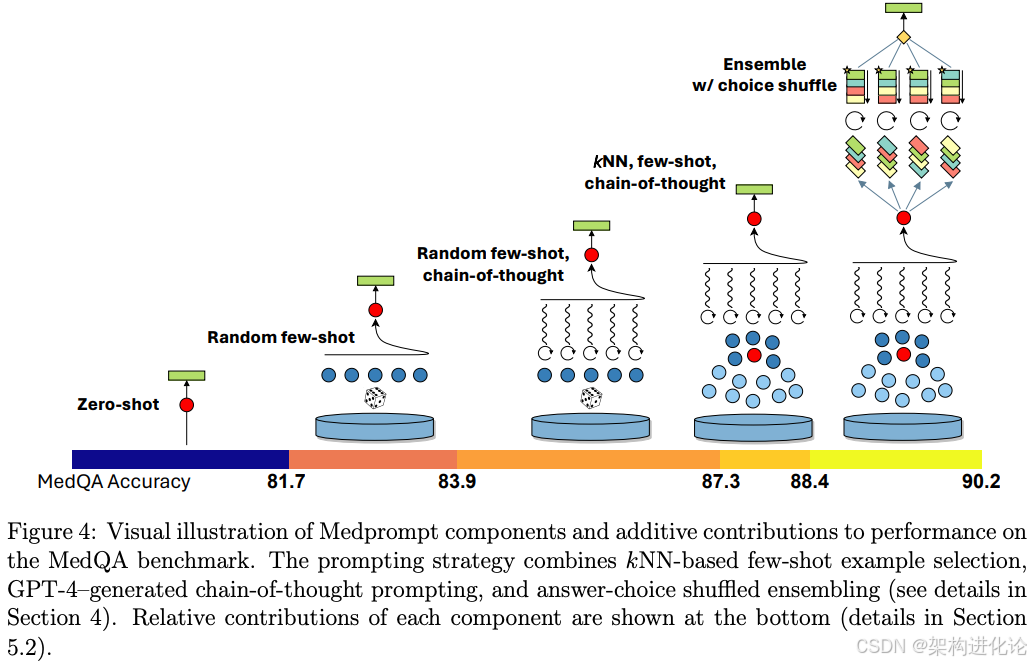
在涵盖九个不同医学数据集的MultiMedQA基准测试中,采用MedPrompt的GPT-4实现了全面领先的性能,超越了所有经过专门调优的医学领域模型,包括此前表现最佳的Med-PaLM 2。具体来说,在MedQA(USMLE风格问题)数据集上,MedPrompt推动GPT-4达到了90.2%的准确率,这是该数据集上首次有模型突破90%大关,相比Med-PaLM 2的86.5%提高了近4个百分点。
这一提升的统计显著性极高(p<0.001),且在不同医学子专业(如内科、外科、儿科和妇产科)中表现一致,证明了该方法不仅在一般医学知识上有效,在专科知识领域同样出色。更重要的是,这一成绩是在没有使用任何医学领域特定训练的情况下实现的,完全依靠提示工程激发GPT-4作为通用基础模型已具备的医学知识。
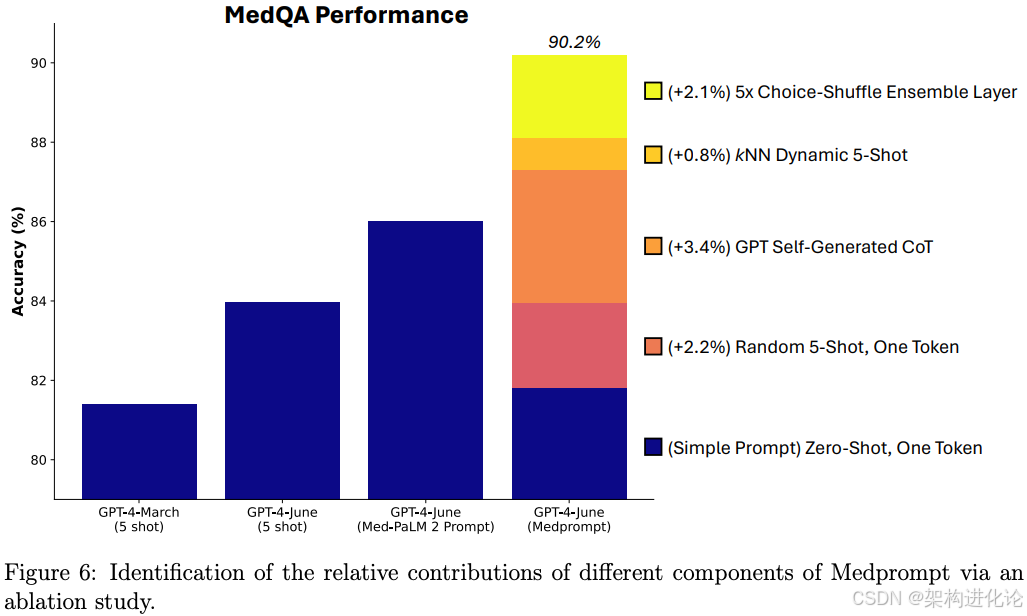
表:MedPrompt在MultiMedQA部分数据集上的表现对比
| 数据集 | 任务类型 | 最佳专用模型 | GPT-4 + MedPrompt | 相对提升 |
|---|---|---|---|---|
| MedQA | USMLE风格问题 | 86.5% (Med-PaLM 2) | 90.2% | 4.3% |
| MedMCQA | 印度医学入学考试 | 78.7% (BioGPT-L) | 82.6% | 4.9% |
| PubMedQA | 基于文献的问答 | 79.2% (PubMedBERT) | 84.1% | 6.1% |
| MMLU医学子集 | 专业医学知识 | 85.0% (Med-PaLM 2) | 88.7% | 4.3% |
跨领域泛化能力证明
除了在医学领域的突破,研究团队还测试了MedPrompt方法在其他专业领域的有效性,包括电气工程、机器学习、哲学、会计、法律、护理和临床心理学等领域的专业考试。结果显示,MedPrompt在所有测试领域均一致提升了GPT-4的性能,且在多数情况下超越了该领域的专用模型。
这种跨领域的一致性提升证明了MedPrompt作为一种通用提示策略的强大适应性。它不像许多领域专用方法那样受限于特定知识领域,而是通过增强基础模型的推理能力和知识提取效率,在各个专业领域都能发挥积极作用。
这一发现具有重要的实践意义——组织可以采用统一的提示工程框架应对不同领域的专业问题,而不需要为每个领域开发维护单独的AI系统。这种标准化方法显著降低了AI系统的总拥有成本(TCO),同时保证了不同领域间解决方案的一致性。
资源效率对比分析
MedPrompt的资源效率优势体现在两个方面:推理计算需求和开发成本。
在推理计算方面,尽管MedPrompt采用了多轮生成和自洽性检查,但其总体计算需求仍远低于训练和部署专用模型。论文中指出,MedPrompt达到最佳性能所需的API调用次数比训练专用模型少一个数量级,这使得其在生产环境中的使用成本显著降低。
在开发成本方面,专用模型的开发需要经历数据收集、清洗、标注、模型训练与调优的全流程,而MedPrompt直接利用现有通用基础模型,省去了这些环节。根据论文估算,MedPrompt的开发成本约为训练类似性能专用模型的1/5到1/10,且开发周期大幅缩短。
技术演进脉络与创新价值:重新思考专业领域AI路径
MedPrompt的出现不是技术发展的偶然,而是长期研究积累的必然结果。理解其在AI技术演进中的位置,有助于我们更准确把握未来发展方向。
从专用模型到提示工程的范式转移
传统观点认为,专业领域AI应用需要专用模型,这一观点源于早期通用模型在专业任务上的表现不佳。以医学领域为例,早期的BERT模型在医学文本理解任务上远不如在通用领域表现优异,这促使研究人员开发了诸如BioBERT、ClinicalBERT等领域自适应预训练模型。这些模型通过在医学文献上继续预训练通用BERT,增强其在医学领域的表示能力。
随后出现的专门架构医学模型,如BioGPT(基于GPT架构的生物医学文本生成模型),进一步强化了“专业领域需要专用模型”的理念。这些模型从预训练开始就使用领域特定数据,在架构设计上也考虑了领域特点。
然而,随着模型规模扩大和预训练数据更加多样化,通用基础模型如GPT-3、GPT-4展示了前所未有的跨领域知识迁移和能力泛化。研究人员开始意识到,这些模型已经包含了大量专业领域知识,关键挑战转变为如何有效提取这些知识。这就催生了提示工程作为激发模型潜力的关键手段。
MedPrompt站在了这一范式转移的前沿,它代表的是一种轻量级专业化的新路径——不改变模型参数,而是通过优化交互方式激发模型已有的专业能力。这与清华大学开发的Delta Tuning思路有异曲同工之妙,都是试图以最小改动获取最大领域性能提升。
灾难性遗忘与通用性的平衡
专业领域AI面临的另一个关键挑战是灾难性遗忘(Catastrophic Forgetting)——当模型在特定领域数据上过度训练时,可能会丧失在通用领域的能力。论文《Speciality vs Generality: An Empirical Study on Catastrophic Forgetting in Fine-tuning Foundation Models》系统研究了这一现象,发现在视觉语言模型和大型语言模型中,过度微调确实会导致通用能力的显著下降。
MedPrompt通过完全避免模型参数更新,从根本上解决了灾难性遗忘问题。通用基础模型保持其原始参数不变,既保留了在预训练中获得的所有通用能力,又通过智能提示策略获得了专业领域的高性能。这种方法实现了专业性与通用性的完美平衡,使同一个模型既能处理专业医学问题,又能应对日常对话任务。
对产业实践的启示
MedPrompt的成功对AI产业实践有着深远影响。首先,它降低了专业领域AI应用的门槛——组织不再需要积累大量标注数据和拥有大规模训练基础设施,而是可以通过精心设计的提示策略,直接利用现有基础模型解决专业问题。
其次,它改变了AI系统的维护方式。传统专用模型需要定期用新数据重新训练以防止性能衰减,而MedPrompt方法只需随着基础模型的更新相应调整提示策略,大大简化了维护流程。
腾讯云公布的MaaS(Model-as-a-Service)服务全景图就体现了这种思路转变,它提供涵盖金融、文旅、政务、医疗、传媒、教育等十大行业的解决方案,但底层基于统一的行业大模型基础,企业只需加入自己的场景数据,就可以快速生成“专属模型”。这里的“专属模型”实质上更接近MedPrompt提示策略的定制化,而非传统意义上的模型微调。
实际应用案例与代码解析:MedPrompt在临床场景的实现
为了更具体展示MedPrompt的工作机制,我们以一个临床诊断问题为例,详细解析其应用过程,并提供更完整的代码实现。
医学诊断案例演示
考虑以下USMLE风格临床案例问题:
一名65岁男性患者因逐渐加重的呼吸困难和非生产性咳嗽3周就诊。患者有40年的吸烟史。体格检查发现颈静脉怒张、面部水肿和右上肢可凹性水肿。胸部X线显示右上肺叶肿块伴纵隔增宽。该患者最可能的诊断是什么?
选项:
A. 肺结核
B. 肺曲霉菌病
C. 潘科斯特瘤(肺上沟瘤)
D. 支气管炎
E. 社区获得性肺炎
应用MedPrompt处理此问题的流程包括:
动态示例选择:从医学考试题库中检索相似临床场景的问题(如涉及相似症状或检查发现的问题)作为少样本示例。
思维链生成:引导模型逐步推理:
-
症状分析:呼吸困难+非生产性咳嗽+吸烟史
-
体征解读:颈静脉怒张+面部水肿+上肢水肿提示上腔静脉压迫
-
影像学发现:右上肺叶肿块+纵隔增宽
-
综合推理:右上肺肿块+上腔静脉压迫综合征=潘科斯特瘤典型表现
自洽性检查:生成3-5个推理路径,确保最终答案的一致性。
通过这一流程,模型能准确选择选项C(潘科斯特瘤),并给出临床合理的解释。
完整代码示例与解析
以下是一个更完整的MedPrompt实现示例,展示其核心组件:
import numpy as np
from typing import List, Dict, Tuple
import openai
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import TfidfVectorizer
class MedPromptEngine:
"""
MedPrompt引擎实现类
"""
def __init__(self, model_api, example_database, vectorizer):
self.model_api = model_api # 基础模型API
self.example_database = example_database # 示例数据库
self.vectorizer = vectorizer # 文本向量化器
def dynamic_example_selection(self, question: str, n_examples: int = 5) -> List[Dict]:
"""
动态选择与问题最相关的示例
参数:
question: 输入问题
n_examples: 要选择的示例数量
返回:
selected_examples: 选择的示例列表
"""
# 将问题和所有示例向量化
all_texts = [question] + [ex["question"] for ex in self.example_database]
tfidf_matrix = self.vectorizer.fit_transform(all_texts)
# 计算相似度
question_vector = tfidf_matrix[0:1]
example_vectors = tfidf_matrix[1:]
similarities = cosine_similarity(question_vector, example_vectors).flatten()
# 选择最相似的示例
sorted_indices = np.argsort(similarities)[::-1]
selected_examples = [self.example_database[i] for i in sorted_indices[:n_examples]]
return selected_examples
def build_cot_prompt(self, question: str, examples: List[Dict]) -> str:
"""
构建思维链提示
参数:
question: 输入问题
examples: 少样本示例列表
返回:
prompt: 构建的提示字符串
"""
prompt = "你是一位专业的医学专家。请仔细分析以下医学问题,并给出一步一步的推理过程。\n\n"
# 添加少样本示例
for i, example in enumerate(examples):
prompt += f"示例 {i+1}:\n"
prompt += f"问题: {example['question']}\n"
prompt += f"推理: {example['reasoning']}\n"
prompt += f"答案: {example['answer']}\n\n"
# 添加当前问题
prompt += f"现在请分析这个问题:\n"
prompt += f"问题: {question}\n"
prompt += "让我们一步一步思考:\n"
return prompt
def generate_chain_of_thought(self, prompt: str) -> str:
"""
生成思维链推理
参数:
prompt: 构建的提示
返回:
response: 模型响应包含推理链
"""
response = self.model_api.generate(
prompt,
max_tokens=500,
temperature=0.7, # 适度创造性以促进推理
stop=["\n\n"] # 停止条件
)
return response
def self_consistency_check(self, question: str, cot_prompt: str, n_generations: int = 3) -> str:
"""
多轮自洽性检查
参数:
question: 原始问题
cot_prompt: 思维链提示
n_generations: 生成次数
返回:
final_answer: 最终答案
"""
candidate_answers = []
for i in range(n_generations):
# 轻微调整温度以获得多样性
temp = 0.7 + i * 0.1 # 逐渐增加温度
# 生成思维链
cot = self.generate_chain_of_thought(cot_prompt)
# 提取答案
answer_prompt = f"{cot_prompt}{cot}\n因此,最终答案是:"
answer = self.model_api.generate(
answer_prompt,
max_tokens=10,
temperature=temp,
stop=[".", "\n"]
)
candidate_answers.append(answer.strip())
# 选择最一致的答案
final_answer = max(set(candidate_answers), key=candidate_answers.count)
return final_answer
def solve_medical_question(self, question: str) -> Tuple[str, str]:
"""
解决医学问题的完整流程
参数:
question: 医学问题
返回:
final_answer: 最终答案
reasoning_chain: 推理链
"""
# 1. 动态选择示例
examples = self.dynamic_example_selection(question)
# 2. 构建思维链提示
cot_prompt = self.build_cot_prompt(question, examples)
# 3. 自洽性检查获取最终答案
final_answer = self.self_consistency_check(question, cot_prompt)
# 4. 生成完整的推理链(使用最佳答案)
reasoning_chain = self.generate_chain_of_thought(cot_prompt)
return final_answer, reasoning_chain
# 初始化MedPrompt引擎
vectorizer = TfidfVectorizer()
model_api = OpenAIModel(api_key="your_key") # 假设的模型API封装
example_db = [
{
"question": "一名45岁女性因发热、咳嗽和绿色痰液就诊...",
"reasoning": "症状提示呼吸道感染,痰液颜色表明可能细菌感染...",
"answer": "B"
},
# ... 更多示例
]
medprompt = MedPromptEngine(model_api, example_db, vectorizer)
# 使用MedPrompt解决问题
question = "一名65岁男性患者因逐渐加重的呼吸困难和非生产性咳嗽3周就诊..."
answer, reasoning = medprompt.solve_medical_question(question)
print(f"问题: {question}")
print(f"推理过程: {reasoning}")
print(f"最终答案: {answer}")
此代码框架展示了MedPrompt的核心实现逻辑,实际生产系统会更加复杂,包含错误处理、缓存优化和提示模板精细化调整等功能。
实际部署考量
在实际临床环境中部署MedPrompt类系统时,还需考虑以下关键因素:
-
延迟与吞吐量平衡:多轮生成和自洽性检查会增加响应时间,需要根据场景权衡准确性和速度。
-
解释性与可信度:医学应用需要高度透明的决策过程,思维链生成提供了天然的解释性,但需确保其医学准确性。
-
持续评估与更新:建立持续的性能监控机制,定期评估系统在新增医学知识上的表现,及时更新示例库和提示策略。
局限性与未来展望:MedPrompt的进化之路
尽管MedPrompt取得了令人瞩目的成就,但我们必须客观认识其当前局限性,这些局限也为未来研究指明了方向。
技术约束与挑战
MedPrompt方法的主要约束条件包括:
-
基础模型能力上限:MedPrompt的性能本质上受限于所用基础模型的知识容量和能力边界。如果基础模型在某些专业领域知识不足或存在错误偏见,MedPrompt只能缓解而无法根本解决这一问题。
-
计算成本考虑:虽然相比训练专用模型成本更低,但MedPrompt的多轮生成机制仍比单次提示消耗更多计算资源,这在实时性要求高的场景可能成为瓶颈。
-
提示设计复杂性:高质量的MedPrompt提示需要专业领域知识和大量实验优化,这在一定程度上重新引入了专家依赖,尽管相比数据标注成本已大幅降低。
-
领域适应性差异:论文结果显示,虽然MedPrompt在多个领域有效,但提升幅度存在差异,在某些高度专业化的子领域可能仍需一定程度的领域适应。
这些约束条件并不否定MedPrompt的价值,而是指出了其适用边界——在基础模型已有足够知识储备但未能有效提取的领域,MedPrompt效果最为显著;而在基础模型知识严重不足的领域,仍需其他技术补充。
未来研究方向
基于MedPrompt的创新思路和现有局限,我们可以勾勒出几个有前景的未来研究方向:
-
多模态医学应用:当前MedPrompt主要针对文本型医学问题,未来可扩展至多模态场景,如结合医学影像、病理切片和电子健康记录数据,通过多模态提示策略提升综合诊断能力。
-
主动查询优化:现有方法被动响应问题,未来版本可引入主动学习机制,让模型在推理过程中主动寻求缺失信息或澄清模糊描述,更贴近真实临床决策过程。
-
个性化适应机制:结合患者个人病史和特定人群特征,开发能够个性化调整推理策略的MedPrompt变体,提供更精准的个体化医学建议。
-
自动化提示优化:利用自动化机器学习技术优化提示策略,减少人工设计成本,使MedPrompt类方法更容易被非技术专家采纳。
-
长期知识维护:开发能够跟踪医学知识进展的提示策略更新机制,确保系统随医学发展同步进化,避免知识过时。
这些研究方向不仅适用于医学领域,也可推广至其他专业领域,如法律、金融和教育等,展现通用基础模型与提示工程结合的广阔前景。
通用智能的专业化新范式
MedPrompt代表了一种重要的范式转变——从训练专用模型转向激发通用潜力。这一转变不仅技术意义重大,更可能重塑AI产业生态。组织不再需要为每个应用领域训练维护专用模型,而是可以通过统一的基础模型配合定制化提示策略,满足多样化专业需求。
论文《Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine》的贡献远超出医学领域范畴,它为我们提供了一种思考AI专业化问题的新框架。在这个框架中,专业性与通用性不是对立关系,而是通过恰当的交互设计可以同时实现的目标。
随着基础模型能力的持续进步和提示工程技术的日益成熟,我们有望进入一个基础模型+提示策略主导的AI新时代。在这一时代中,如MedPrompt这样的智能激发策略将扮演越来越重要的角色,成为连接通用智能与专业应用的桥梁,最终推动AI在医学等高风险、高价值领域的更广泛应用和更深度融合。
这一进展不仅具有技术意义,更有深刻的社会价值——通过降低专业AI应用的门槛,我们可以加速智能技术在各专业领域的普及,使更多人和组织受益于AI进步,最终推动社会整体的知识效率和决策质量提升。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











