




 本文提出了一种纯Transformer架构的图像识别模型ViT,无需CNN,展示了在大规模数据集预训练后,其在图像分类任务上的优秀性能。ViT通过将图像切分为patch,结合位置编码,输入到Transformer Encoder中,经过学习,达到了与深度残差网络(Resnet)相当甚至更好的效果。预训练和多模态的应用前景被看好。
本文提出了一种纯Transformer架构的图像识别模型ViT,无需CNN,展示了在大规模数据集预训练后,其在图像分类任务上的优秀性能。ViT通过将图像切分为patch,结合位置编码,输入到Transformer Encoder中,经过学习,达到了与深度残差网络(Resnet)相当甚至更好的效果。预训练和多模态的应用前景被看好。
题目:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
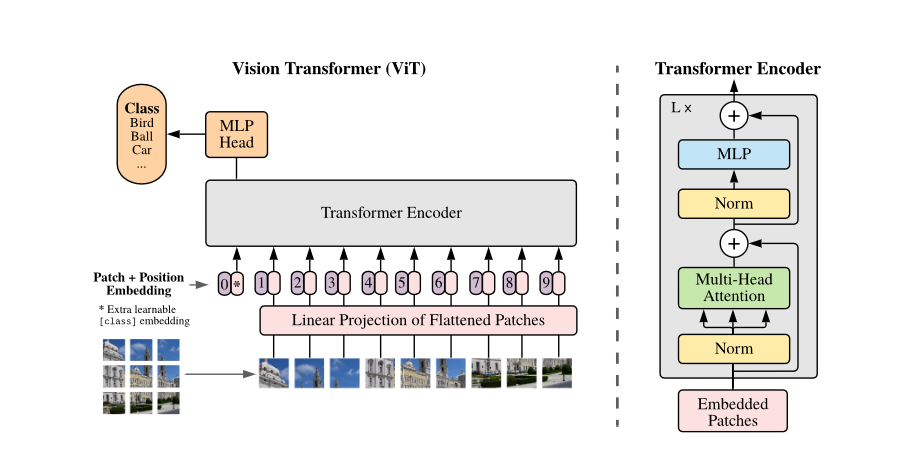 1.概述
1.概述
之前的transformer在cv中应用,大部分是将CNN模型中部分替换成transformer block(整体网络结构不变)或者用transformer将不同网络连接起来,而本文提出:一个针对图像patch的纯的transformer可以很好地完成图像分类任务,无需CNN的参与,这无疑打通了nlp和cv的壁垒。除此之外,相比于相同效果的CNN网络,VIT只需更少的计算资源。
transformer之所以只应用于部分代替,原因是:需要每个token进行两两计算关系,其复杂度是O(n^2)
,如果使用逐像素输入,则无法承担这么大的计算量,故为了降低输入序列的长度,之前的做法有:(文中提及的处理序列太长问题的方法)
- 对Feature Map进行transfomer,如 14×14的特征图也就是1×196的序列长度,可以承受。
- Stand-Alone Attention(孤注意力):使用一个local window进行输入,再进行平滑。利用这种局部多头点积自注意力块完全替代卷积。
- Sparse Transformer:采用可伸缩的全局自注意力近似,以便适用于图像。
- Axial Attention(轴注意力):属于scale attention方法,是将其应用于不同大小的块中,在极端情况下仅沿个别轴。
注:《Efficient Transformers: A Survey》,对近两年来提出的高效率的Transformer做了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2447
2447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









