




基本概念
littlefs中设计了两种类型的链表,一个是ctz链表,把单个文件占用的多个物理block串起来;另外一个是目录链表,将所有目录占用的物理block串起来。
block pair
block pair是特殊的一对block,互为主备的身份,用于存储元数据,并且只会存储一个目录的信息。Block pair的数据更新逻辑如下所示:
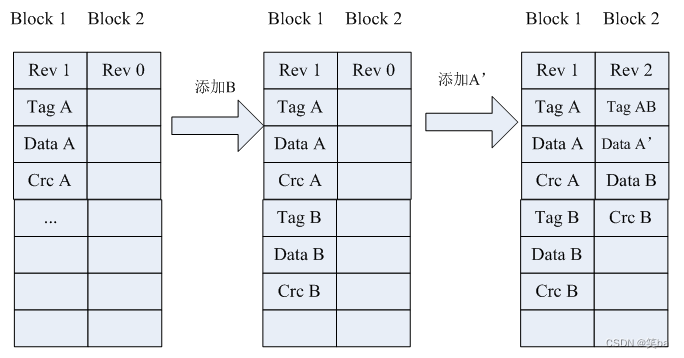
rev表示当前block数据的新旧程度,rev的值越大,数据越新。当block1 存储满了之后,会对数据进行多余内容的剔除(压缩),然后全部提交到block2中。
tag
对文件系统的任何修改,都会通过tag来标识本次操作的属性,该tag会提交到对应的block pair中。
Tag的标准结构如下图所示:

其中,valid标识tag是否有效,type是操作的类型(创建、删除、更新等),id是文件的唯一id号,length是额外数据的长度,data就是额外的数据,例如:当创建文件的时候,需要额外的信息来说明文件的名字。
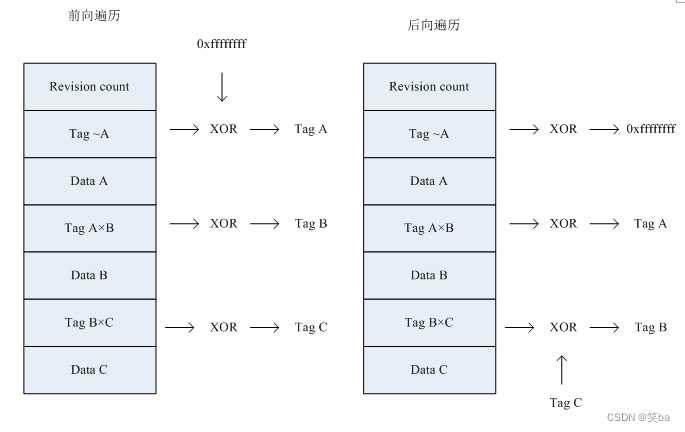
特别说明:valid为0说明是有效的,并且tag是大端模式存储的,这样valid就直接在地址的最低端存在,顺序访问flash的时候,能快速判断tag是否有效。
一个block中的第一个tag需要与0xffffffff异或,然后写入flash,第二个tag需要和第一个tag异或,再写入flash,这样设计的目的,是为了以最小的代价,达成block能够前向遍历和后向遍历的目的。
后向遍历的主要作为是为了快速读取文件的信息,因为tag是最新的才是有效值,而最新的往往在block的后面位置,通过后向遍历,能减少遍历的时间,加快访问。
ctz list
下图所示,为传统的COW类型文件系统增加block的过程。
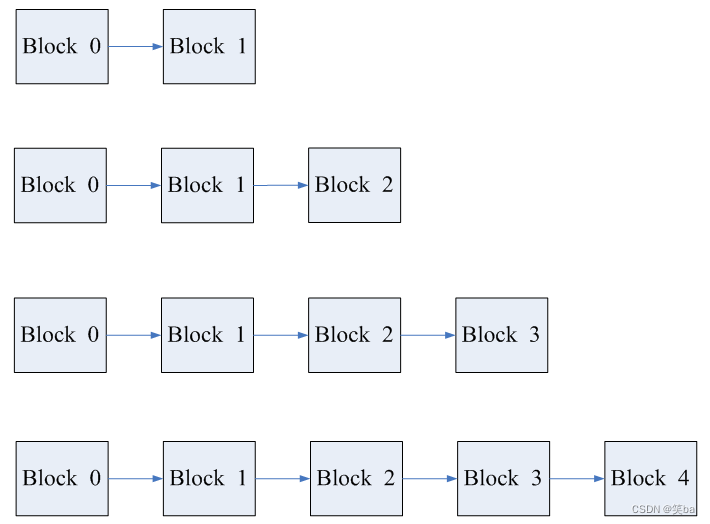
图 传统的方式添加数据
传统的方式添加数据,需要建立旧的数据到新的数据的索引。这样做有两个弊端:
(1)当数据特别多的时候,这样一个个的索引过去查找,比较费时间。
(2)当使用cow机制的时候,在文件后面每增加一次数据,需要把所有的索引都重新建立一个,这样带来的性能损耗特别大。
为了解决这两个问题,littlefs设计了ctz list,其利用ctz的特性和反向链接的思想,为不同的块之间添加了多个链接,ctz list添加数据的方式如下图所示:
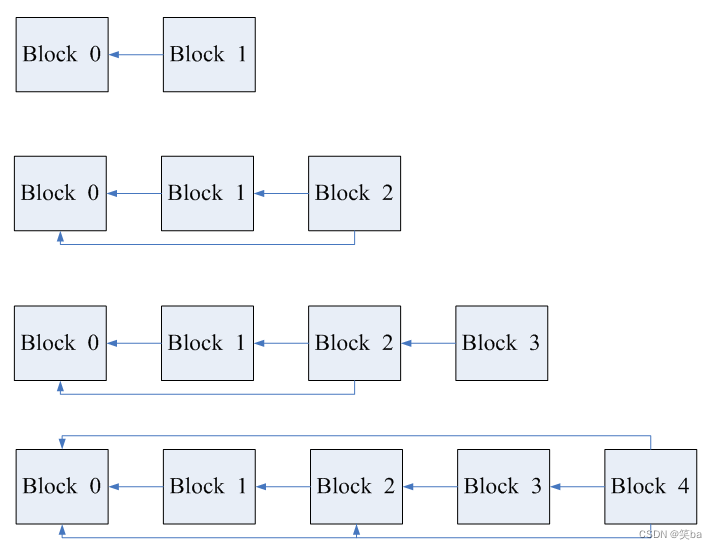
图 ctz list添加数据
具体的优化为:
- 采用逆向的指针,这样常规的追加数据,不需要额外的开销来重新建立所有的索引;
- 每个偶数block有多个指针,指向更远的数据,这样可以在检索的时候加快速度。
指针的建立采用了CTZ(二进制中最后一个不为0的位,其右边0的个数)的方式。大概原理就是,block N 如果是一个能被 2^X整除的数,那么他就存在指向N – 2^X的指针,指针的数目为ctz(N)+1。
|
Block N |
0 |
1 |
2 |
3 |
4 |
5 |
|
二进制 |
000 |
001 |
010 |
011 |
100 |
101 |
|
ctz(N)+1 |
1 |
1 |
2 |
1 |
3 |
1 |
|
X |
0 |
0 |
0,1 |
0 |
0,1,2 |
0 |
|
2^X |
1 |
1 |
1,2 |
1 |
1,2,4 |
1 |
|
N – 2^X |
-1 |
0 |
0,1 |
2 |
0,2,3 |
4 |
从上表可以看出,block 2多一个指向0的指针,block 4多一个指向0,2的指针。
dir list
目录的信息都存储在block pair,为了加快遍历的过程,littlefs设计了dir list,将目录涉及到的block pair都串起来了。

lookahead table
内存中的一个数组,用来表示block有没有被使用,了节省内容,Littlefs对空闲block的管理采用了滑窗方式,滑窗的大小是可以配置,默认是32bit,对应32个block的使用情况。
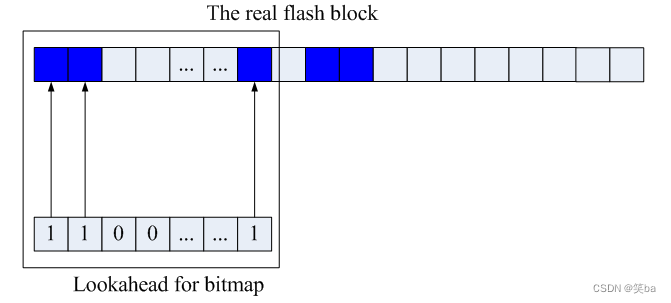
图1 初始状态
当文件系统需要申请一个空闲的block的时候,从lookahead中寻找没有置位的block,申请成功,则给对应的block位置1。当当前的窗口中的所有block都被占用的时候,就需要滑动窗口了,一次性滑动窗口大小的距离,即默认一次滑动32个block。
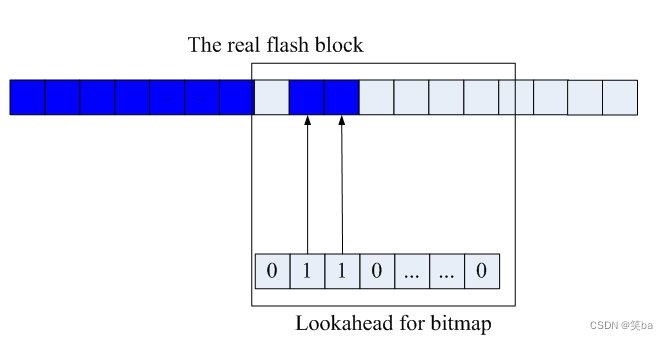
图2 滑动一次
为了让文件系统mount的时候,滑窗不是总是从flash的前半部分开始的,littlefs将文件系统中所有crc进行异或,得到了一个随机的值,这个值与block数目进行运算,从而得到了一个随机的起始偏移,解决了滑窗初始化位置固定的问题。
内部接口说明
commit
操作对象为:block pair
commit操作,是往目录对应的block pair提交新的修改信息,这些修改可能是:创建文件,删除文件,写文件,移动文件等。
commit操作,在以下几种场景下会发生:
(1)创建
涉及到LFS_TYPE_CREATE、LFS_TYPE_NAME、LFS_TYPE_STRUCT、LFS_TYPE_CRC,创建目录还涉及到LFS_TYPE_TAIL。
(2)删除
涉及到LFS_TYPE_DELETE、LFS_TYPE_CRC、LFS_TYPE_GLOBALS,删除目录还涉及到LFS_TYPE_TAIL
(3)写文件
涉及到LFS_TYPE_STRUCT、LFS_TYPE_CRC
(4)移动文件(最复杂)
涉及到涉及到LFS_TYPE_CREATE、LFS_TYPE_NAME、LFS_TYPE_STRUCT、LFS_TYPE_DELETE、LFS_FROM_MOVE、LFS_TYPE_CRC、LFS_TYPE_GLOBALS,移动目录还涉及到LFS_TYPE_TAIL
compact
操作对象为:block pair
compact操作,是当commit失败或者block pair快满了的时候,需要把主block中commit的信息,压缩了之后,挪到备block中去,然后主备转换;
这个压缩的过程,就是把属性为LFS_TYPE_SPLICE、LFS_TYPE_FROM、LFS_TYPE_GLOBALS的修改删掉,把属性为LFS_TYPE_NAME、LFS_TYPE_USERATTR、LFS_TYPE_STRUCT的修改每个文件保留最新的一个(如果文件被删除了,对应的这三个属性也要删掉),LFS_TYPE_CRC重新计算。
split
操作对象为:block pair
在compact的时候,会先计算一下压缩后需要多少空间,当需要的空间大于一般block大小的时候,会进行分片处理,分裂出一个新的block pair,把前一半的文件信息(LFS_TYPE_NAME、LFS_TYPE_USERATTR、LFS_TYPE_STRUCT)放到前一个block pair,把后一半的文件信息放到新的block pair,并且前一个block pair通过LFS_TYPE_HARDTAIL指向新的block pair。
traverse
遍历整个系统(lfs_fs_traverse)
操作的对象为:ctz list和dir list
触发场景:
(1)df计算文件系统的空间占用情况
(2)更新滑窗的时候,检查块是否空闲
(3)mount的时候,检测是否存在异常掉电的情况
遍历目录(lfs_dir_traverse)
操作的对象为:dir list
触发场景:
(1)commit的时候,一次提交多个修改;
(2)compact的逻辑,过滤多余的提交
fetch
遍历当前的block pair,把文件数目、最大文件id等信息提取出来。
操作对象为:block pair
触发场景:
(1)基本所有场景都会触发
外部接口说明
文件相关的操作
open操作(打开文件)
打开已存在的文件,重点在于获取以下信息,并加入文件的mlist链表:
(1)文件对应的ctz链表头部
(2)文件对应的ctz链表大小
(3)文件当前的偏移(在文件中的)
(4)文件当前的偏移,对应的物理块号
(5)文件当前的偏移(在文件中的),对应在物理块号内部的偏移
(6)文件缓存,用于读写等操作,如果文件是inline类型,需要把数据先读取到文件缓存中
open操作(创建文件)
创建一个新的文件,重点在于以下操作:
(1)根据path,从第一级目录开始,跳到二级目录,然后最终找到文件的父目录,在父目录中遍历一次所有文件,从而获取新文件的id。如果某一级目录不存在,则会创建失败。
(2)将LFS_TYPE_CREATE、LFS_TYPE_REG、LFS_TYPE_INLINESTRUCT放到同一个crc保护的commit里面,提交到父目录中。文件刚创建的时候,是inline类型的,进行write操作的时候,原始数据直接写入到父目录里面。
(3)加入文件的mlist链表
write操作
(1)如果是inline文件,且数据大小不满足outline的需求,直接把数据追加到文件的cache里面。
(2)如果是inline文件,且数据大小满足outline的需求,则申请一个新的block,把历史数据写入block,再把新数据追加到block。
(3)如果是outline文件,则直接申请一个新的block,更新ctz index信息,把历史数据写入block,再把新数据追加到block。
注意
(1)如果写入的数据涉及到多个block,需要申请多个block,每个block都需要更新好ctz index信息。
(2)write的时候,并不会往父目录里面commit inode信息
lseek操作
(1)仅仅更新文件的pos偏移,其对应的的block号以及block内部的偏移,在write和read的时候更新。
read操作
(1)操作比较简单,更新文件的ctz信息,然后读取数据到缓存,当一次读取超过一个block的时候,需要多次更新ctz的信息。
close操作
(1)把cache中的数据,全部更新到flash中;
(2)在父目录里面commit inode信息,根据文件类型的不一样,选择LFS_TYPE_CTZSTRUCT或者LFS_TYPE_INLINESTRUCT类型提交。
(3)从mlist链表中移除
目录相关的操作
open操作(打开目录)
打开已存在的目录,重点在于获取以下信息,并加入目录的mlist链表:
(1)目录对应的block pair;
(2)目录的lfs_mdir结构体信息,包括了目录是否分片,用了多少空间,最后一个tag等。
open操作(创建目录)
创建一个新的目录,重点在于以下操作:
(1)根据path,从第一级目录开始,跳到二级目录,然后最终找到文件的父目录,在父目录中遍历一次所有文件,从而获取新文件的id。如果某一级目录不存在,则会创建失败。
(2)申请新的block pair,commit新的softtail,指向父目录所指向的softtail,即把新的目录,插入到父目录和父目录的softtail之间。
(3)将LFS_TYPE_CREATE、LFS_TYPE_DIR、LFS_TYPE_DIRSTRUCT、LFS_TYPE_SOFTTAIL(指向新创建的目录)放到同一个crc保护的commit里面,提交到父目录中。
(4)加入目录的mlist链表
lseek操作
(1)pos赋值,指向当前目录的第几个文件,.和..的文件序号分别为0和1
read操作
(1)获取当前目录下所有文件的信息,可以理解为ls命令的底层实现函数
close操作
(1)仅仅只是从目录的mlist链表中移除。
文件系统相关的操作
format操作
(1)格式化0,1块,初始化superblock,并且commit LFS_TYPE_CREATE、LFS_TYPE_SUPERBLOCK和LFS_TYPE_INLINESTRUCT信息到0,1块。
mount操作
(1)从flash中提取superblock的信息到内存中,提取不到,则mount失败;
(2)遍历这个文件系统的目录,看看是否存在非安全掉电情况,gstate不为0的情况;
(3)初始化空闲滑窗的基地址
umount操作
(1)释放内存中申请的cache
unlink操作
(1)查看文件系统是否有非安全掉电情况,如果有则修复了;unlink、rename、move操作的时候掉电,可能会出现这个情况;
(2)判断是否为空目录,如果是非空的,直接删除失败;
(3)在父目录里面,commit LFS_TYPE_DELETE;
(4)如果删除的是目录,则将当前目录的前一个soft_node指向当前目录的下一个soft_node,即从soft_node链表里面删除当前目录
statfs操作
(1)遍历整个文件系统,计算目录和文件的大小;
stat操作
(1)读取文件的大小和类型(文件还是目录)。
rename操作
(1)查看文件系统是否有非安全掉电情况,如果有则修复了;unlink、rename、move操作的时候掉电,可能会出现这个情况;
(2)源文件不存在,或者目的文件存在,直接返回失败(但是,看代码,目的文件是目录,且目录为空,好像也允许操作);
(3)在目的文件所在的block pair中commit LFS_TYPE_CREATE, LFS_TYPE_NAME, LFS_FROM_MOVE(说明从哪个block pair过来)
(4)在源文件所在的block pair中commit LFS_TYPE_DELETE
(5)如果操作的是目录,需要修改soft_node指向新的目录,新目录中的soft_node在commit LFS_FROM_MOVE的时候。会自动从旧的目录中复制过来。

















 2407
2407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









