




 本文介绍了如何使用TUTUCLOUD网站在线构建和分析随机森林模型。通过简单几步操作,用户可以上传数据,设置参数,生成并下载PDF格式的分析结果。这个免费的在线工具支持txt和csv格式的文件,对于科研人员分析高维数据非常方便。
本文介绍了如何使用TUTUCLOUD网站在线构建和分析随机森林模型。通过简单几步操作,用户可以上传数据,设置参数,生成并下载PDF格式的分析结果。这个免费的在线工具支持txt和csv格式的文件,对于科研人员分析高维数据非常方便。
随机森林(Random forest)
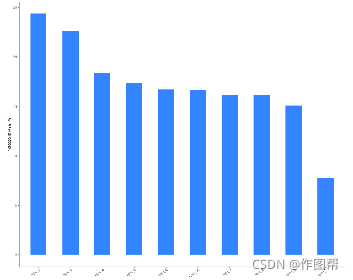
随机森林(Random forest)是利用多棵决策树对样本进行训练并预测的一种分类器。独木不成林,随机森林可以弥补单个决策树泛化能力弱的问题。在机器学习中,随机森林作为一个包含多个决策树的分类器, 其输出的类别是由个别树输出的类别的众数而定的。一般来说,随机森林中任意两棵决策树的相关性越大,错误率越大;每棵决策树的分类能力越强,整个森林的错误率越低,它可以分析高维度数据,并且不用做特征选择,是模型预测的利器。TUTUCLOUD网站云工具可以评估随机森林模型以及重要预测变量的显著性,并以竖向柱状图的形式展示其预测变量的相对重要性的可视化结果。
TUTU网站使用
在线的作图小网站——云图图(www.cloudtutu.com,免费的哦~)可以画,操作步骤如下:
①登录网址:https://www.cloudtutu.com/#/index(推荐使用360或者谷歌浏览器)
②输入用户名和密码(小编已经为大家填好了,如果不显示可添加文末二维码添加小编获取),输入验证码后即可登录,不必注册,直接使用,不必担心隐私泄露,是不是诚意满满~
③登录后在工具一栏(全部分析)里找到随机森林,点击进入;
④请按照界面右侧的说明书或者下文进行操作。
01 上传数据
※目前平台仅支持.txt(制表符分隔)文本文件或者.csv文件的文件上传(平台可对不规范的数据格式进行部分处理,但还是请您尽量按照示例数据的格式调整数据,以便机器可以识别)
a)准备一个数据矩阵(形式参照示例数据);
b)表格需要带表头和列名,每一行为样本名(除第一行),每一列为各种指标数据名(除第一列),例如第二列为环境因子、第三列至以后为OTU名称;
c)请提交txt(制表符分隔)文本文件或者.csv文件。操作方法为:全选excel
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1510
1510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









