



yolov5的模型和整个项目相互关联,所以转onnx无法用常规方法,只能用内部的转onnx方法
一、yolov5模型转onnx
1.静态模型
python export.py --data data/coco.yaml --weights yolov5s.pt --imgsz 640 --include onnx
2.动态模型
python export.py --data data/coco.yaml --weights yolov5s.pt --imgsz 640 --include onnx --dynamic
3.静态与动态的区别:
(1)静态 ONNX 模型的输入形状固定。通常是基于训练时的输入尺寸(默认 640x640, batch size = 1),即输入图片必须符合该尺寸。
优点:静态输入模型在推理时可能会有更好的优化,推理速度更快。
(2)动态 ONNX 模型支持动态输入尺寸。输入图片可以是任意尺寸,不局限于训练时的尺寸(即我w, h, batch 都是可变的)。
优点:灵活性更高,适用于不同分辨率的图片。
缺点:推理速度可能稍微降低,因为引擎需要处理不同的输入尺寸,无法进行特定尺寸的优化。
动态模型如下图所示,batch、width、height为动态的
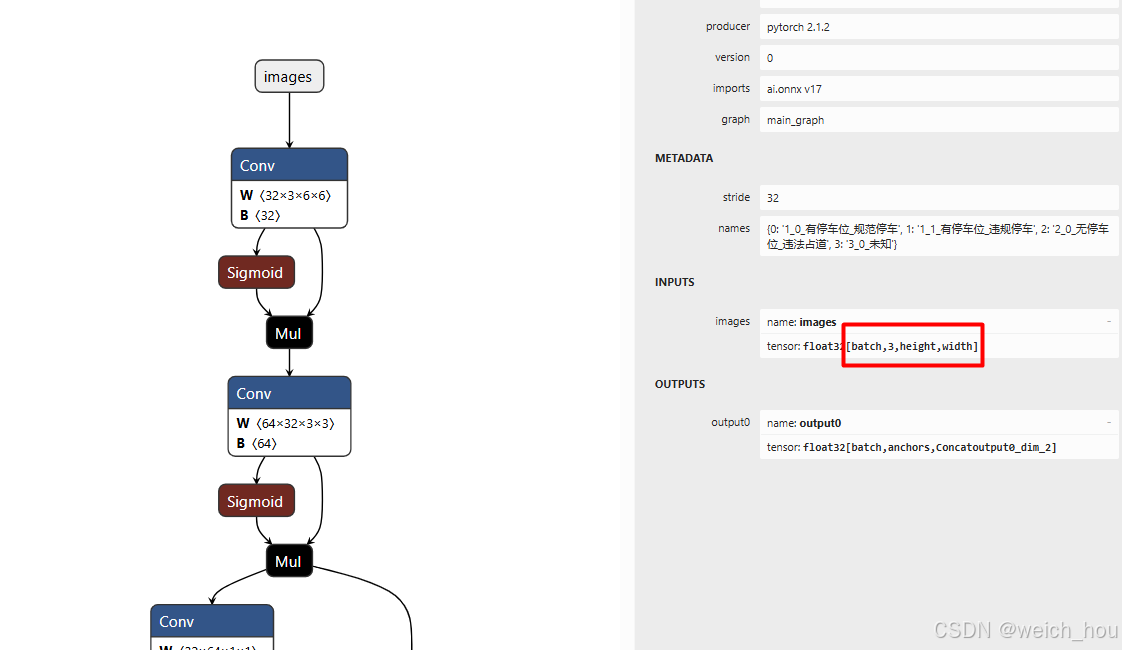
二、yolov5模型
1、推理
1)cv2读取图像并resize
2)图像转BGR2RGB和HWC2CHW
3)图像归一化
4)图像增加维度
5)onnx_session 推理
2、坐标转换
将中心点坐标转换为左上角右下角坐标 [x, y, w, h] to [x1, y1, x2, y2]
def xywh2xyxy(x):
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
return y
3、nms去除重复检测框 & 过滤置信度较低的检测框
根据任务类型设置,分别对每个类别进行nms 和 对全部检测结果进行nms。
完整代码
import os
import cv2
import numpy as np
import onnxruntime
import time
import argparse
from PIL import Image, ImageDraw, ImageFont
CLASSES = ["有停车位_规范", "有停车位_压线", "有停车位_跨位", "无停车位"]
class YOLOV5():
def __init__(self,args):
self.onnx_session=onnxruntime.InferenceSession(args.onnx)
self.conf_thres,self.iou_thres=args.conf_thres,args.iou_thres
self.input_shape=(args.imgsz,args.imgsz)
self.input_name=self.get_input_name()
self.output_name=self.get_output_name()
def get_input_name(self):
input_name=[]
for node in self.onnx_session.get_inputs():
input_name.append(node.name)
return input_name
def get_output_name(self):
output_name=[]
for node in self.onnx_session.get_outputs():
output_name.append(node.name)
return output_name
# 输入图像
def get_input_feed(self,img_tensor):
input_feed={}
for name in self.input_name:
input_feed[name]=img_tensor
return input_feed
def inference(self,img_path):
im=cv2.imread(img_path)
or_img, scale, pad =self.letter_box(im)
img=or_img[:,:,::-1].transpose(2,0,1) #BGR2RGB和HWC2CHW
img=img.astype(dtype=np.float32)
img/=255.0
img=np.expand_dims(img,axis=0)
input_feed=self.get_input_feed(img)
pred=self.onnx_session.run(None,input_feed)[0]
outbox=filter_box(pred, self.conf_thres, self.iou_thres)
for box in outbox:
box[0]=(box[0]-pad[0])/scale
box[1]=(box[1]-pad[1])/scale
box[2]=(box[2]-pad[2])/scale
box[3]=(box[3]-pad[3])/scale
im=draw(im,outbox)
# cv2.imencode(".jpg", img)[1].tofile('res.jpg')
cv2.imwrite('res.jpg',im)
return im
def letter_box(self,img):
# Resize and pad image while meeting stride-multiple constraints
shape = img.shape[:2]
new_shape = self.input_shape
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
nh, nw = int(shape[0] * r), int(shape[1] * r)
new_img = cv2.resize(img, (nw, nh), interpolation=cv2.INTER_LINEAR)
top = int((new_shape[0] - nh) / 2)
bottom = new_shape[0] - nh - top
left = int((new_shape[1] - nw) / 2)
right = new_shape[1] - nw - left
new_img = cv2.copyMakeBorder(new_img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114))
return new_img, r, (left, top, right, bottom)
def cv2AddChineseText(img, text, position, textColor=(255, 0, 0), textSize=20):
if isinstance(img, np.ndarray):
img = np.array(img, dtype=np.uint8)
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img)
fontText = ImageFont.truetype('/home/liyaze/crnn/crnn_tools/NotoSansCJK-Bold.otf', textSize, encoding="utf-8")
draw.text((position[0], position[1]-20), text, textColor, font=fontText)
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
def draw(image,box_data):
if len(box_data) == 0:
print('No parked vehicle detected !')
image = cv2.putText(image, 'No parked vehicle detected !', (10, 100), cv2.FONT_HERSHEY_TRIPLEX, 2, (0, 0, 255), 2)
else:
boxes=box_data[...,:4].astype(np.int32)
scores=box_data[...,4]
classes=box_data[...,5].astype(np.int32)
for box, score, cl in zip(boxes, scores, classes):
left, top, right, bottom = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(left, top, right, bottom))
cv2.rectangle(image, (left, top), (right, bottom), (255, 0, 0), 2)
image = cv2AddChineseText(image, '{0} {1:.2f}'.format(CLASSES[cl], score), (left, top+20), (255, 0, 0), 40)
return image
def nms(dets, thresh):
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
areas = (y2 - y1 + 1) * (x2 - x1 + 1)
scores = dets[:, 4]
keep = []
index = scores.argsort()[::-1]
while index.size > 0:
i = index[0]
keep.append(i)
x11 = np.maximum(x1[i], x1[index[1:]])
y11 = np.maximum(y1[i], y1[index[1:]])
x22 = np.minimum(x2[i], x2[index[1:]])
y22 = np.minimum(y2[i], y2[index[1:]])
w = np.maximum(0, x22 - x11 + 1)
h = np.maximum(0, y22 - y11 + 1)
overlaps = w * h
ious = overlaps / (areas[i] + areas[index[1:]] - overlaps)
idx = np.where(ious <= thresh)[0]
index = index[idx + 1]
return keep
def xywh2xyxy(x):
# [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
return y
def filter_box(org_box,conf_thres,iou_thres): #过滤掉无用的框
org_box=np.squeeze(org_box)
conf = org_box[..., 4] > conf_thres
box = org_box[conf == True]
cls_cinf = box[..., 5:]
cls = []
for i in range(len(cls_cinf)):
cls.append(int(np.argmax(cls_cinf[i])))
all_cls = list(set(cls))
output = []
for i in range(len(all_cls)):
curr_cls = all_cls[i]
curr_cls_box = []
curr_out_box = []
for j in range(len(cls)):
if cls[j] == curr_cls:
box[j][5] = curr_cls
curr_cls_box.append(box[j][:6])
curr_cls_box = np.array(curr_cls_box)
# curr_cls_box_old = np.copy(curr_cls_box)
curr_cls_box = xywh2xyxy(curr_cls_box)
curr_out_box = nms(curr_cls_box,iou_thres)
for k in curr_out_box:
output.append(curr_cls_box[k])
output = np.array(output)
return output
if __name__=="__main__":
parse = argparse.ArgumentParser(description='YOLOv5 inference on images and videos')
parse.add_argument('--img', type=str, default='1d5a110_20240910_163745494_2.jpg', help='image path')
parse.add_argument('--onnx', type=str, default='runs/train/exp2/weights/best.onnx', help='image path')
parse.add_argument('--imgsz', type=int, default=640, help='image path')
parse.add_argument('--conf_thres', type=float, default=0.3, help='confidence threshold')
parse.add_argument('--iou_thres', type=float, default=0.5, help='nms threshold')
parse.add_argument('--show', default=False, action="store_true", help='display detect results')
args = parse.parse_args()
model = YOLOV5(args)
img = model.inference(args.img)
if args.show:
cv2.imshow('img',img)
cv2.waitKey(0)


















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









