




 这是一个关于尚硅谷Kafka的详细教程,涵盖从基础概念到高级特性的全面讲解,包括Kafka的安装、启动、命令行操作、消息生产与消费、数据一致性、API使用等,旨在帮助学习者深入理解Kafka的架构和应用。
这是一个关于尚硅谷Kafka的详细教程,涵盖从基础概念到高级特性的全面讲解,包括Kafka的安装、启动、命令行操作、消息生产与消费、数据一致性、API使用等,旨在帮助学习者深入理解Kafka的架构和应用。
介绍
尚硅谷Kafka教程(kafka框架快速入门) 600分钟
https://www.bilibili.com/video/BV1a4411B7V9?p=1
git 学习源码
https://github.com/wei198621/bigdata_kafka
官方资料 含有源码
https://my.oschina.net/jallenkwong/blog/4449224#h2_61
尚硅谷大数据技术之Kafka(2019新版)源码笔记,视频bilibili上有
链_接_:https://pan.baidu.com/s/1cYSSpIlIqBRHlYPxJUmttg
口_令_:juy7
资源位置
https://download.youkuaiyun.com/download/wei198621/14975193
kafka官网 : http://kafka.apache.org/downloads
第一章 kafka 概述
第二章 kafka 快速入门
第三章 kafka 架构深入
第四章 kafka API
第五章 kafka 监控
第六章 Flume 对接KAFKA
第七章 kafka面试题
学习实现 (2021 01 31 ~ )
目录
P01_尚硅谷_Kafka入门_课程介绍 05:08
P02_尚硅谷_Kafka入门_定义 02:54
P03_尚硅谷_Kafka入门_消息队列 10:23
P04_尚硅谷_Kafka入门_消费模式 10:27
P05_尚硅谷_Kafka入门_基础架构 23:05
P06_尚硅谷_Kafka入门_安装&启动&关闭 20:59
P07_尚硅谷_Kafka入门_命令行操作Topic增删查 15:55
P08_尚硅谷_Kafka入门_命令行控制台生产者消费者测试 11:18
P09_尚硅谷_Kafka入门_数据日志分离 10:02
P10_尚硅谷_Kafka入门_回顾 20:39
P11_尚硅谷_Kafka高级_工作流程 09:45
P12_尚硅谷_Kafka高级_文件存储 12:45
P13_尚硅谷_Kafka高级_生产者分区策略 07:02
P14_尚硅谷_Kafka高级_生产者ISR 22:55
P15_尚硅谷_Kafka高级_生产者ACk机制 08:36
P16_尚硅谷_Kafka高级_数据一致性问题 13:25
P17_尚硅谷_Kafka高级_ExactlyOnce 09:22
P18_尚硅谷_Kafka高级_生产者总结 05:25
P19_尚硅谷_Kafka高级_消费者分区分配策略 20:41
P20_尚硅谷_Kafka高级_消费者offset的存储 30:38
P21_尚硅谷_Kafka高级_消费者组案例 13:14
P22_尚硅谷_Kafka高级_高效读写&ZK作用 10:19
P23_尚硅谷_Kafka高级_Ranger分区再分析 05:56
P24_尚硅谷_Kafka高级_事务 09:36
P25_尚硅谷_Kafka高级_API生产者流程 08:44
P26_尚硅谷_Kafka高级_API普通生产者 24:01
P27_尚硅谷_Kafka高级_回顾 20:38
P28_尚硅谷_Kafka案例_API带回调函数的生产者 17:06
P29_尚硅谷_Kafka案例_API生产者分区策略测试 06:04
P30_尚硅谷_Kafka案例_API自定义分区的生成者 20:39
P31_尚硅谷_Kafka案例_API同步发送生成者 08:07
P32_尚硅谷_Kafka案例_API简单消费者 22:58
P33_尚硅谷_Kafka案例_API消费者重置offset 12:39
P34_尚硅谷_Kafka案例_消费者保存offset读取问题 05:58
P35_尚硅谷_Kafka案例_API消费者手动提交offset 22:09
P36_尚硅谷_Kafka案例_API自定义拦截器(需求分析) 06:15
P37_尚硅谷_Kafka案例_API自定义拦截器(代码实现) 09:24
P38_尚硅谷_Kafka案例_API自定义拦截器(案例测试) 10:41
P39_尚硅谷_Kafka案例_监控Eagle的安装 14:37
P40_尚硅谷_Kafka案例_监控Eagle的使用 18:00
P41_尚硅谷_Kafka案例_Kafka之与Flume对接 13:05
P42_Kafk之与Flume对接(数据分类) 11:37
P43_Kafka之Kafka面试题 24:28
kafka 指令示例
01 启动 kafka zookeeper
[root@kafka01 bin]# pwd
/usr/local/bin
[root@kafka01 bin]# ll
total 16
-rwxr--r--. 1 root root 466 Mar 28 01:51 ctlkafkaauto.sh
-rwxr--r--. 1 root root 394 Mar 28 01:41 ctlzookeeperauto.sh
lrwxrwxrwx. 1 root root 36 Mar 28 00:27 jps -> /usr/local/java/jdk1.8.0_251/bin/jps
-rwxr--r--. 1 root root 154 Mar 28 00:24 xcallkafka.sh
-rwxr--r--. 1 root root 145 Mar 28 01:00 xcallzk.sh
[root@kafka01 bin]# ctlzookeeperauto.sh start
[root@kafka01 bin]# ctlkafkaauto.sh start
[root@kafka01 bin]# xcallzk.sh jps
[root@kafka01 bin]# xcallkafka.sh jps
进入 kafka脚本目录
[root@kafka01 bin]# cd /opt/module/kafka/
[root@kafka01 kafka]# ll
02 topic
001 查看topic列表
[root@kafka01 kafka]# bin/kafka-topics.sh --zookeeper zk1:3001 --list
__consumer_offsets
bigdata
first
002 新建topic
[root@kafka01 kafka]# bin/kafka-topics.sh --zookeeper zk1:3001 --topic second --create --replication-factor 2 --partitions 2
Created topic "second".
[root@kafka01 kafka]# bin/kafka-topics.sh --zookeeper zk1:3001 --list
__consumer_offsets
bigdata
first
second
003 删除某个topic
[root@kafka01 kafka]# bin/kafka-topics.sh --zookeeper zk1:3001 --list
__consumer_offsets
first
second
[root@kafka01 kafka]# bin/kafka-topics.sh --zookeeper zk1:3001 --topic second --delete
Topic second is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
[root@kafka01 kafka]# bin/kafka-topics.sh --zookeeper zk1:3001 --list
__consumer_offsets
first
004-1 查看有哪些消费组
[root@kafka01 kafka]# bin/kafka-consumer-groups.sh --bootstrap-server kafka01:9092 --list
004-2 查看有哪些消费组(老版本)
[root@kafka01 kafka]# bin/kafka-consumer-groups.sh --zookeeper zk1:3001 --list
Note: This will only show information about consumers that use ZooKeeper (not those using the Java consumer API).
test-consumer-group
test-consumer-group1
005 查看某个消费组的详情
在这里插入代码片
03 producer
001 启动消息生产者 向 bigdata 的topic 生成消息
[root@kafka01 kafka]# bin/kafka-console-producer.sh --broker-list kafka01:9092 --topic bigdata
>1111111
------如果增发参数 --from-beginning 表示从头消费
[root@kafka01 kafka]# bin/kafka-console-consumer.sh --zookeeper zk1:3001 --topic bigdata --from-beginning
04 consumer
001 消费者消费消息方式一 : 老的链接zookeeper 方式
此块会使用随机名的消费者组 消费kafka 内容
[root@kafka01 kafka]# bin/kafka-console-consumer.sh --zookeeper zk1:3001 --topic bigdata
1111111
0002 3.3.4 消费者组案例
1)需求:测试同一个消费者组中的消费者,同一时刻只能有一个消费者消费。
2)案例实操
(1)在 kafka01、kafka03上修改/opt/module/kafka/config/consumer.properties 配置
文件中的 group.id 属性为同一组名,本示例为atguigu 。
[root@kafka01 kafka]# pwd
/opt/module/kafka
[root@kafka01 kafka]# vim config/consumer.properties
group.id=atguigu
(2)在 kafka01、kafka03上分别启动消费者
[root@kafka01 kafka]# bin/kafka-console-consumer.sh --zookeeper -zk1:3001 --topic bigdata --consumer.config config/consumer.properties
[root@kafka03 kafka]# bin/kafka-console-consumer.sh --zookeeper zk1:3001 --topic bigdata --consumer.config config/consumer.properties
(3)在 kafka02 上启动生产者 (那个Kafka启动生产者无所谓,重要的是要向 bigdata 的topic 发送数据)
[root@kafka02 kafka]# bin/kafka-console-producer.sh --broker-list kafka01:9092 --topic bigdata
>1111111
(4)查看 kafka01和 kafka03的接收者。
同一时刻只有一个消费者接收到消息。
05 zkCli.sh 查看zookeeper 基本信息
001
----- 本地使用的是3001作为zk的端口,不是默认的2181 所以要单独指定-server 参数
[root@zk1 ~]# cd /root/zookeeper-3.4.12/
[root@zk1 zookeeper-3.4.12]# sh bin/zkCli.sh -timeout 5000 -server 127.0.0.1:3001
...
...
[zk: 127.0.0.1:3001(CONNECTED) 0] ls /
[cluster, controller_epoch, controller, brokers, zookeeper, admin, isr_change_notification, consumers, latest_producer_id_block, config]
---------
---------
[zk: 127.0.0.1:3001(CONNECTED) 1] get /controller
{
"version":1,"brokerid":1,"timestamp":"1617370582722"}
001
在这里插入代码片
第一章 kafka 概述
P01_尚硅谷_Kafka入门_课程介绍 05:08
kafka 是一个分布式的基于发布、订阅模式的 消息队列 (Message Queue),主要应用于大数据实时处理领域。
P02_尚硅谷_Kafka入门_定义 02:54
kafka 是一个基于 发布/订阅模式的分布式消息队列 (Message Queue)
spark — kafka
storm — kafka
flink ----
P03_尚硅谷_Kafka入门_消息队列 10:23
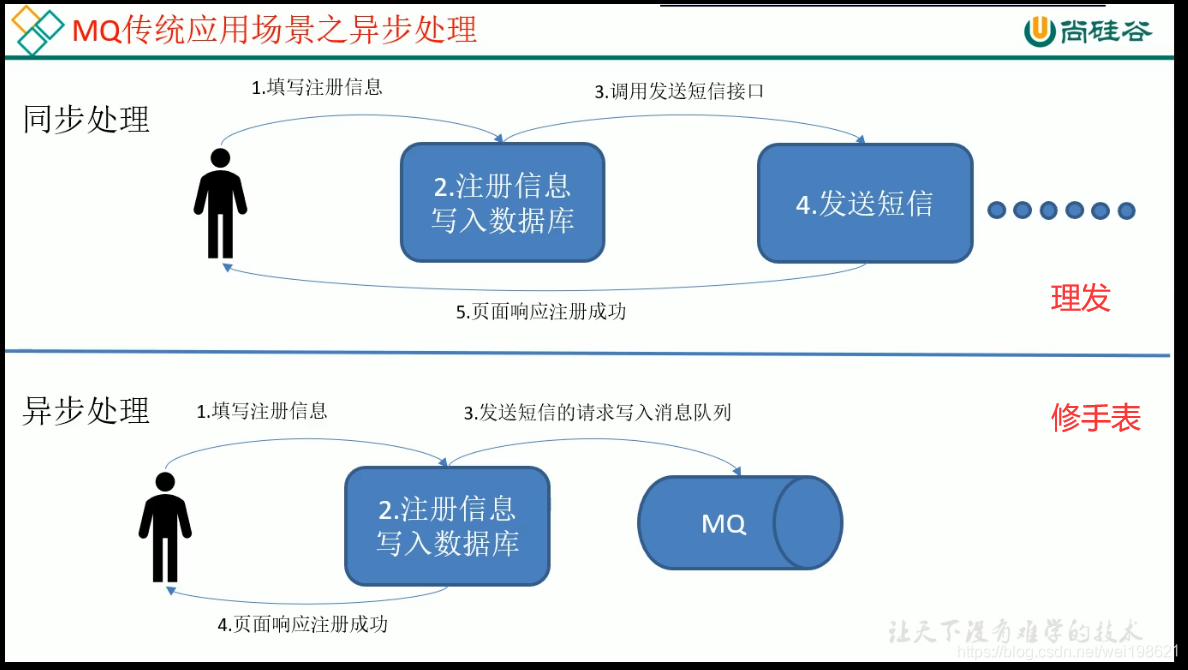
消息队列的好处:
解耦:
削峰
P04_尚硅谷_Kafka入门_消费模式 10:27
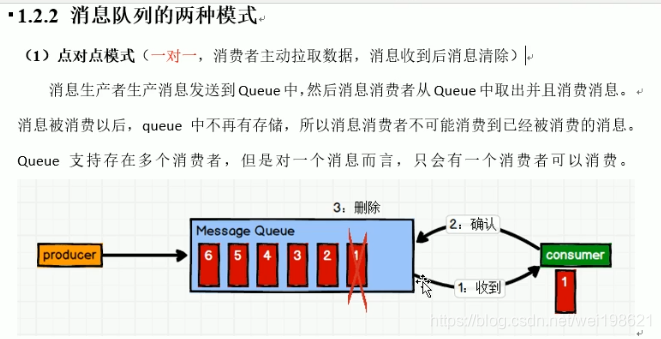
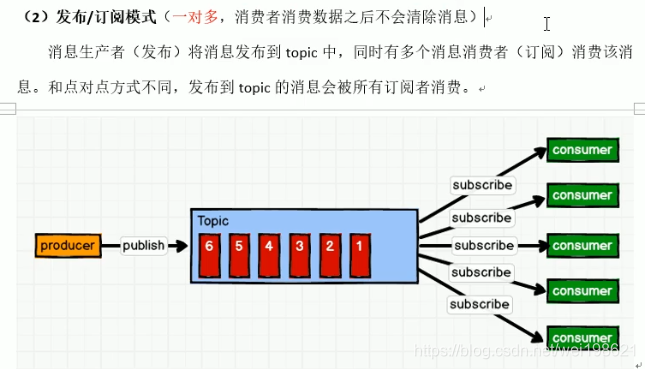
消息队列模式:
- 点对点模式
- 发布-订阅模式
------------------ 2.1 发布者推送模式 (公众号的模式)
------------------ 2.2 消费者拉取模式 (要维护一个长轮询,不断的问,有没有,有没有?kafka 是这种模式)
P05_尚硅谷_Kafka入门_基础架构 23:05
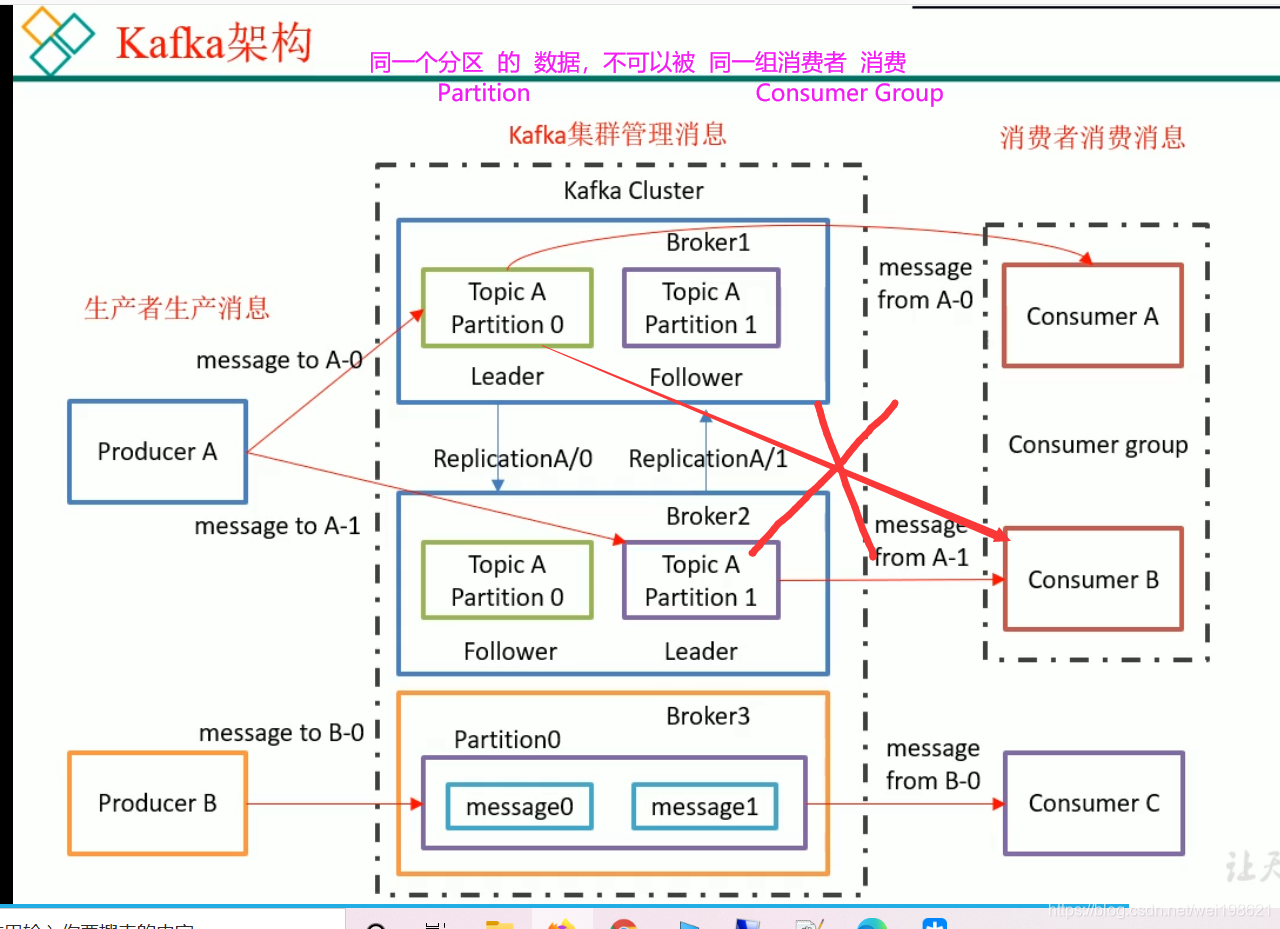
Broker1:Broker2:Broker3: 就是kafka服务器
topicA : 主题将消息做分类
Partition: 分区是做分布式 主从备份用的,生产者消费者只找leader ,follower 用于leader 挂掉的情况下
一个分区(Partition)中的消息,只能被一个消费者组中的某一个消费者消费。(比如TopicA – Partition 0 中的消息,如果被ConsumerA 消费了,就不能被ConsumerB消费,把一个消费者组,看成一个消费团体;消费者组中的消费者个数,与topic中的分区数一致情况下,消息流转效率最高)
zookeeper: 0.9之前用于保存消费消息偏移量 。0.9之后消费消息偏移量存放在本地KAFKA(磁盘)中,默认7天。
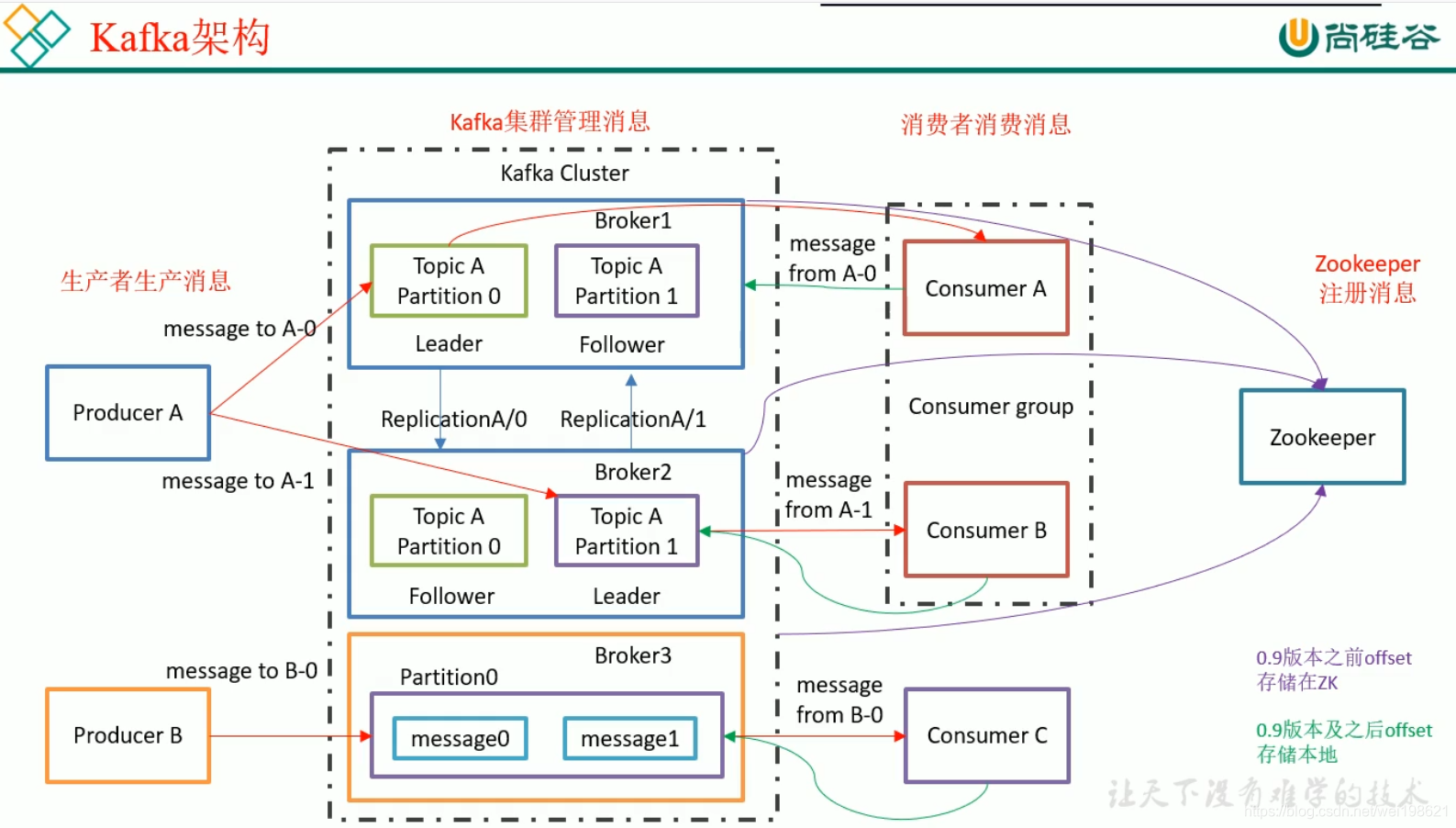 同一个分区中的消息,不可以被同一组消费者消费
同一个分区中的消息,不可以被同一组消费者消费
2021-01-31
2021-03-27
第二种 kafka 快速入门
P06_尚硅谷_Kafka入门_安装&启动&关闭 20:59
kafka官网:http://kafka.apache.org/downloads
kafka最新2.7,kafka 使用 sclar编写
20210217
kafka 使用Scala 编写
本视频使用 0.11 讲解
kafka 基于zookeeper ,所以要先学习zookeeper (暂停此视频的学习)
20210219 继续本篇学习,龟速进展
20210220 继续
20210327 继继续
20210328 继继继续
集群部署
1)解压安装包
[atguigu@hadoop102 software]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C
/opt/module/
2)修改解压后的文件名称
[atguigu@hadoop102 module]$ mv kafka_2.11-0.11.0.0/ kafka
3)在/opt/module/kafka 目录下创建 logs 文件夹
[atguigu@hadoop102 kafka]$ mkdir logs
4)修改配置文件
[atguigu@hadoop102 kafka]$ cd config/
[atguigu@hadoop102 config]$ vi server.properties
输入以下内容:
#broker 的全局唯一编号,不能重复
broker.id=1
#删除 topic 功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接 Zookeeper 集群地址
zookeeper.connect=zk1:3001,zk2:4001,zk3:5001



5)配置环境变量
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export JAVA_HOME=/usr/local/java/jdk1.8.0_251
export JRE_HOME=/usr/local/java/jdk1.8.0_251/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib:$KAFKA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$KAFKA_HOME/bin
6)分发安装包
[atguigu@hadoop102 module]$ xsync kafka/
[root@kafka01 module]# xsync.sh /opt/module/kafka kafka0 2 3
xsync 分发指令时自己单独写的sh 指令,详见
https://blog.youkuaiyun.com/wei198621/article/details/115279861
7)分别在 hadoop103 和 hadoop104 上修改配置文件/opt/module/kafka/config/server.properties
中的 broker.id=1、broker.id=2
注:broker.id 不得重复
原教程 0 1 2 ,我的是 1 2 3
[root@kafka02 module]# vim /opt/module/kafka/config/server.properties
broker.id=2
[root@kafka03 .ssh]# vim /opt/module/kafka/config/server.properties
broker.id=3
8手动启动
8.1)启动zookeeper集群
启动zookeeper zk1-111、zk2-112、zk3-113
121.111 zk1 :3001
121.112 zk2 :4001
121.113 zk3 :5001
----------------zk3-------------------
[root@zk3 zkdata]# pwd
/root/zkdata
[root@zk3 zkdata]# cat zoo.cfg
initLimit=10
syncLimit=5
dataDir=/root/zkdata
clientPort=5001 -------------作为对外端口
server.1=zk1:3002:3003
server.2=zk2:4002:4003
server.3=zk3:5002:5003
[root@zk1 ~]# pwd
/root
[root@zk1 ~]# ll
total 35816
drwxr-xr-x. 3 root root 78 Dec 18 22:11 zkdata
drwxr-xr-x. 10 leo leo 4096 Mar 26 2018 zookeeper-3.4.12
-rw-r--r--. 1 root root 36667596 Apr 10 2020 zookeeper-3.4.12.tar.gz
[root@zk1 ~]# cd /root
[root@zk1 ~]# tree -L 2
.
├── zkdata
│ ├── myid
│ ├── version-2
│ ├── zoo.cfg
│ └── zookeeper_server.pid
├── zookeeper-3.4.12
│ ├── bin
│ ├── build.xml
│ ├── conf
----启动zookeeper01
[root@zk1 bin]# cd /root/zookeeper-3.4.12/bin
[root@zk1 bin]# ./zkServer.sh start /root/zkdata/zoo.cfg
ZooKeeper JMX enabled by default
Using config: /root/zkdata/zoo.cfg
Starting zookeeper ... STARTED
[root@zk1 bin]# jps
10563 Jps
10510 QuorumPeerMain ----已经启动
zookeeper集群的搭建详见
https://blog.youkuaiyun.com/wei198621/article/details/113832427
ZooKeeper 分布式协调服务实战—编程不良人 笔记
8.2)启动kafka集群
依次在 kafka01、kafka02、kafka03 节点上启动 kafka
------- -daemon 作为守护进程启动(后台启动) 不阻塞
[root@kafka01 kafka]# /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
[root@kafka01 kafka]# jps
30612 Jps
30583 Kafka
[root@kafka02 config]# /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
[root@kafka02 config]# jps
31619 Jps
31596 Kafka
[root@kafka03 config]# /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
[root@kafka03 config] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









