




目录
目录
函数递归
将复杂的问题层层化为与原问题相似的规模较小的问题。
递 ---- 递推、归 ---- 回归
递推 :函数一直自己调用自己(调用一个函数时,要把这个函数执行完才执行接下来的语句)直到不满足或满足某个条件停止递推,无限递推没有意义。
(每一次调用函数,都要在内存的栈区里开辟一块空间,为本次函数调用分配的内存空间叫被称为这次函数调用的栈帧空间。若函数无限的递归或递归次数太多,会把内存的栈区消耗完,称为栈溢出,这是函数递归的缺点。有时候,用函数递归能解决的问题,用迭代(循环)也能解决问题,迭代的效率有时候比递推快,比如用迭代求斐波那契数列的第50个数的效率就比用递推快多了,但迭代也可能出现溢出的问题,比如计算10000的阶乘,会超出 int 类型的取值范围)
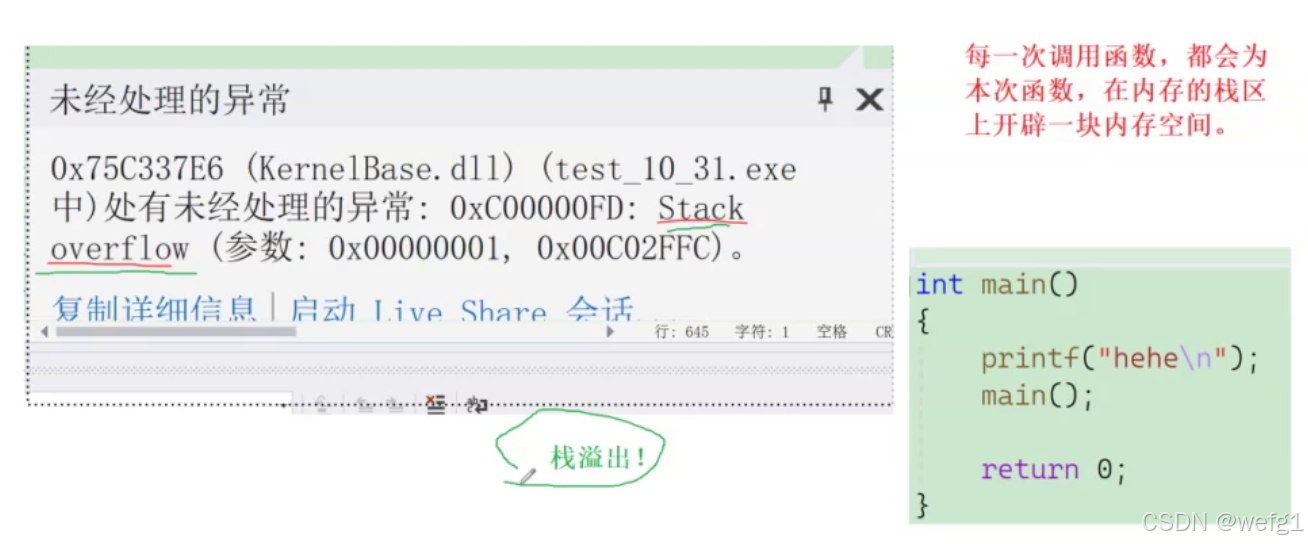
回归 :当不满足或满足某个条件后,最后一次调用的函数的函数体也执行完后,返回到上一次调用该函数的地方,执行完上一次调用该函数的函数的剩余的语句后( 也可能没有剩余的语句,直接返回到上上一次调用该函数的地方),再返回到上上一次调用该函数的地方 ... 直到返回到第一次调用该函数的地方。
递归的两个必要条件
● 存在限制条件,当满足这个限制条件的时候,递归便不再继续。
● 每次递归调用之后越来越接近这个限制条件。
例子:
汉诺塔问题
假设第一个人表示为 (1),第二个人表示为 (2),第 n 个人表示为 (n)
A柱有 64 个盘子,B柱和C柱没有盘子
第一个人做的事情:
(1):(2)63 A -> B , A -> C , (2) 63 B -> C
根据第一个人做的事情,如果 A = 1(起),B = 2(辅), C= 3(终)
第二个人第一次做的事情:
(2):(3)62 A -> C , A -> B , (3) 62 C -> B
或((3)62 1 -> 2 , 1 -> 3 , (3) 62 2 -> 3 )
根据第二个人做的事情,如果 A = 1(起),C = 2(辅), B= 3(终)
第二个人第二次做的事情:
(2):(3)62 B -> A , B -> C , (3) 62 A -> C
或((3)62 1 -> 2 , 1 -> 3 , (3) 62 2 -> 3 )与上次一样
#include <stdio.h>
void move(char x, char y)
{
printf("%c->%c\n", x, y);
}
void hanoi(int n, char one, char two, char three)
{
if (n == 1)
{
move(one, three);
}
else
{
hanoi(n - 1, one, three, two);
move(one, three);
hanoi(n - 1,two, one, three);
}
}
int main()
{
int n = 0;
printf("Please input the number of disk:\n");
scanf("%d", &n);
hanoi(n, 'A', 'B', 'C');
return 0;
}若输入 3,

模拟实现 strlen 函数
#include <stdio.h>
#include <string.h>
int my_strlen(char* a)
{
if (*a != '\0')
return 1 + my_strlen(a+1);
else
return 0;
}
int main()
{
char a[] = "bit";
int r = my_strlen(a);
printf("%d\n", r);
}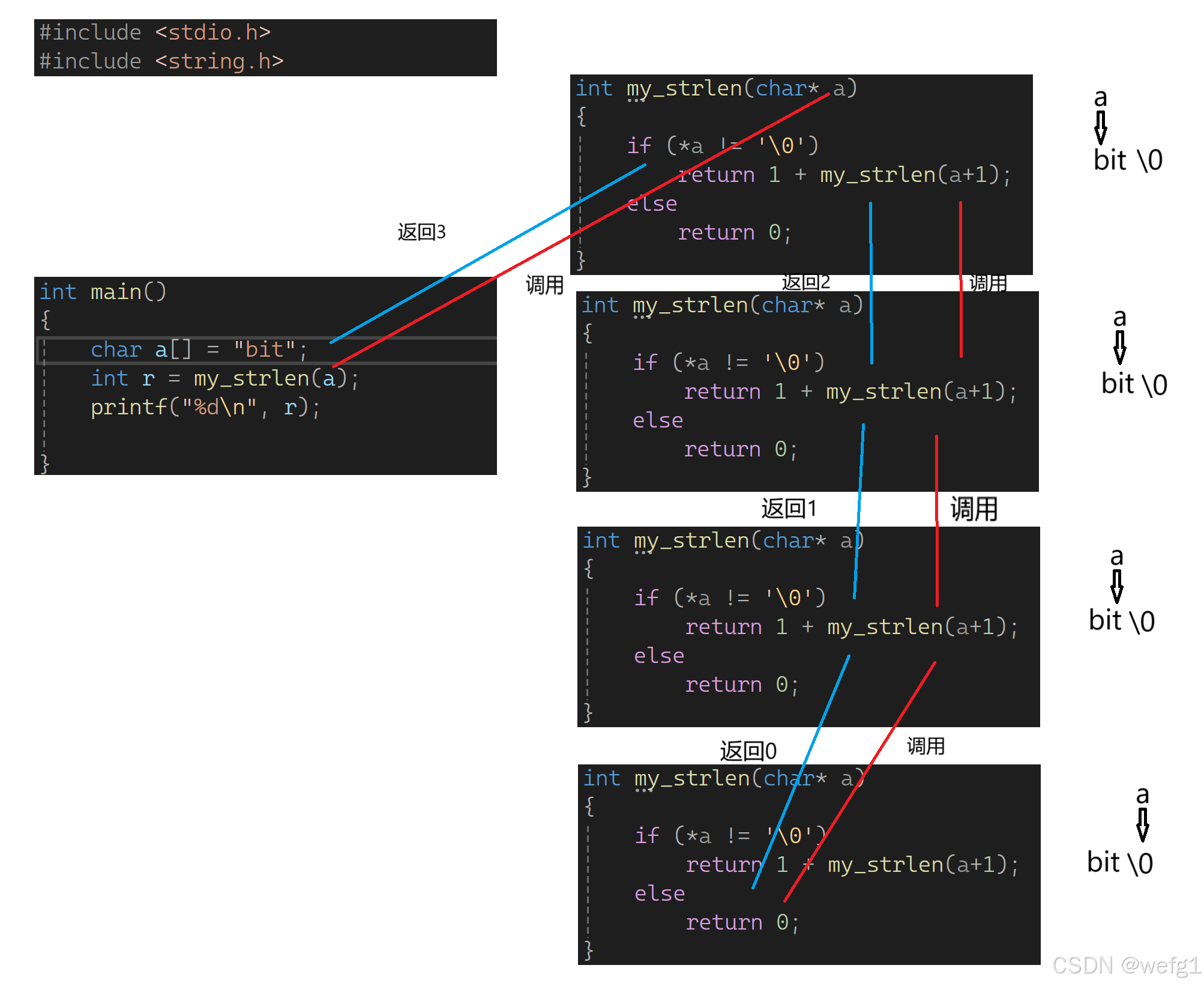
红线是递推过程,蓝线是回归过程
阶乘
int Fac(int n)
{
if (n <= 1)
return 1;
else
return n * Fac(n - 1);
}
int main()
{
int n = 0;
scanf("%d", &n);
int r = Fac(n);
printf("%d\n", r);
}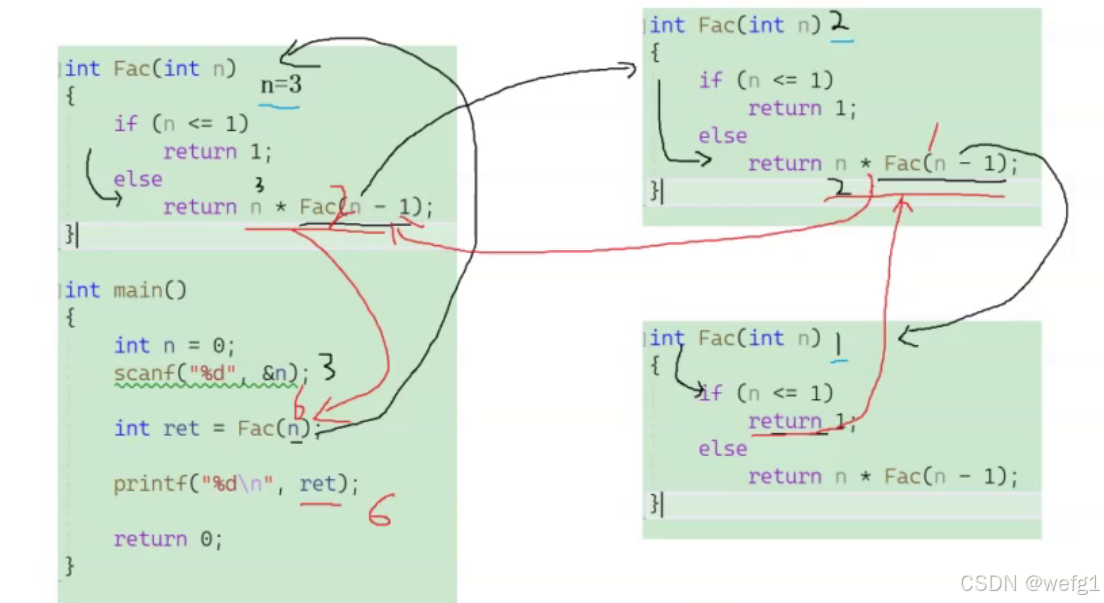
黑线递推,红线回归
函数栈帧的创建与销毁
我们在学习C语言时常常有以下疑问:
比如:
● 局部变量是怎么创建的?
● 为什么局部变量的不初始化的值是随机值?
● 函数是怎么传参的? 传参的顺序是怎样的?
● 形参和实参是什么关系?
● 函数调用是怎么做的?
● 函数调用是结束后怎么返回的?
学习函数栈帧的创建与销毁后,这些疑问就能迎刃而解了。
概述
每一次调用函数,都要在内存的栈区里开辟一块空间,为本次函数调用分配的内存空间叫被称为这次函数调用的栈帧空间。
ebp(栈低指针), esp(栈顶指针) 这2个寄存器中存放的是地址
这2个地址是用来维护当前调用的函数的栈帧的。
栈底的地址比栈顶的要大,地址增大,指针向下移动,地址减小,指针向上移动,
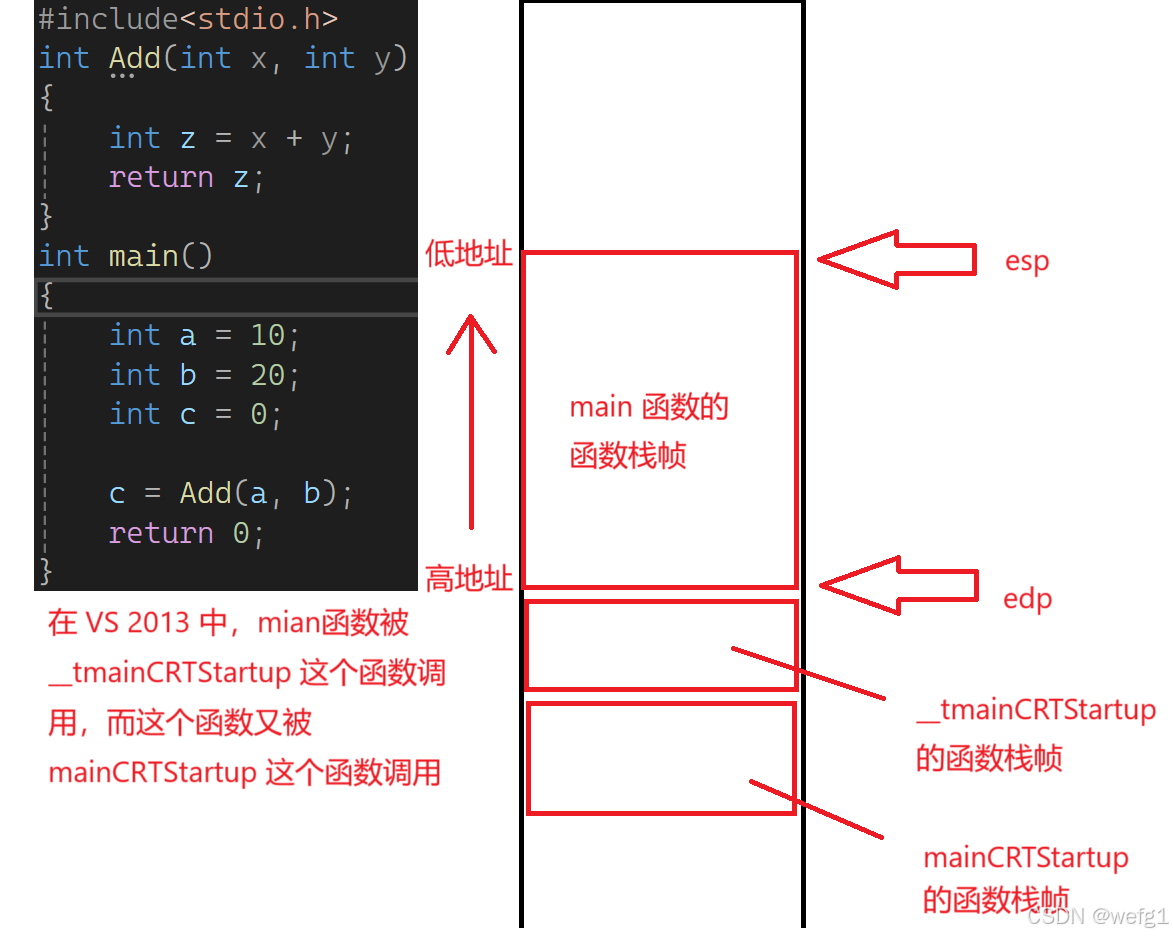
具体的细节: (以下面 C 语言代码为例)
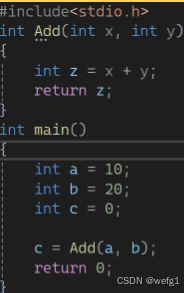
上图 main 函数的部分汇编代码:
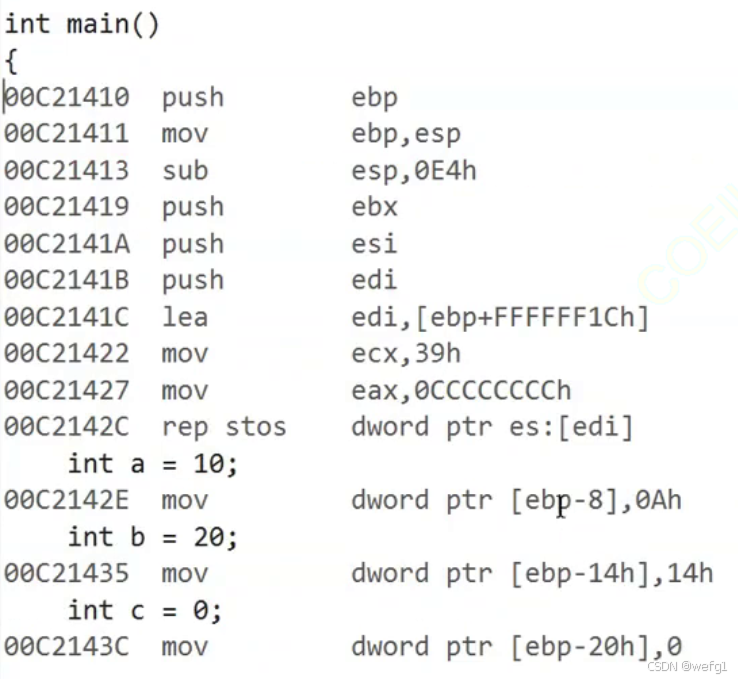
main 函数栈帧的创建
下图是调用 main 函数之前的情况,edp 和 esp 正在维护__tmainCRTStartup 这个函数
接下来开始执行上图的汇编代码了,我们暂不讨论汇编指令的细节,只需知道它们的大概意思。
首先执行第一行汇编代码 push edp:
执行 push edp 之后:
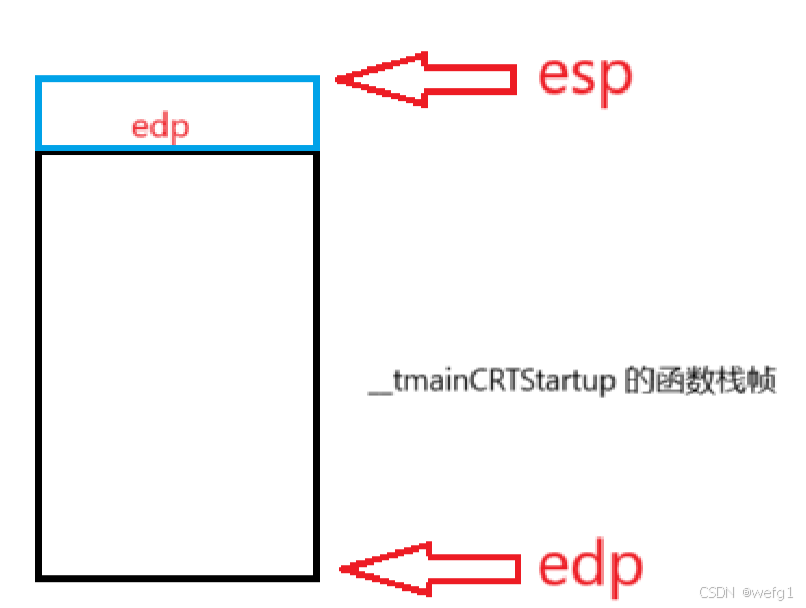
push:压栈,将 edp 放在栈顶,并使 esp 向上移动,栈底的地址比栈顶的要大,可以用监视功能观察 esp 的值减小了。
(压栈(push):在栈顶放一个元素,出栈(pop):从栈顶删除一个元素)
接下来执行 mov edp ,esp:
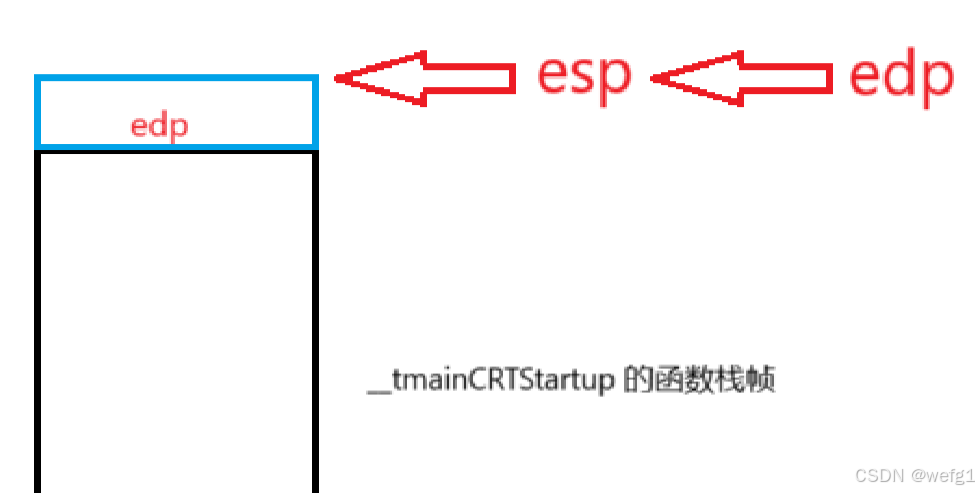
mov edp ,esp 这句话的意思是将 esp 的值赋给 edp ,赋值后 esp 和 edp 就都指向同一个地址了。
接下来执行 sub esp 0E4h;
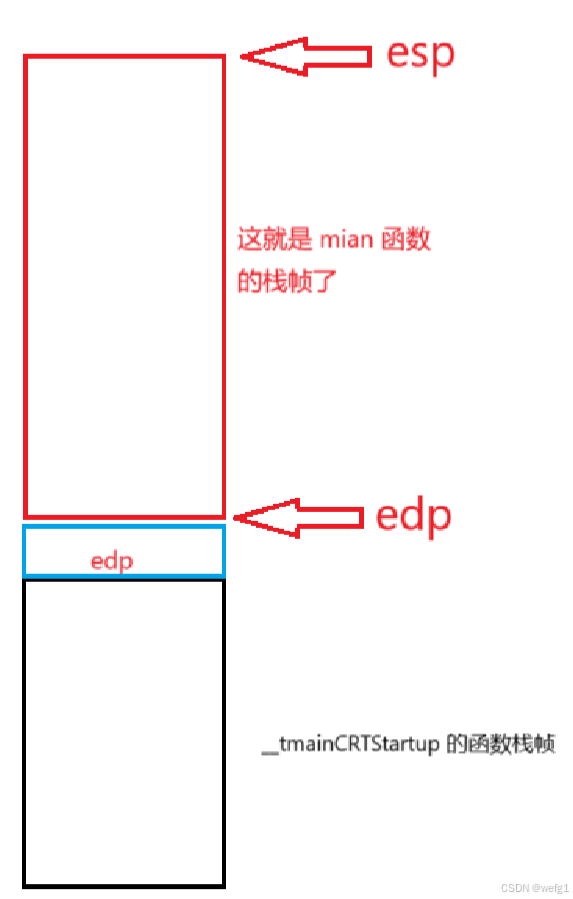
sub esp 0E4h 的意思是将 esp 的值减去 0E4 ,0E4h是一个八进制数(h 是编译器加的,不用理会,看成0E4就好了)十进制大小是 228 ,之前edp 和 esp维护的是 __tmainCRTStartup 的函数栈帧,到现在为止,edp 和 esp 已经在维护一段新的栈帧,这段新的栈帧其实就是为 main 函数开辟好的栈帧。原来,main 函数的汇编代码的前三句是在为 main 函数开辟栈帧。
接下来执行 :
push ebx
push esi
push edi
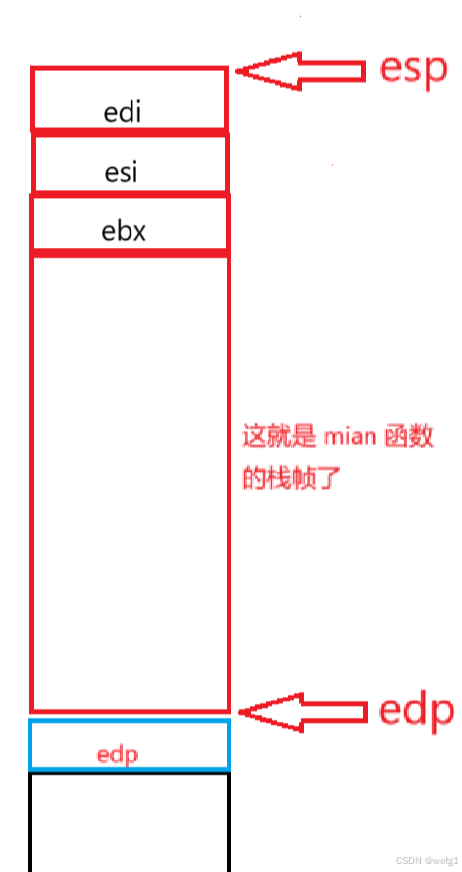
不用知道 ebx 、 esi 、 edi 都是什么,只要知道它们都是寄存器。
接下来执行这四条语句:

结果:
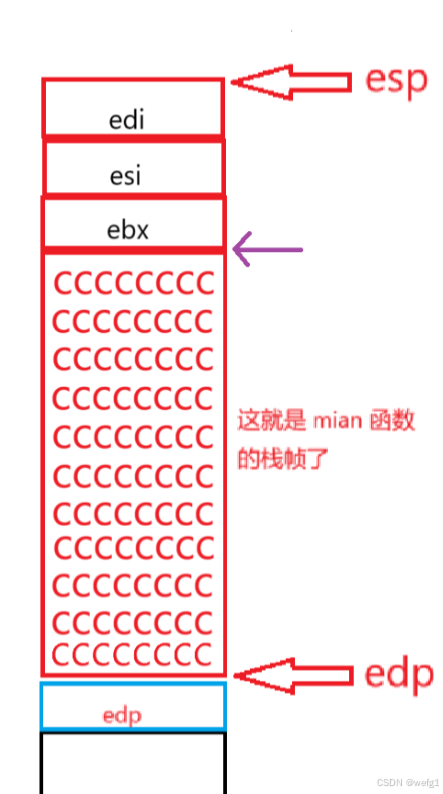
lea edi ,[ edp+FFFFFF1Ch] 其中 lea 是 load effictive address (加载有效地址)的缩写,FFFFFF1Ch 的值其实是 - 0E4h,edp - 0E4h 就是图中紫色箭头的位置。
lea edi ,[ edp - 0E4h] 的意思是将edp - 0E4h这个地址加载到 edi 中。
mov ecx ,39h 的意思就是将 39h 赋值给 ecx ,mov eax ,0CCCCCCCCh 的意思是将0CCCCCCCCh赋值给 eax 。
rep stos dword ptr es : [edi] 的意思:
一个word是两个字节,dword 就是 double word 即四个字节的意思,整句话的意思是将从紫色箭头(edi)的位置开始,每次初始化四个字节,一共初始化 39h 次(初始化次数取决于编译器),初始化的内容是 eax 中存储的内容(0CCCCCCCCh)。
(图中CCCCCCCC的数量不代表实际数量,只作示意)
到目前为止,为 main 函数开辟栈帧并初始化的工作已经结束。接下来才轮到 int a = 10;的汇编代码(汇编代码是不是很麻烦,所以C语言简化了程序设计)
变量的创建
接下来执行
mov dword ptr [edp - 8],0Ah (int a = 10;的汇编代码)
mov dword ptr [edp - 14h],14h (int b = 20;的汇编代码)
mov dword ptr [edp - 20h],0 (int c = 0;的汇编代码)
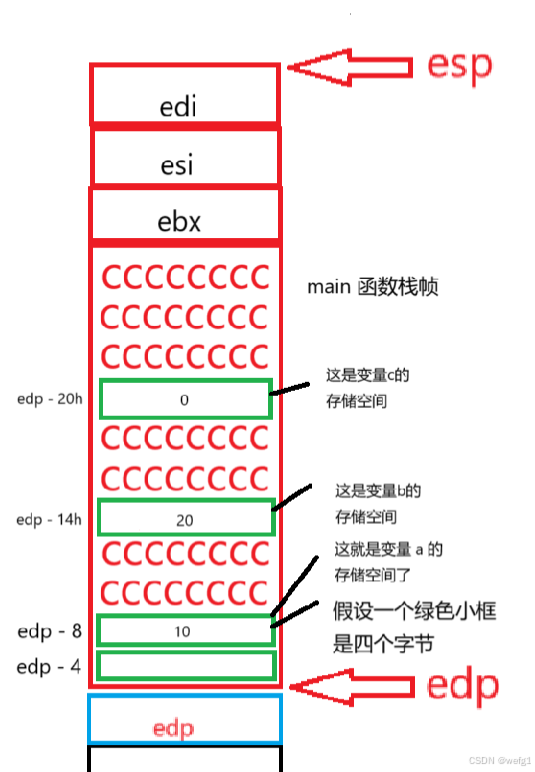
mov dword ptr [edp - 8],0Ah 的意思是将地址为 edp - 8 的存储单元存储的值改为 0Ah (0Ah 就是十进制数 10)edp - 8 就是变量 a 的地址了,b 和 c 变量同理。
栈区的使用习惯:先使用高地址的空间后使用低地址的空间。
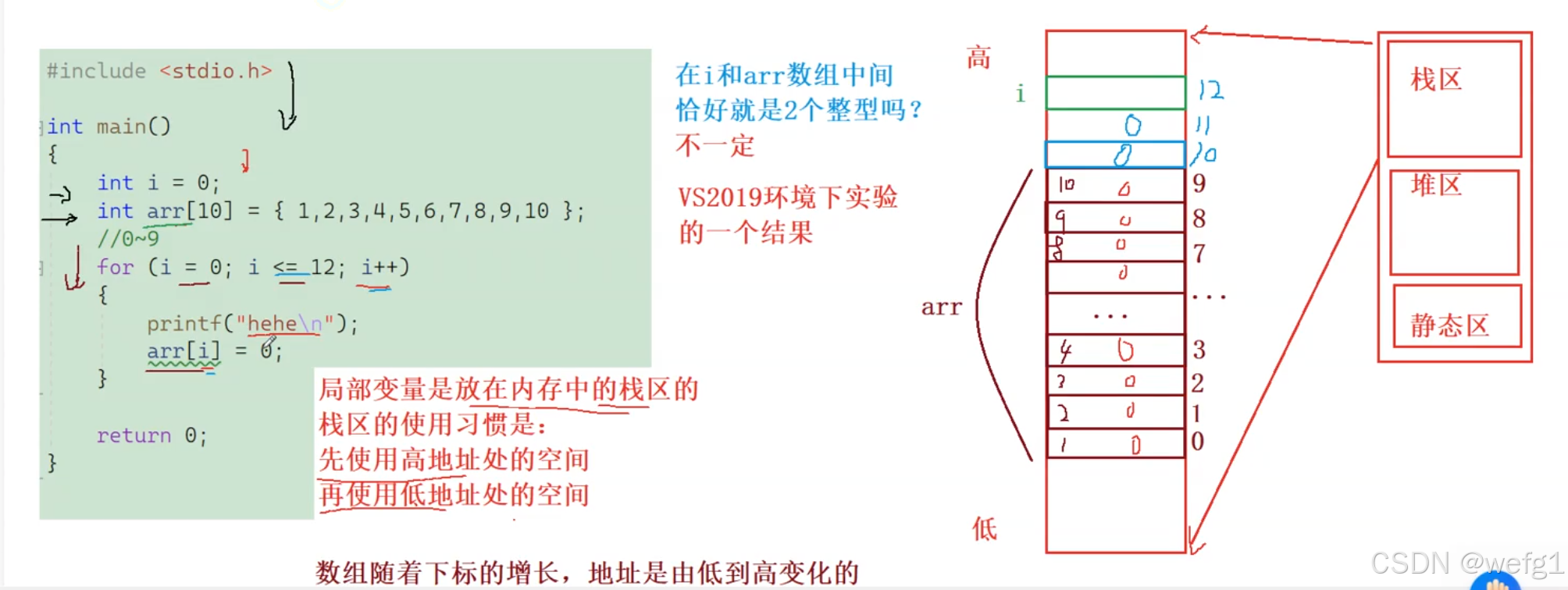
如果定义变量的时候不赋初值,那么这个变量不就是存储的 0CCCCCCCCh 吗。所以变量要初始化。变量存储空间之间相隔了几个字节取决于编译器(可能连在一起,也可能分隔)
如何传参
这是接下来的汇编代码:
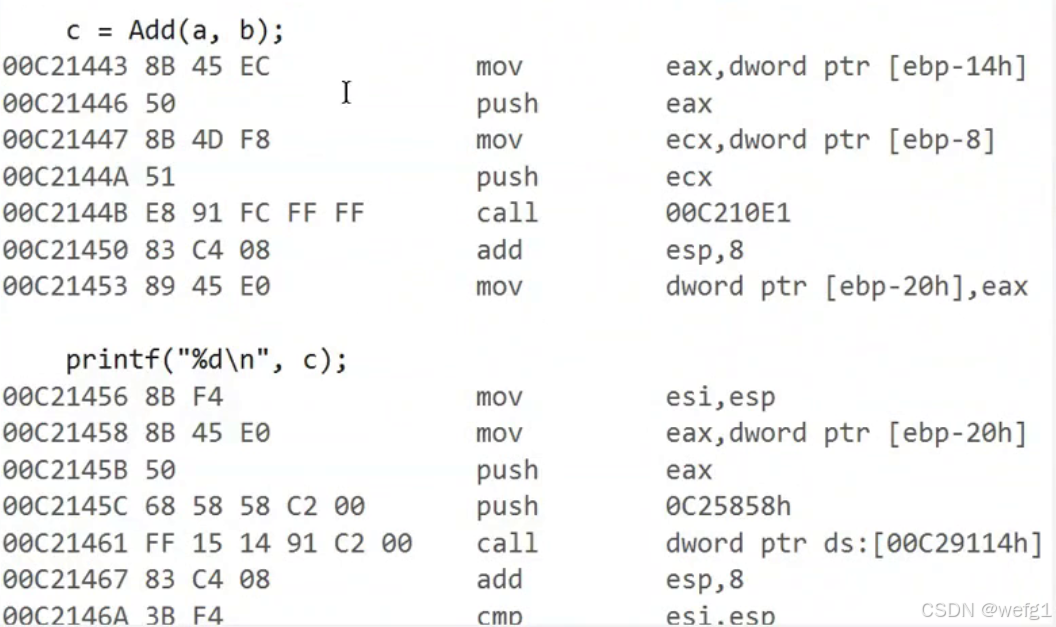
接下来执行:
mov eax, dword ptr [ebp-14h]
push eax
mov ecx, dword ptr [ebp-8]
push ecx
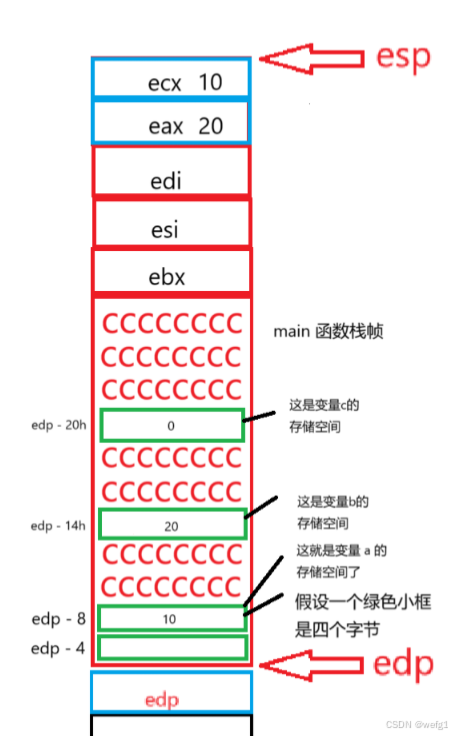
mov eax, dword ptr [ebp-14h] 的意思是将地址为 ebp-14h (变量 b 的地址)的存储单元存放的值(20)放在 eax 这个寄存器中,然后 push eax 即对 eax 压栈。mov ecx, dword ptr [ebp-8] 和 push ecx 同理。
这就是在传参了,我们看到,先传的是 b 的值,说明函数参数是从右向左传的。
接下来执行 call 指令(push ecx 的下一条指令):
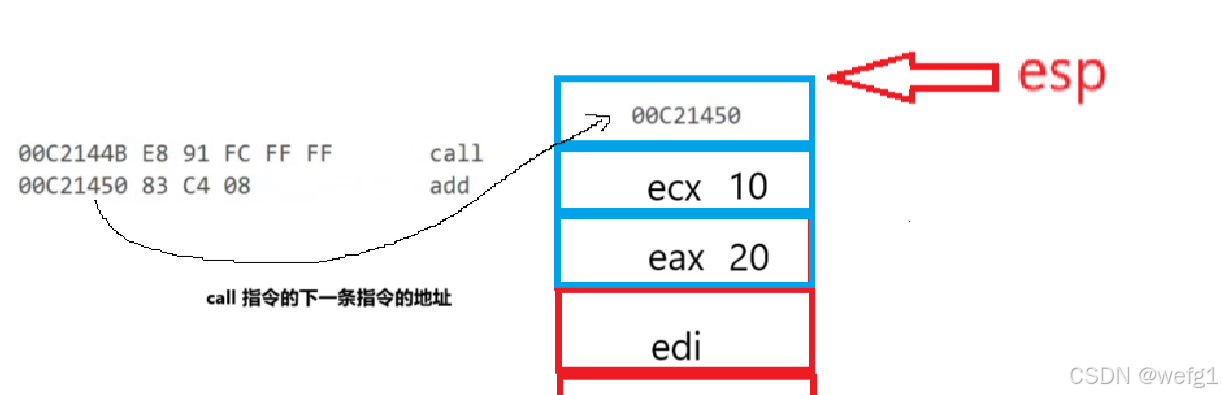
call 指令的作用是记住 call 指令的下一条指令的地址,以便在执行完 Add 函数后返回到 main 函数。
子函数栈帧的创建
调试时按下 F11 以进入 Add 函数,以下是 Add 函数的汇编代码:
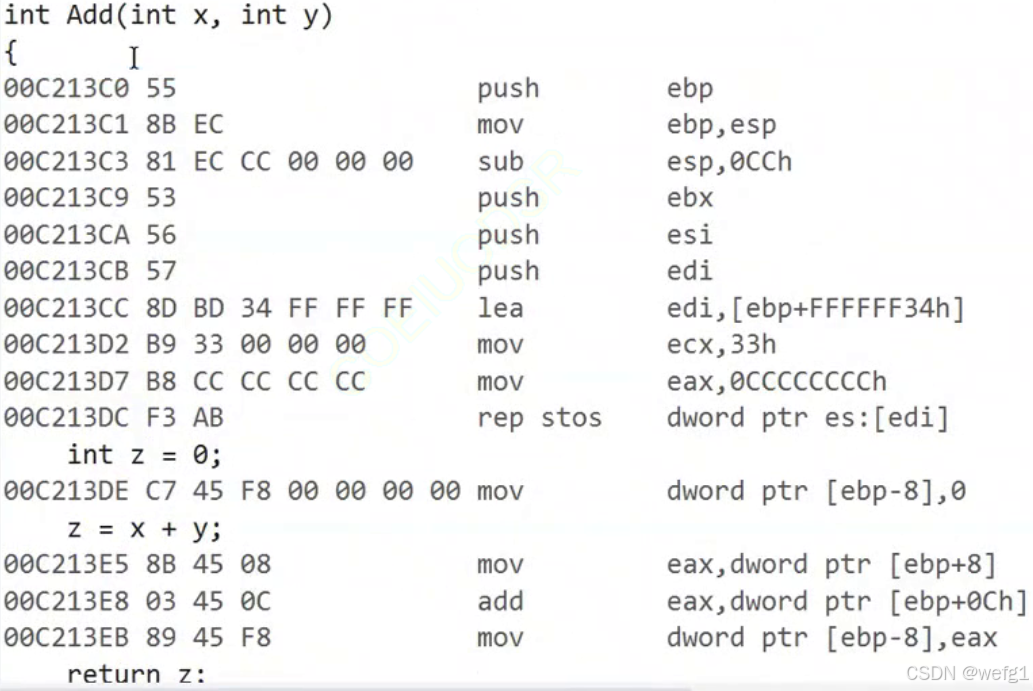
可以看到以上汇编代码的第一行到第十行与 main 的汇编代码的第一行到第十行很相似——为 Add 函数创建函数栈帧。
创建 Add 函数的栈帧的过程与创建 main 函数的函数栈帧的过程相似,执行以上汇编代码的第一行到第十行:
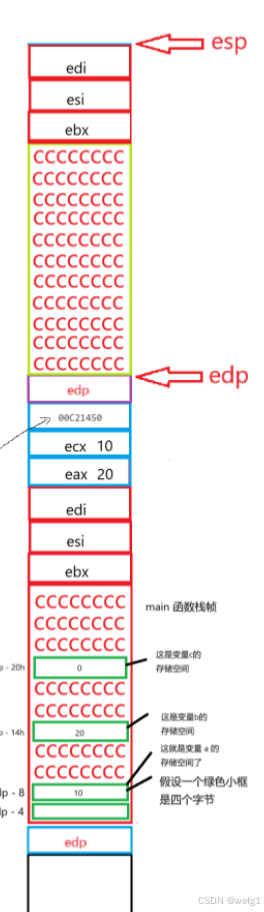
edp 和 esp 现在开始维护 Add 函数的栈帧了。
接下来执行:
mov dword ptr [edp - 8],0 (int z = 0;的汇编代码)
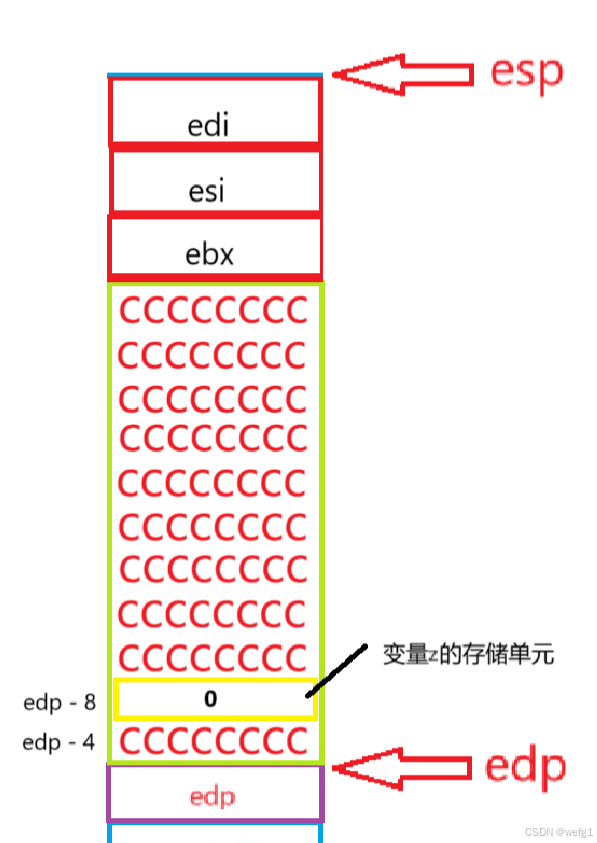
与创建变量 a、b、c时一样:mov dword ptr [edp - 8],0 的意思是将地址为 edp - 8 的存储单元存储的值改为 0 ,edp - 8 就是变量 z 的地址了。
接下来执行:
mov eax, dword ptr [ebp+8]
add eax, dword ptr [ebp+0Ch] // z = x + y;的汇编代码
mov dword ptr [ebp-8], eax
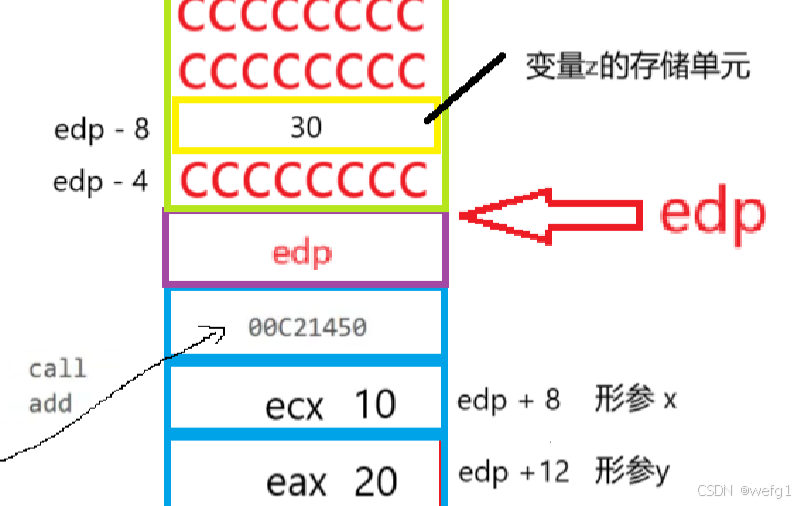
mov eax, dword ptr [ebp+8] :将地址为 edp + 8 的存储单元的存放的值(形参x)放在 eax 这个寄存器中。
add eax, dword ptr [ebp+0Ch] :与地址为 edp + 0Ch 的存储单元的存放的值(形参y)相加,结果放在 eax 这个寄存器中。
(0Ch 是十六进制数,十进制为12,add 是汇编代码指令,不是我们定义的函数 Add)
mov dword ptr [ebp-8], eax :将 eax 这个寄存器中存放的值放在地址为 edp - 8 的存储单元中(变量 z)。
这样,变量 z 就是 x + y 的值了。
函数如何返回值(1)
接下来应该返回 z 的值了,执行:
mov eax,dword ptr [edp - 8]
意思是将地址为 edp - 8 的存储单元的存放的值(变量 z)放在 eax 这个寄存器中
当退出 Add 函数后,变量 z 被销毁了,但 eax 寄存器仍然留存变量 z 的值。
子函数栈帧的销毁
这是接下来的汇编代码:

接下来执行:
pop edi
pop esi
pop ebx
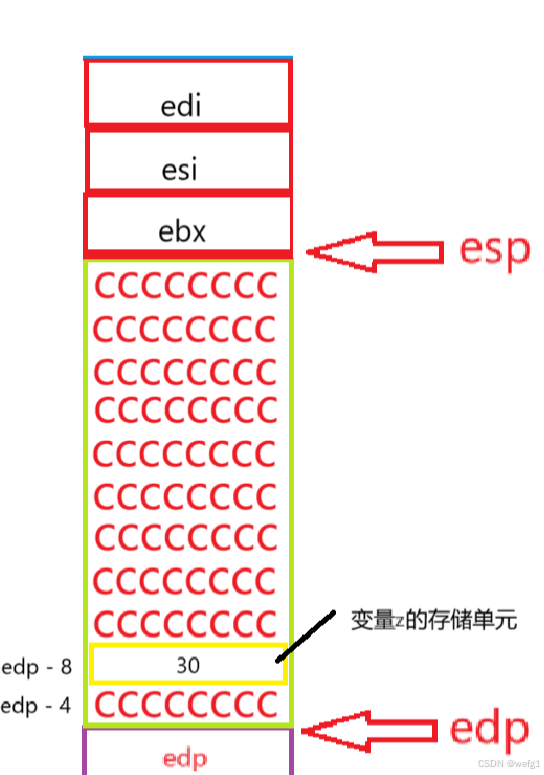
pop 就是出栈,esp向下移动
接下来执行:
mov esp,edp
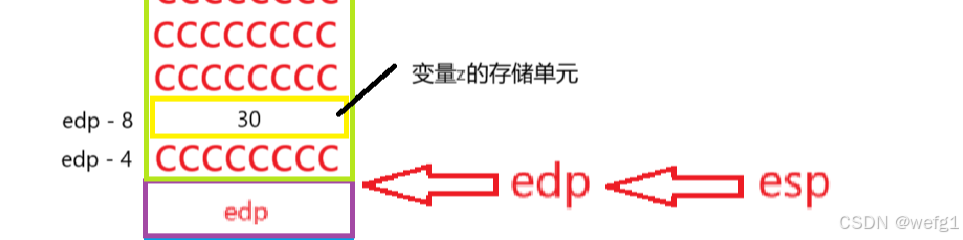
mov esp,edp 意思是将 edp 的值赋给 esp ,这样,edp 和 esp 指向一样。
接下来执行:
pop edp
这样,esp 和 edp 重新维护 main 函数了,Add 函数的栈帧被销毁了。
函数如何返回值(2)
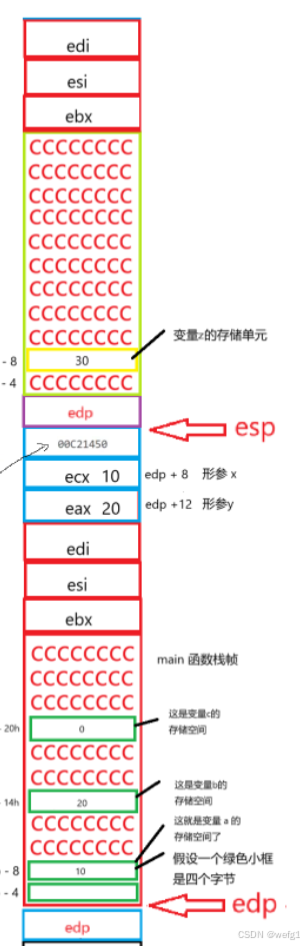
接下来执行 ret 指令,ret 指令的作用是让程序回到 call 指令的下一条语句(图中蓝色框),现在程序回到了 main 函数。
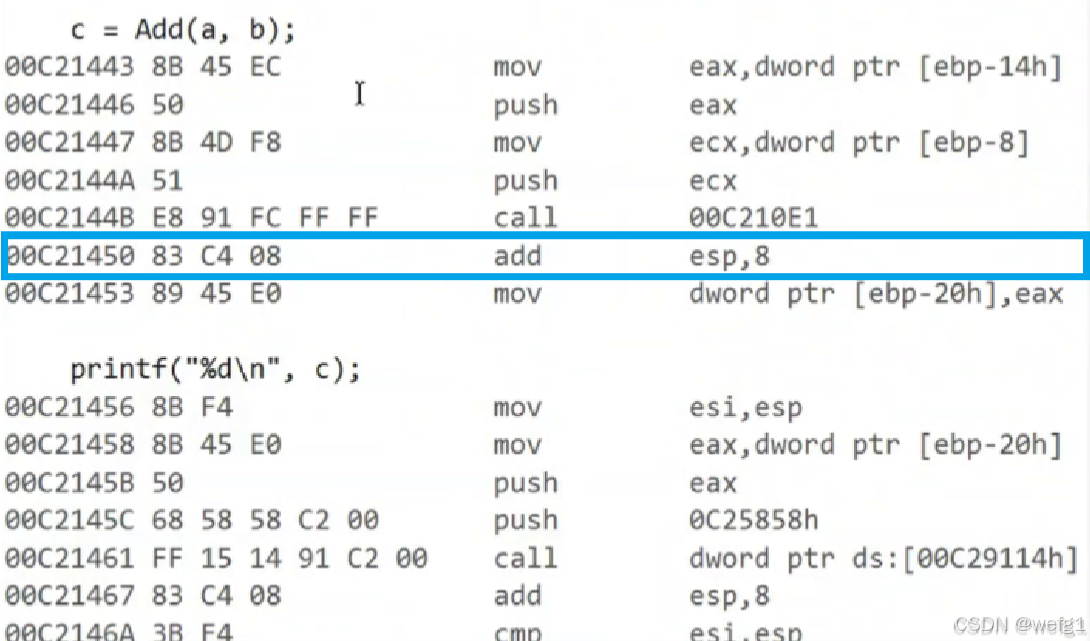
接下来执行 add esp,8
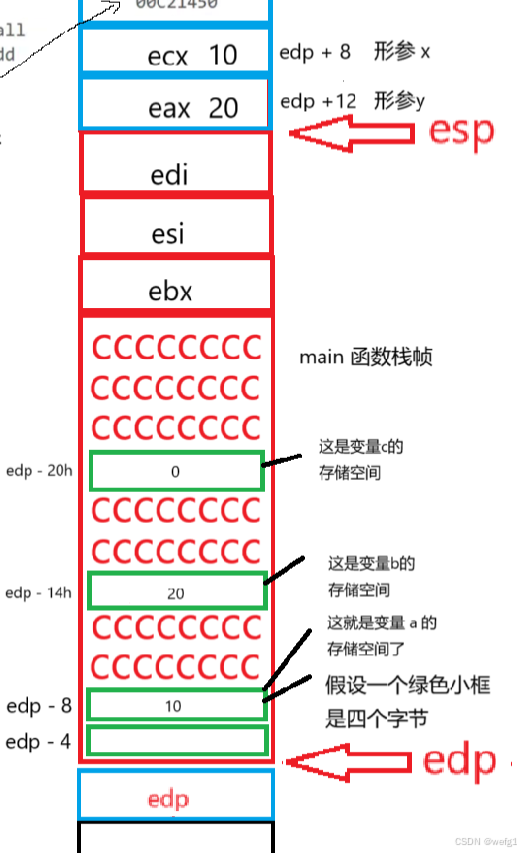
退出 Add 函数后,形参 x,y 没有用处了。add esp,8 的意思是让 esp 的地址增加 8 个字节,esp 现在的位置如上图所示。
接下来执行:
mov dword ptr [ebp-20h], eax
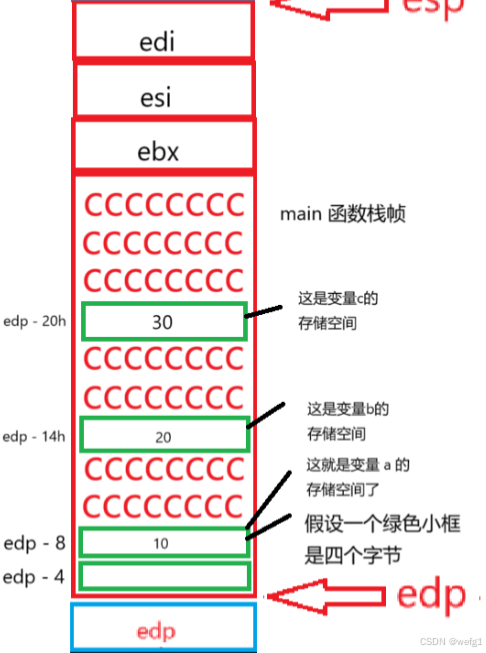
mov dword ptr [ebp-20h], eax 的意思是将寄存器 eax 存储的值(30)赋值给地址为 edp - 20h(变量 c 的地址)的变量中,这样 函数 Add 的返回值 z 返回到了 main 函数的变量 c 中。
总结:
函数返回值时,通常将返回的值先存储在寄存器中,等退出函数时,函数栈帧被销毁,此时待返回的值在寄存器中。在返回到的函数栈帧中,寄存器的值赋值给调用函数的表达式,作为该表达式的值。寄存器的大小通常只有 4 字节。
如果返回的值是静态的变量,那么该返回值仍会被存储到寄存器里去吗?
答案是不会,因为这样可以简化编译器的设计,编译器不想考虑多种情况,它想统一处理。
函数易错点
1、
返回指针的函数要小心!函数一旦返回值,该函数栈帧就不存在了,该函数占用的内存空间也还给了操作系统。
int* test()
{
int a = 10;
return &a;
//a 变量的存储空间已经还给了操作系统
}
int main()
{
int* p = test();
//print("hehe\n");//如果在打印*p前有其他代码,*p 的值就不一定是 10 了
printf("%d\n", *p); //虽然打印了 10 ,但这是侥幸的,因为 a 的空间没有被覆盖
return 0;
}
在打印 *p 之前调用了 printf 函数,这个 printf 函数的函数栈帧就可能还是使用 test 函数使用过的空间,就把 test 函数使用过的空间覆盖掉了,*p 的值就不确定了。
2、
main 函数调用并执行完一个函数后,再调用另一个函数,这两个函数是使用同一片函数栈帧空间
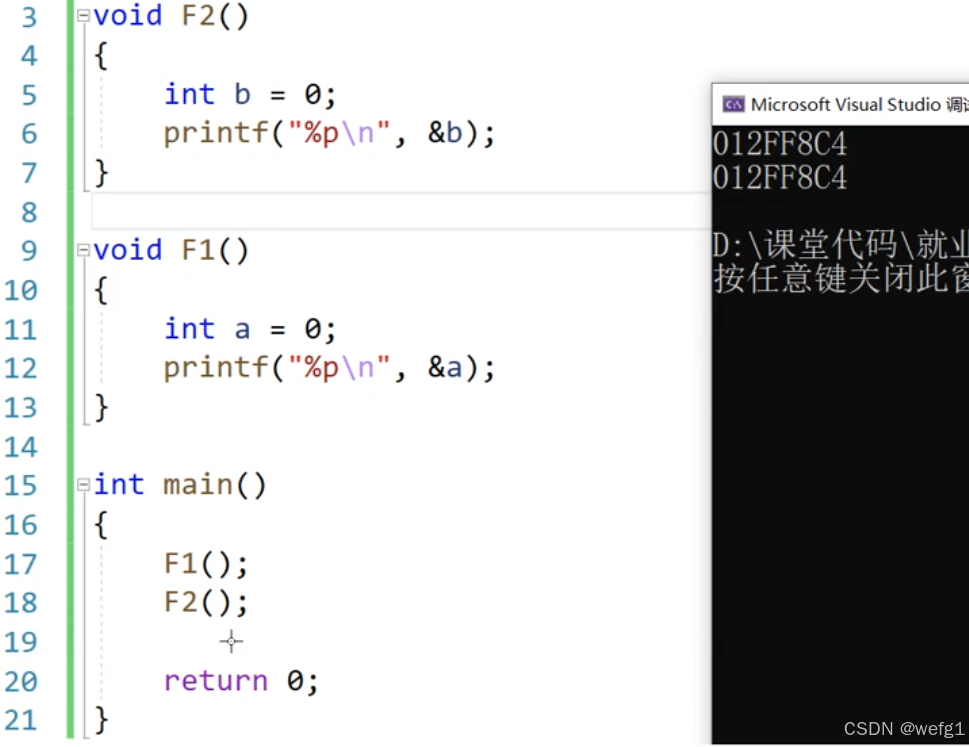
(F1 和 F2 使用同一片函数栈帧空间)
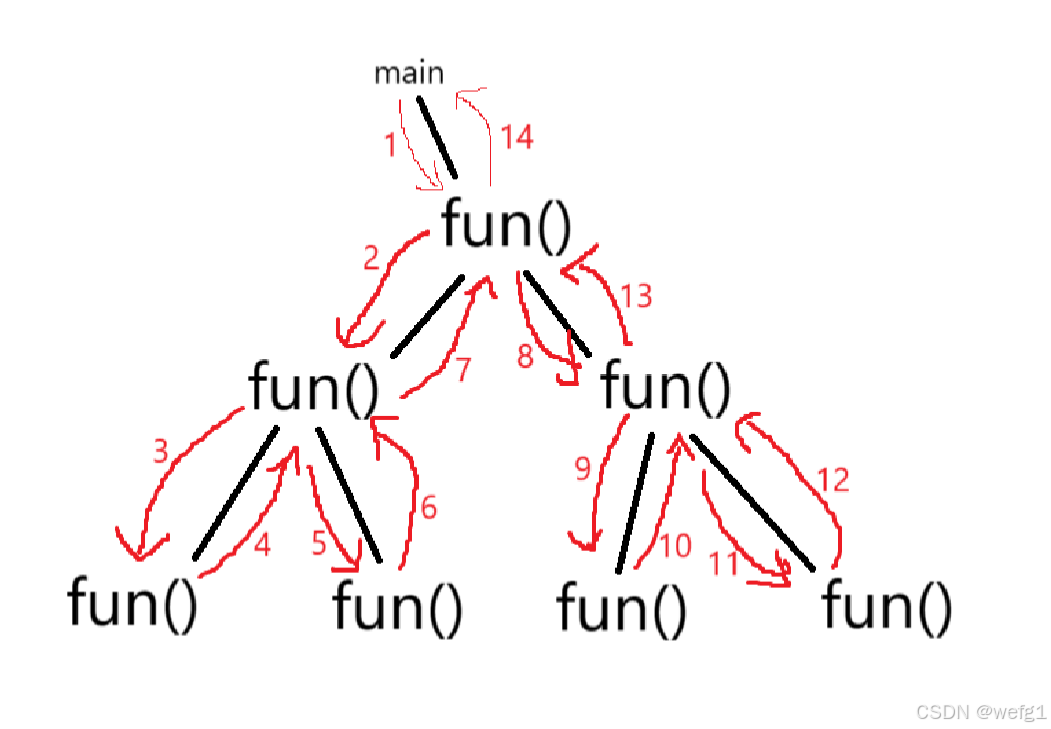
3、(斐波那契的函数递归调用顺序)

函数的递归调用顺序如何呢?Fib(N) 是同时调用 Fib(N-1) 和 Fib(N-2) 吗?正确的调用顺序:
虽然 Fib(N) 要调用 FIb(N-1) 和 Fib(N-2) ,FIb(N-1) 要调用 Fib(N-2) 和 Fib(N-3) ......,但是 Fib(N) 不是同时调用 FIb(N-1) 和 Fib(N-2) 的,是等 FIb(N-1) 返回值后再调用 Fib(N-2) 的,以此类推,FIb(N-1) 也不是同时调用 Fib(N-2) 和 Fib(N-3) 的。正确的调用顺序是:Fib(N) 先调用 FIb(N-1),FIb(N-1) 再调用 Fib(N-2) ......直到 Fib(2) 返回 1 给 Fib(3) 后,Fib(3) 再调用 Fib(1),Fib(3) 返回值给 Fib(4) 后,Fib(4) 再调用 Fib(2) ......,而 Fib(3) 调用 Fib(2) 和 Fib(1) 都是使用的同一片函数栈帧空间,所以当 Fib(N) 执行完后,一共开辟了 N 个函数栈帧空间。
示意图:

















 2152
2152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









