



社交媒体挖掘以理解公共心理健康
1 引言
社交媒体的许多应用涉及文本挖掘,例如了解用户兴趣、客户评论以及围绕新闻事件的情感。我们讨论了社交媒体文本挖掘在理解公共心理健康方面的应用。这是一个日益重要的应用领域:心理健康状况的普遍性在增加,同时我们拥有的用于理解这些状况的数据量也在增加[2]。尽管文本数据已被深度用于营销目的,但利用文本数据来理解公共心理健康仍存在巨大机会。
一些研究人员已将社交媒体数据(如推特帖子)确定为心理健康信号的宝贵来源[3,6]。然而,我们在理解心理健康方面仍存在关键的能力差距。人们可能不愿意公开分享心理健康相关内容,尤其是在与个人身份相关联的大型社交媒体平台上。
本文中,我们利用一款社交媒体应用的独特数据集进行心理健康分析,该应用用于发布日记条目、分享和追踪情绪(以下简称日记应用)。我们发现了在其他社交媒体上未被广泛讨论的问题,例如睡眠。此外,该日记应用要求用户在每次记录时追踪自己的情绪
日记。因此,我们拥有了用户标注的情感,否则这种情感很难估计。
通过将日记应用数据集与其他社交媒体(Reddit)进行比较,我们识别出情绪追踪社区所吸引的独特讨论。此外,日记数据集被分为两个部分:用户可以公开分享他们的日记,或将其保持私密。因此,我们能够了解哪些心理健康问题比其他问题更倾向于被公开分享。
我们试图回答的问题包括: 1. 日记数据集所涵盖的主题是否与其他社交媒体(如Reddit)上讨论的主题不同? 2. 某些主题是否比其他主题更倾向于公开分享?某些主题是否更倾向于保持私密? 3. 情感与主题之间有何关联?哪些主题会引发悲伤或快乐的感觉?
为了回答这些问题,我们采用文本挖掘方法从日记中提取主题。此外,我们利用已标注的情绪进行情感分析。总结来说,我们的贡献如下:
1. 我们对一个独特的日记及其相关情绪的数据集应用文本挖掘,该数据集此前尚未被研究过。我们发现了一组在其他社交媒体上不常见的心理健康主题。
2. 我们量化了哪些主题比其他主题更公开,以识别可用于分析公共心理健康的社交媒体数据中的空白。
3. 我们比较用户标注的情绪在不同主题间的差异,以识别需要关注的心理健康重要方面。
本文其余部分组织如下。我们在第2节中讨论背景与相关工作;在第3节中描述我们的数据集;在第4节中阐述我们的方法论,接着在第5节中展示我们的结果;最后在第6节中进行总结。
2 背景与相关工作
本文涉及两个研究领域的工作:社交媒体文本挖掘和公共心理健康研究。在文本挖掘背景下,存在一些标准的分析技术,可用于对社交媒体帖子进行主题建模和情感分析。在心理健康领域,这些技术已取得若干成功,包括检测在社交媒体上表达自杀念头的用户[11]。我们也使用了标准的主题建模技术,但将其用于在不同数据集之间进行新颖的主题比较。
心理健康研究传统上通过医疗专业人员收集信息,这一过程成本高昂,且仅能对公众的一小部分进行分析。哈曼等人[6]指出,利用社交媒体数据来理解心理健康具有重要意义。他们关注特定的心理健康状况,尽管发病率较低,但仍发现了一定的
社交媒体上的大量数据。他们得出结论,个体和群体层面的心理健康分析可以比当前方法显著更便宜且更高效。
传统的心理治疗和对心理健康状况的研究大量利用语言信号。在迪德里希等人[5],的研究中,通过使用聚类算法和情感分类器分析患者与其精神科医生之间的对话,采用文本处理来检测精神分裂症等心理健康状况。大多数利用医患数据的研究的缺点在于存在隐私问题以及数据集较小。由于数据规模有限,这些研究往往更具临时性。电子病历是心理健康数据分析的另一个重要机会。
例如,自然语言处理(NLP)已被用于基于电子病历提高对患者情绪状态中抑郁症的分类准确性[13]。
为心理健康数据创建社交媒体语料库可能会显著改善心理健康研究[2]。利用语言信号分析社交媒体中心理健康信号主要有两种方法。第一种方法依赖于包含词语内涵和强度的手工构建的词典。例如,语言查询词频(LIWC)词典已被用于帮助临床医生通过患者的文字了解其心理状态[6]。这种方法的缺点是,像LIWC这样的词典仅涵盖非正式语境(如社交媒体)中可能使用的语言的一小部分。
第二种常见方法是训练一个语言分类模型。当缺乏真实标签时,这种技术的应用会受到限制。现有研究尝试近似获取标签,其中一种保守标注方法是筛选那些自我识别患有某种疾病的用户。具体而言,先前的研究搜索了诸如“我被诊断出患有X”之类的语句[2]。然而,作者指出了这种方法存在的一些局限性。特别是,只有少数人会公开自我识别患有心理健康状况。尽管如此,通过语言模型,他们仍能够比较特定心理健康状况之间的语言使用情况[2]。
获取用于建模社交媒体文本标签的替代流程包括众包和开发定制应用程序[2]。众包涉及对用户进行调查。在之前的一项研究中,调查被用来研究本科生的心理健康趋势[4]。在我们的研究中,我们也发现与学校相关的问题(以及其他内容)是写日记者经常讨论的主题。尽管调查已取得一些成功,但让用户同意诚实地分享他们的个人信息较为困难,而且从受访用户那里收集社交媒体等其他数据可能成本较高。
另一方面,与社交媒体(如Facebook)交互的应用程序可用于收集个性信息并获取公开状态更新的访问权限。然而,对心理健康分析至关重要的信号通常不会在Facebook上分享。
尽管现有研究主要集中在传统社交媒体上,但在这些平台上讨论困难问题并不常见。另一方面,我们研究的数据集专门用于情绪追踪。该日记应用的目标是消除表达心理健康的污名。该平台完全匿名,因此包含了在个人身份可识别的社交媒体平台上通常被视为禁忌的主题。此外,该数据集结合了公开和私密日记,使得更私密的主题能够被频繁提及。
此外,我们选择更广泛地关注公共心理健康状况,而不是专注于特定的心理健康状况。我们证明了可以从我们的数据集中提取简单且可解释的信号。此外,我们使用用户标注的情感,以避免依赖自定义词典。
特别值得注意的是,我们最重要的发现之一是睡眠方面存在严重问题。在一项将睡眠问题与心理健康问题相关联的研究中发现,患者更容易察觉到自己的睡眠问题,并且比潜在的心理健康问题更愿意向医生透露[9]。此外,患者对睡眠问题的自我感知与健康问题密切相关,这表明人们能够准确识别真实问题的存在。尽管尚未开展利用社交媒体进行的大规模睡眠数据分析研究,但睡眠追踪移动应用和用于分析个人睡眠质量的工具正变得越来越普遍[7]。
尽管传统社交媒体帮助人们与朋友和家庭保持联系,但匿名社交媒体服务正被越来越多的人用于分享个人故事和寻求建议[14]。随着公众越来越习惯于在网上分享更多信息,这些社区不断壮大,并为那些无法或不愿亲自就医谈论心理健康问题的人提供了便利[14]。我们认为,这类数据集将对研究人员的分析变得愈发重要。因此,我们探讨了另一种匿名社交媒体平台Reddit,并比较了在Reddit上讨论的心理健康主题与日记应用中记录的心理健康主题。
3 数据
我们分析了两个数据集:(1)Reddit 上的用户社区,以及(2)一款心理健康日记类移动应用中的日记。出于隐私考虑,我们省略了该应用的名称,并将其称为“日记应用”。
Reddit 是一个社交媒体平台,最初用于分享和评分新闻、纪录片和音乐等内容。用户可以在自组织的社区(称为子版块)中发帖和订阅;订阅某个子版块后,用户即可查看该子版块中的所有帖子。分析 Reddit 数据的一个优势是,子版块会根据其主题进行标注。我们利用志愿者 Reddit 用户整理的列表,爬取了所有与心理健康相关的子版块,以及这些社区链接的所有其他子版块。
第二个数据集包含来自一款移动应用的匿名日记帖子,该应用旨在帮助用户追踪自己的情绪,并在需要时匿名分享。对于每篇日记帖子,应用要求用户从预设的情绪列表中至少选择一个情绪标签,例如“快乐”,
“悲伤”等。我们获取了2016年1月至2017年1月期间撰写的所有日记及其相关的情绪。这总计超过120万篇日记,由约7.5万名用户撰写。
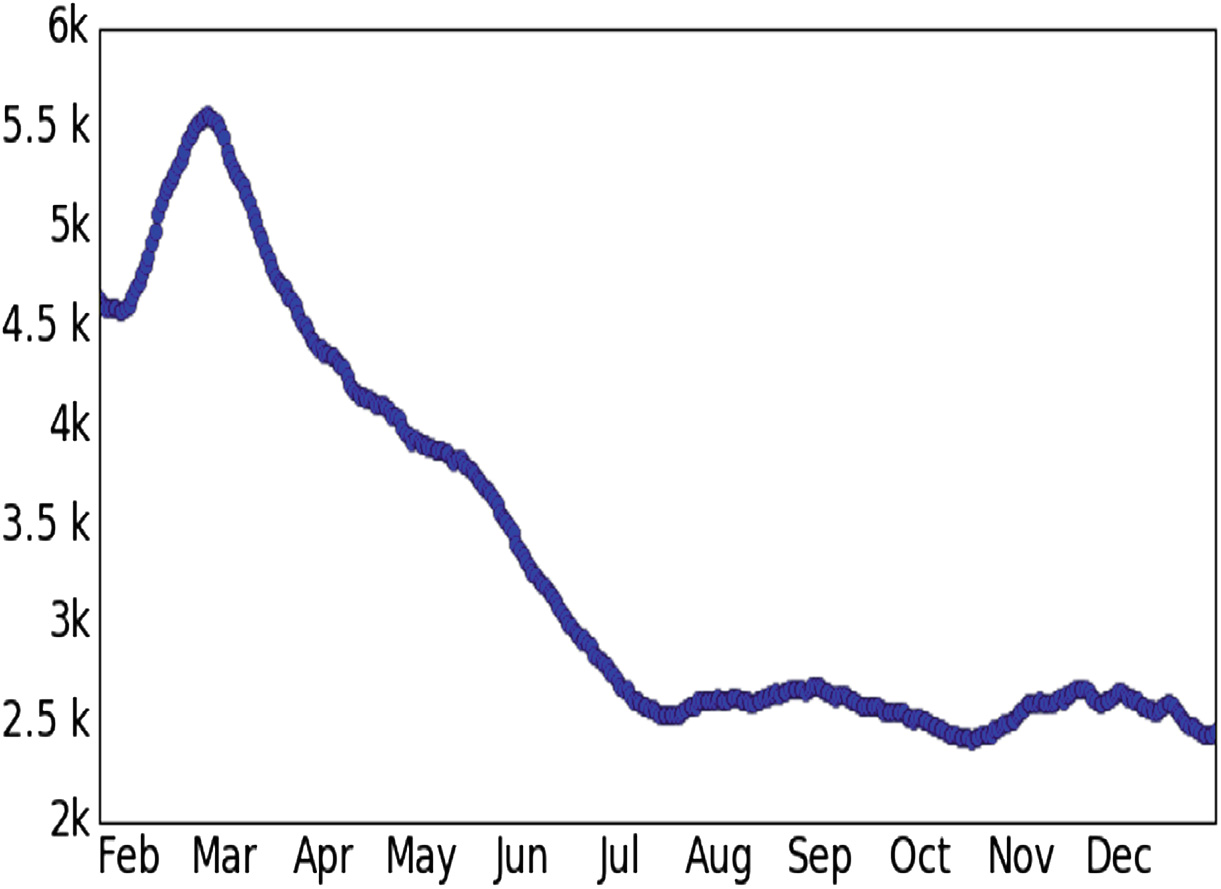
图1展示了随时间推移发布的日记数量。大多数日记写于2016年上半年,尽管我们检查了每月的主题分布,但未发现季节性效应。在2016年初,许多新用户注册了该应用程序,但最终停止使用。类似于减肥和效率类应用程序,我们认为这一涌入现象与用户希望通过新年决心改善自身习惯有关。
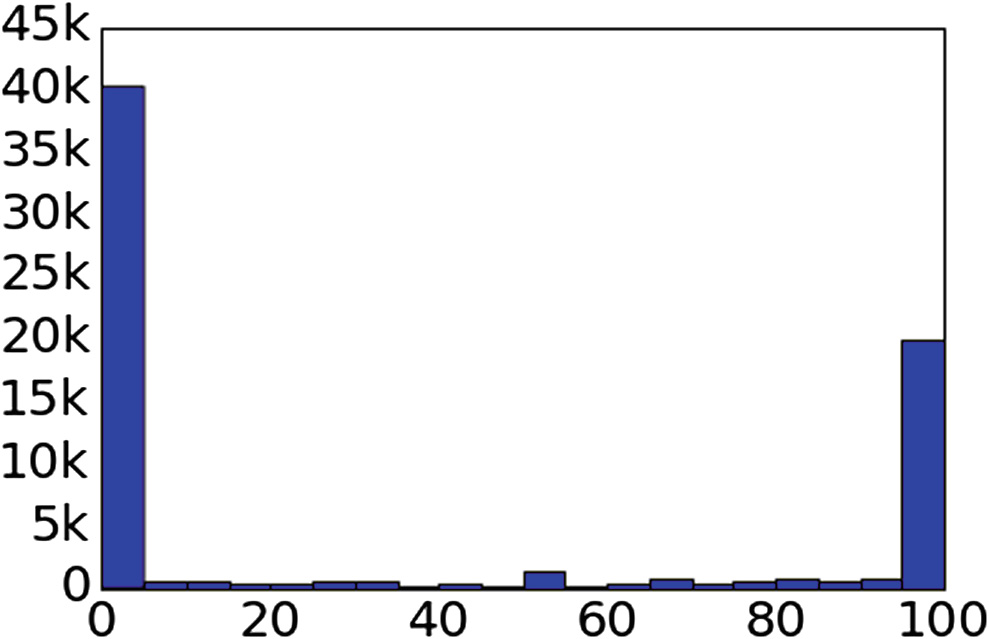
每篇日记可以设置为私密或公开(对应用程序的所有其他用户可见)。大约三分之一的日记是公开的。图2在y轴上绘制了用户数量与他们发布的公开日记百分比之间的关系。大多数用户要么主要是私密的,要么主要是公开的。
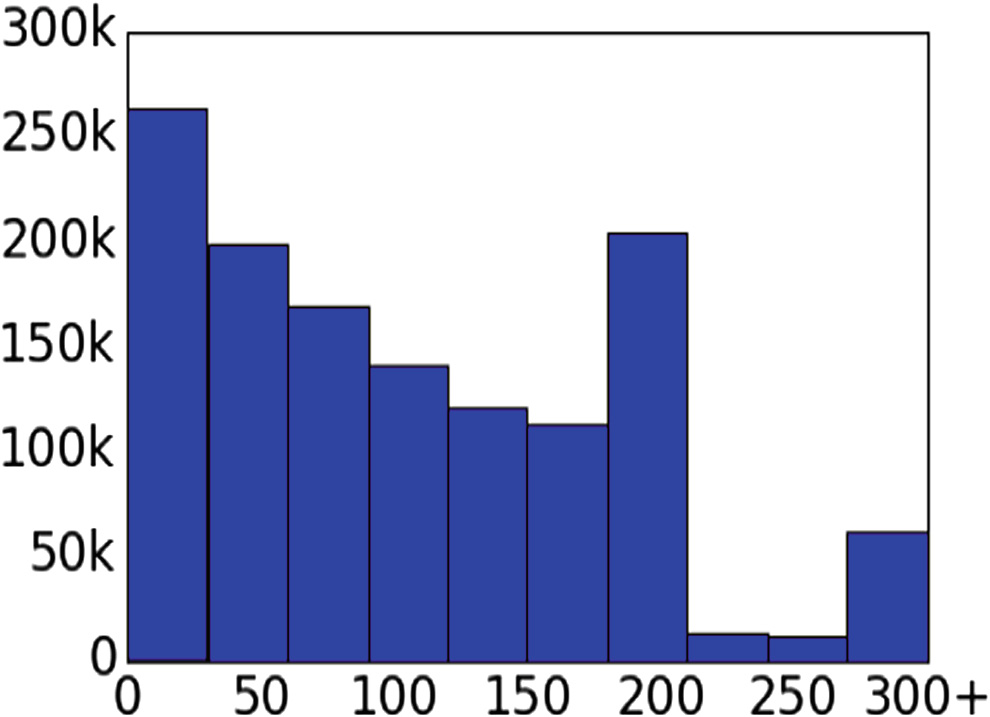
大多数日记相对较短,就像最多140个字符的推特帖子一样。包含文本的日记平均长度为128个字符;大约有10万篇日记没有文本内容,仅有情绪标签。我们观察到,私密用户所写的日记比公开用户所写的日记略长,且在统计学上具有显著性差异,大约多出10个字符。图3显示了日记长度的分布情况,其中峰值对应于0长度(仅情绪标签)、200个字符(应用程序设置的默认限制)和300个字符(为可视化目的设定的最大值)。
用户可选择性地输入其位置、年龄和性别。尽管大多数用户未填写这些信息,但我们发现,提供位置信息的用户主要来自北美,提供性别信息的用户以女性为主,而提供年龄信息的用户平均年龄25岁。
4 方法论
本分析的目标是通过挖掘社交媒体来理解公共心理健康。我们希望识别在公开场合(Reddit及日记应用中的公开日记)和私密场合(私人日记)讨论的常见话题。对于Reddit数据集,我们只需统计每个与心理健康相关的子版块的订阅者数量,以发现热门话题和问题。需要注意的是,每个子版块均已标注其主题,因此无需进行主题建模。另一方面,对于日记应用,每篇日记帖子标注了情绪但未标注主题。下文将描述我们将主题分配给日记的方法论。
4.1 主题建模
首先,我们删除了无文本的日记以及少于20个字符的日记1,留下110万篇日记用于主题建模。
接下来,我们使用斯坦福推文分词器对文本进行预处理,这是一种专为处理简短、非正式文本而设计的“推特感知”分词器[1]。我们启用了将重复3次或以上字符进行截断的选项,将诸如“I’m sooooo happyy”之类的短语转换为“I’m soo happyy”。平均而言,每篇日记的标记数量为27.7个。
由于我们关注的是主题,因此移除了停用词和少于两个字母的标记,并仅保留了出现在WordNet语料库[10]中的名词。经过此过滤后,每篇日记中的名词平均数量为7个。
频繁出现的名词示例按字母顺序排列,包括“anxiety”、“class”、“dinner”、“family”、“god”、“job”、“lunch”、“miss”、“school”、“sick”、“sleep”和“work”。随后,我们迭代地将日记聚类为主题(细节如下),并移除了不表示主题的名词,例如数字、时间(如“today”、“yesterday”)、一般性感觉(如“feel”、“like”)、专有名词以及具有模糊含义的名词(如“overall”、“true”)。最后,我们仅保留了在数据集中出现超过十次的名词。此过程生成了一个包含8386个词的词汇表用于主题建模。每篇日记被表示为一个8386维的词频向量,每个分量表示对应术语的词频/逆文档频率(TF-IDF)。
算法1总结了我们的主题建模方法论。对于每篇日记的TF-IDF词频向量,
我们运行Python的scikit-learn包中实现的非负矩阵分解(NMF)[8], implemented in Python’s scikit-learn package[12]。非负矩阵分解的目标是找到两个矩阵,其乘积可近似原始矩阵。在本例中,其中一个矩阵表示每篇日记中的主题的加权集合,另一个矩阵表示每个主题所包含的词语的加权集合。因此,每篇日记被表示为主题组合,而每个主题本身由词语的加权组合构成。
1我们手动检查了一部分短篇公开日记,发现少于20个字符的日记通常只是重新陈述了用户的情绪,并未涉及任何具体主题。
表1. 最终的日记主题列表,显示了每个主题的前6个词。我们根据高频词手动分配了主题名称。
| 主题 | 词1 | 词2 | 词3 | 词4 | 词5 | 词6 |
|---|---|---|---|---|---|---|
| Work | work | focus | 钱 | meeting | 星期五 | 移动 |
| Love | love | 心脏 | man | fall | 世界 | 物质 |
| 学校 | 学校 | high | 休息 | 夏天 | test | 无聊 |
| 睡眠 | sleep | wake | 睡觉 | 头痛 | 小睡 | 醒来 |
| 疾病 | sick | 胃 | cold | 头痛 | 喉咙 | 恶心 |
| 想念某人 | miss | old | baby | text | 心脏 | 次数 |
| 家庭 | family | 圣诞节 | 支出 | 健康 | food | 丈夫 |
| 职业与财务 | job | 面试 | 钱 | call | move | 提议 |
| 晚餐 | dinner | ate | 电影 | 晚上 | 购物 | 散步 |
| 身体疼痛 | pain | 头痛 | 经期 | 空虚 | body | 胃 |
| 家庭作业 | 完成 | 作业 | test | due | 休息 | room |
| 焦虑/抑郁 | 焦虑 | 抑郁发作 | high | 压力 | 恐慌 | |
| 学校(活动) | 班级 | test | yoga | 舞蹈 | 英语 | 老师 |
| 餐食 | 午餐 | ate | food | 吃 | 休息 | 早餐 |
我们选择非负矩阵分解,因为其非负性约束有助于提高可解释性。在分析词频的背景下,词语的负向出现将无法解释,因为我们仅追踪词语的出现情况,而不涉及语义或句法。与其他矩阵分解方法不同,非负矩阵分解通过正的部分之和来重构每篇文档,这使得我们能够轻松地手动标注发现的主题。
从4到40个主题进行迭代,我们得到了37个不同的主题矩阵(算法1的步骤1和2)。每个矩阵每行对应一个主题。每个主题对词汇表中的每个词都有一个正权重。权重越大,表示该词与主题的相关性越高。我们最终使用的是包含14个主题的主题矩阵,如表1所示。为简化起见,表中仅列出每个主题相关性最高的前六个词,并按相关性从高到低排序。
在判断主题矩阵时,我们考虑了每个主题中最重要的前二十个词。利用这些信息,我们手动为矩阵中的每一行标注了相应的主题。此外,我们根据主题间的区分度、主题内的一致性以及可解释性,对手动评估了每个矩阵。在此过程中,我们整理了本节前面提到的自定义的移除词列表。我们删除的词组以独立主题的形式出现,无法提供关于日记内容的信息。例如,专有名词作为独立主题出现。其他我们认为过于通用或模糊的词出现在多个主题中,因此无法提供区分性信息。
我们注意到,默认情况下,非负矩阵分解不会强制要求将词语的非零权重仅分配给一个主题。通过使用我们的剪枝过程,我们确保了那些出现在过多主题中的词语被移除。我们允许词语具有多种含义的词(例如“high”)以及在不同语境下使用的词(例如瑜伽“class”与学术“class”)。我们注意到,每个主题中最重要的词(基于权重)通常没有重叠,只有“ate”是例外。我们在第4.2节中概述的验证过程确保了“晚餐”和“餐食”这两个主题确实是不同的,尽管它们都对“吃”赋予了较高的权重。
我们测试了不同级别的正则化以在模型中强制实现稀疏性(参见[8]的讨论),但未发现显著差异。然而,我们对每个主题进行正则化的一个重要修改是使其第一个词的强度仅与第二个词相当(默认情况下,第一个词比第二个词强,第二个词又比第三个词强,依此类推)。这是因为每个主题最相关的词往往信号过强,无论我们如何改变主题数量、预处理流程或目标函数中的正则化方式。例如,在一篇关于体育的日记中,“love”一词的信号会过于强烈,导致该日记被错误地标记为与爱情相关。降低第一个词的重要性足以消除我们识别出的这些误报情况。
根据最终的主题矩阵(见表1),下一步是利用该矩阵为日记分配标签(算法1的步骤3和4)。我们绘制了每个主题在数据集所有日记中的重要性分布,重要性范围从0到1。每种分布的形状相似,在0.05至0.15的重要性区间内存在一个明显的拐点。图4展示了“工作”这一主题的一个示例重要性分布,其拐点出现在0.1的重要性处。
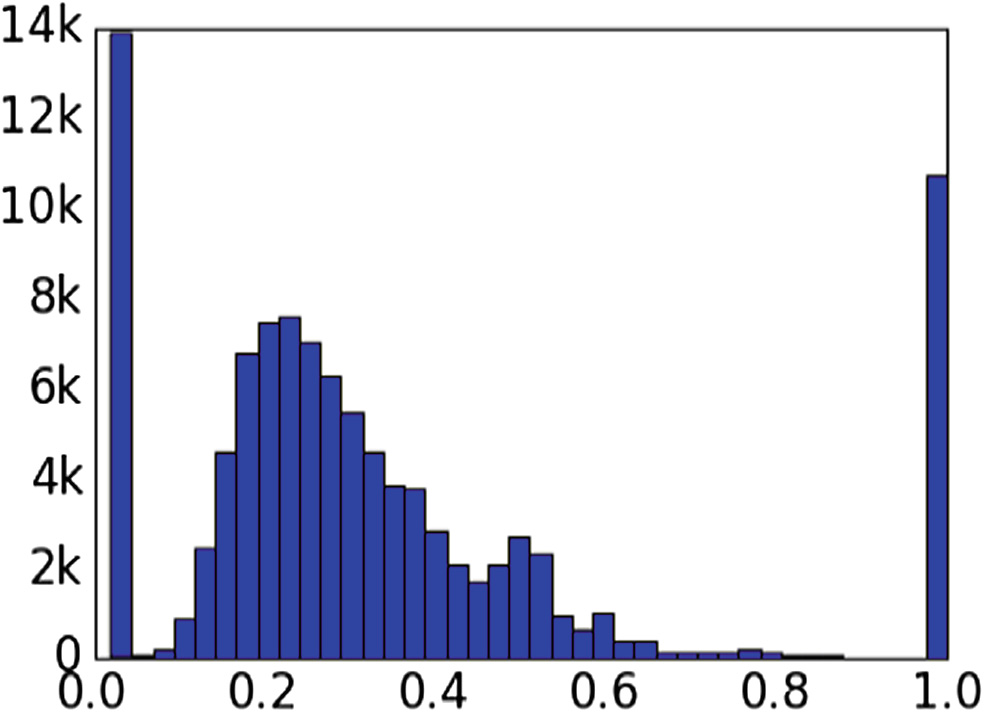
我们使用这些拐点为每个主题设置重要性的最小阈值。我们忽略低于阈值的任何主题分配。然后,我们获取每篇日记中的前两个主题(如果有的话)。由于日记通常较短,我们选择每篇日记最多两个主题。
通过这一主题建模过程,我们为43万(占所有可用日记的35%)的日记分配了至少一个主题。其中,包含一个主题的日记数量为33.4万,而有9.6万的日记包含两个主题(上限)。
4.2 验证
为了评估我们主题建模方法论的有效性,我们为每个主题随机选择了60个公开日记的子集,以及100个未分配主题的公开日记。我们手动标注了这些抽样的日记,寻找14个可用主题之一、无主题或“其他”主题。包含“其他”类别使我们能够验证我们手动标注的主题名称列表是否准确且完整。然后,我们将我们的标注结果与模型分配的结果进行比较。对于模型分配了两个主题的日记,只要其中一个分配的主题与我们手动选择的主题一致,我们就认为模型正确。表2显示了我们模型的主题准确率。总体而言,我们的模型表现良好,平均准确率远高于80%。
没有主题的日记长度要短得多。没有主题的日记平均长度为114个字符,有一个主题的为142,两个主题的为185。人工检查确认,这些日记确实有超过70%的时间不包含任何主题,而是主要包含情绪标签中已有的情感内容。
本节最后,我们指出分析了诸如2016年美国大选等重大事件前后的活动情况。我们未发现所提及主题存在统计学上的显著异常,因为我们提取的主题大多与日常活动相关。
社交媒体挖掘以理解公共心理健康
5 结果
本节展示了我们的分析结果。需要提醒的是,输入数据包括:(1)订阅了各种与心理健康相关子版块的Reddit用户数量;(2)来自日记应用的日记,每篇日记均标注有时间戳、情绪(由用户填写)、可见性(公开 vs. 私密;由用户设置)以及最多两个主题(由我们的主题建模算法分配)。
5.1 Reddit、公开日记和私密日记中的常见心理健康主题
我们首先将Reddit上常见的订阅主题与日记应用中公开和私密讨论的常见话题进行比较。表3显示了最受关注的心理健康相关子版块。表4列出了我们在日记应用中识别出的14个主题的各项统计数据,包括:
– 快乐百分比,对应情绪为“快乐”的日记所占的百分比。– 公开百分比,对应可见性设置为公开的日记所占的百分比。
表3. Reddit上订阅者最多的与心理健康相关的社区。
| 子版块 | 订阅者 |
|---|---|
| 抑郁症 | 17.4万 |
| 焦虑症 | 11万 |
| ADHD | 70k |
| 自杀监控 | 53k |
| 戒烟 | 46k |
| 心理健康 | 26k |
| 阿斯伯格综合征 | 22k |
| 约会 | 21k |
| 职业指导 | 21k |
| BPD | 17k |
| 双相情感障碍 | 16k |
| OCD | 12k |
| 睡眠 | 12k |
| 进食障碍 | 9k |
| 失眠 | 9k |
| 酒精中毒 | 8k |
| 高中 | 4k |
| 家庭 | 2.5k |
表4. 日记应用的主题统计。
| 主题 | 幸福感 (%) | 公开性 (%) | 日记 (1000s) | 用户 (1000s) | 平均长度 |
|---|---|---|---|---|---|
| 晚餐 | 83 | 21 | 20 | 7 | 143 |
| 餐食 | 80 | 26 | 8 | 4 | 100 |
| 学校(活动) | 68 | 30 | 16 | 6 | 136 |
| Work | 64 | 31 | 86 | 21 | 147 |
| 疾病 | 36 | 32 | 23 | 9 | 118 |
| 学校 | 58 | 32 | 39 | 12 | 140 |
| 家庭作业 | 63 | 32 | 11 | 4 | 124 |
| 身体疼痛 | 38 | 33 | 16 | 7 | 124 |
| 家庭 | 66 | 34 | 23 | 10 | 155 |
| 想念某人 | 43 | 35 | 18 | 8 | 142 |
| 睡眠 | 43 | 36 | 35 | 14 | 135 |
| 职业与财务 | 57 | 37 | 19 | 8 | 142 |
| Love | 70 | 38 | 58 | 17 | 154 |
| 焦虑/抑郁 | 38 | 42 | 17 | 7 | 147 |
在浏览Reddit上与健康相关的社区时,我们立即注意到,与日记数据集相比,身体健康(锻炼、减肥)是一个更大的主题。这可能是因为还有其他应用程序可用于追踪锻炼情况。另一方面,考虑到Reddit庞大的用户群体,专注于心理健康的社区相对较小。自我识别为抑郁症的是最大的关注心理健康状况的子版块,在日记数据集中,这也是一个常见主题。此外,Reddit还包括一些较小的社区,例如“高中”、“睡眠”和“家庭”,这些对应于日记数据集中发现的重要主题。值得注意的是,患有注意力缺陷多动障碍的人在Reddit上形成了一个非常大的社区,这在日记数据集中并不是一个主要主题,因此可能为对注意力缺陷多动障碍感兴趣的研究人员提供一个独特的数据集。
在 Reddit 上,与睡眠相关的社区规模很小,而在日记数据集中,睡眠是一个主要主题。睡眠是日常必需的需求,对情绪至关重要,而这正是日记应用旨在追踪的内容。睡眠是第三大常见主题,并且如后文所述,其情感倾向相对负面。通过对随机子集的公开日记进行人工检查发现,关于睡眠的提及主要并非与失眠相关。相反,我们发现大多数关于睡眠的提及包括对睡眠质量的评论、因疲惫而期待入睡,以及(非慢性)睡眠不足的情况。
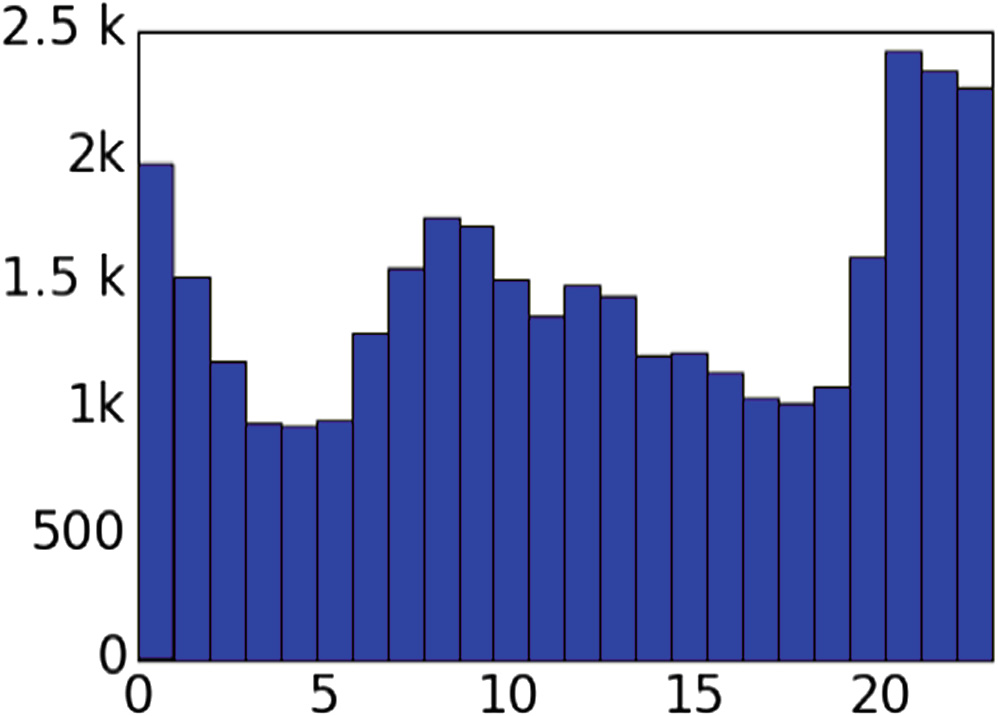
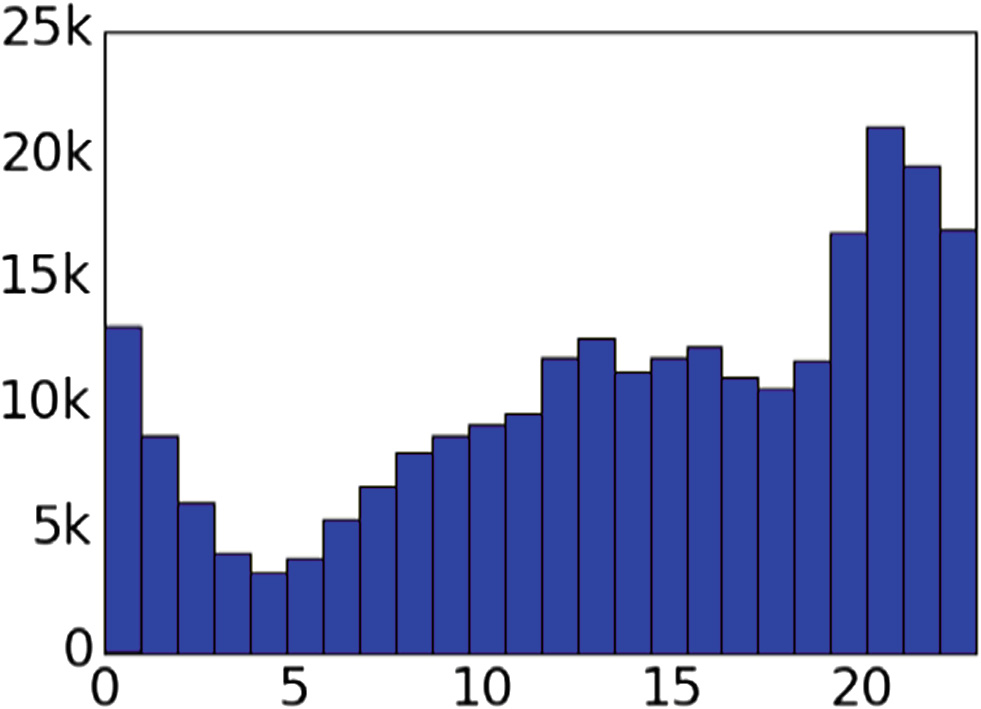
为了进一步了解用户如何记录他们的睡眠情况,我们分析了提及睡眠的日记的时间分布。图5和图6显示了2016年发布的所有日记中,与睡眠相关和非睡眠相关的日记在一天中各时段的撰写时间。睡眠仅在早晨被提及,而其他所有主题的分布则非常相似(“Dinner”在当天较晚时候被提及,为清晰起见已将其移除)。这与我们的人工检查结果一致:睡眠通常在常规睡眠时间之前以及醒来后的早晨被提及。
此外,Reddit 的社区未能恰当地解决影响日记数据集中人群的具体问题,包括家庭和与学校相关的压力。同时,尽管存在一个大型的子版块提供职业建议,但它并未专门针对日记数据集中提到的工作相关压力和职场冲突。
5.2 日记情绪与可见性分析
总体而言,所有日记中有三分之一是公开的。根据表4,我们发现社交媒体在表达日常活动以满足我们的社交需求方面存在不足。特别是“晚餐”和“餐食”这两个主题,被设为公开分享的频率不到30%。通过对随机抽取的公开日记样本进行人工检查发现,标记为“晚餐”主题的日记通常涉及约会和家庭聚会。而“餐食”主题的日记通常是较短的记录,用于追踪吃了多少以及饮食是否健康。通过创建一种私密媒介,日记应用帮助人们反思这些时刻。
另一方面,有35%或以上用户公开分享的更多主题包括“想念某人”、“睡眠”、“职业与财务”、“爱情”和“焦虑/抑郁”。其中,焦虑症和抑郁症被公开讨论得最多,这表明用户在日记应用中对自己的心理状态感到意识清晰且乐于分享。相比之下,这些主题通常不会出现在传统社交媒体上,因为围绕这些话题仍存在污名。
表4还包含用户标注的每个主题的平均情绪。尽管大多数主题的情绪普遍较为积极,但有些主题却出乎意料地消极。最令人惊讶的是,“睡眠”与“想念某人”一样负面,只有43%的日记情绪为快乐,而整个数据集的平均快乐情绪为60%。“晚餐”和“餐食”则特别积极,恰好也是最私密的主题。
6 结论
在本文中,我们使用文本挖掘技术分析了一个独特的公开与私密日记数据集,以理解公共心理健康。我们揭示了影响用户的核心主题。基于用户标注的情绪,我们分析了情感倾向,发现最私密的主题具有最积极的情绪。尽管焦虑症和抑郁症属于情绪非常低落的主题,但它们经常被公开分享,表明在匿名环境中,围绕这些问题的污名可以得到缓解。
通过比较公开和私密日记,我们确定了哪些主题比其他主题更常被分享,识别出当前社交媒体分析中尚未涵盖的新主题。诸如用餐之类的日常话题被用户保留为私密。在整个数据集中,大多数日记和主题大多是私密的,这表明传统社交媒体无法满足用户在这些时刻表达情绪的需求。
我们还将日记应用与Reddit(另一个用于匿名分享的服务)进行了比较。我们发现,Reddit上缺少心理健康主题,例如家庭、学校和工作相关问题,这可能是因为人们在公共论坛中讨论这些问题会让人感到不适,即使是匿名也是如此。我们认为这一用户群体存在尚未满足的需求。未来的社交媒体服务或许可以提议一个讨论这些问题的场所,并让人们有足够的舒适感来公开表达他们的情绪。
一个有趣的发现是,睡眠是日记数据集中的一个重要主题。该主题在睡觉前后被频繁提及。睡眠表现出出乎意料的负面情绪,其程度可与想念某人这一主题相比较。睡眠是一种日常活动,对情绪有重大影响,并且会受到压力等外部因素的影响。因此,睡眠监测数据对于理解公共心理健康至关重要。
在未来工作中,我们计划收集更多数据,以更详细地分析与睡眠相关的问题。例如,推特数据为研究每日发帖用户的睡眠模式提供了机会。

















 4181
4181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









