




ICLR 2025 poster
奖励塑造是一种强化学习技术,它通过提供频繁的、信息丰富的反馈来解决稀疏奖励问题。我们提出了一种高效的自适应奖励塑造机制,该机制使用从历史经验中导出的成功率作为塑造奖励。成功率从 Beta 分布中采样,随着数据的积累,Beta 分布从不确定性演变为可靠性。最初,塑造奖励是随机的,以鼓励探索,逐渐变得更加确定以促进利用,并在探索和利用之间保持自然的平衡。我们应用核密度估计 (Kernel Density Estimation, KDE) 与随机傅里叶特征 (Random Fourier Features, RFF) 来推导 Beta 分布,为连续和高维状态空间提供了一种计算高效的解决方案。我们的方法在具有极稀疏奖励的任务中得到了验证,与相关基线相比,提高了样本效率和收敛稳定性。
文章脉络非常清晰,首先提出基于历史轨迹中状态成功率线性映射为一个在[r_min, r_max]区间的值进行reward shaping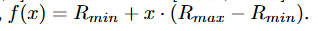
;进而指出为了防止直接使用确定性成功率可能导致对真实值的估计过于自信,受到 Thompson 抽样原则的启发 (Thompson, 1933; Agrawal & Goyal, 2012),采用概率的视角进行成功率估计。具体来说,每个状态的成功率被近似为 Beta 分布中的一个变量。
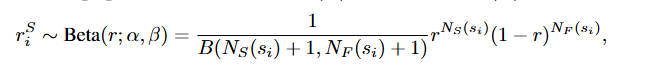
接下来,自然就是就是对N的估计(这在高维状态空间比较重要),文章提出使用核密度估计(KDE)能够高效地估计高维、连续或无限状态空间中的成功和失败次数,以此来近似从累积经验中获得的成功和失败密度。 具体来说,我们维护两个缓冲区 DSD_S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









