




ICML 2024
paper
code
学习高质量的动力学模型对于顺序决策任务非常重要,尤其是在离线环境下。然而,真实世界环境中过渡动态的复杂行为给标准前向模型带来了挑战,因为这些模型偏向于平滑回归因子,与过渡的固有特性(如不连续或大曲率)相冲突。在这项工作中,建议通过标量值能量函数对过渡概率进行直观建模,这样不仅可以灵活预判分布,还能捕捉复杂的过渡情况。研究表明,基于能量的过渡模型(ETM)能准确拟合不连续的过渡函数,并能更好地泛化分布外过渡数据。此外,在 DOPE 基准测试中,证明基于能量的过渡模型提高了评估精度,并明显优于其他off-policy评估方法。最后证明了基于能量的过渡模型也有利于强化学习,并在 D4RL Gym-Mujoco 任务中优于先前的RL 算法。
总结:采用能量模型对动力学模型建模,训练能量模型则是采用对比学习(正样本为离线数据集真实转移,负样本为K-1个基于模型的通过Langevin MCMC 采样)
Method
能量模型
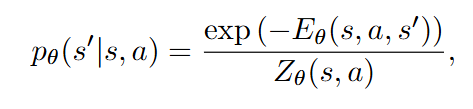
Langevin MCMC 采样
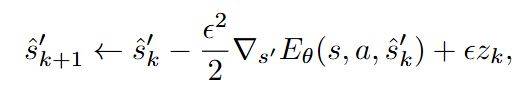
其中z为高斯噪声
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2968
2968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









