







ICML 2024 Oral
paper
值函数是深度强化学习(RL)的重要组成部分,通常通过均方误差回归进行训练,以匹配引导目标值。然而,事实证明,将基于值的 RL 方法扩展到大型网络具有挑战性。这种困难与监督学习形成了鲜明对比:通过利用交叉熵分类损失,监督方法可以可靠地扩展到大型网络。观察到这一差异,在本文中研究了是否只需使用分类而不是回归来训练值函数,就能提高深度 RL 的可扩展性。研究表明,使用分类交叉熵训练值函数可以显著提高各个领域的性能和可扩展性.
本文提出对Q值分布采用分类分布(categorical distribution):
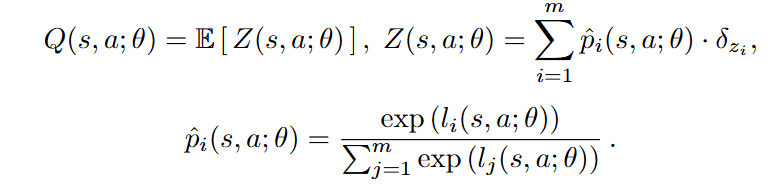
而对target Q分布则探索三种设置:1)Two-hot Categorical Distribution 2) Histograms as Categorical Distributions 3) Categorical Distributional RL(C51) .
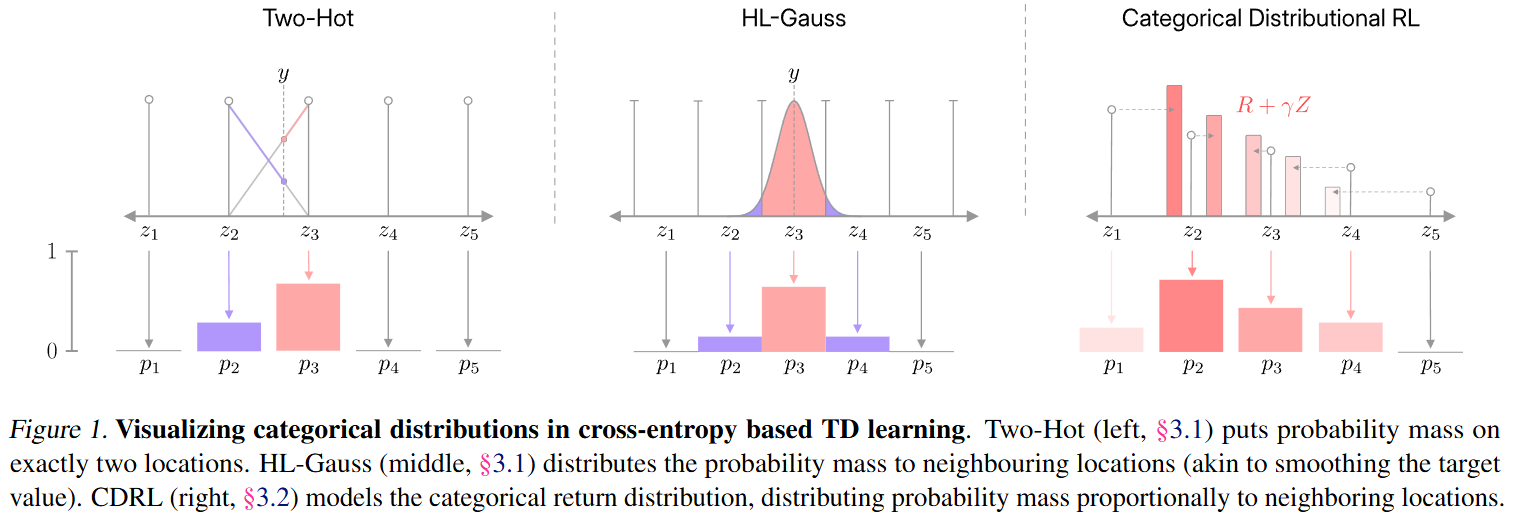
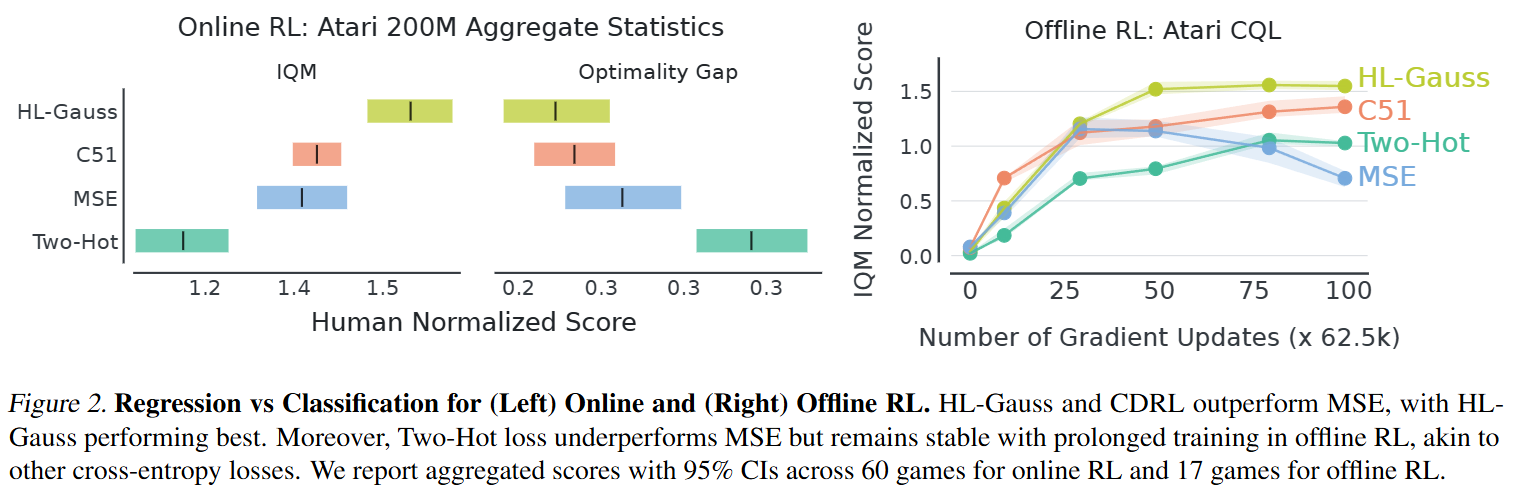
实验结果中第二种方案最优:
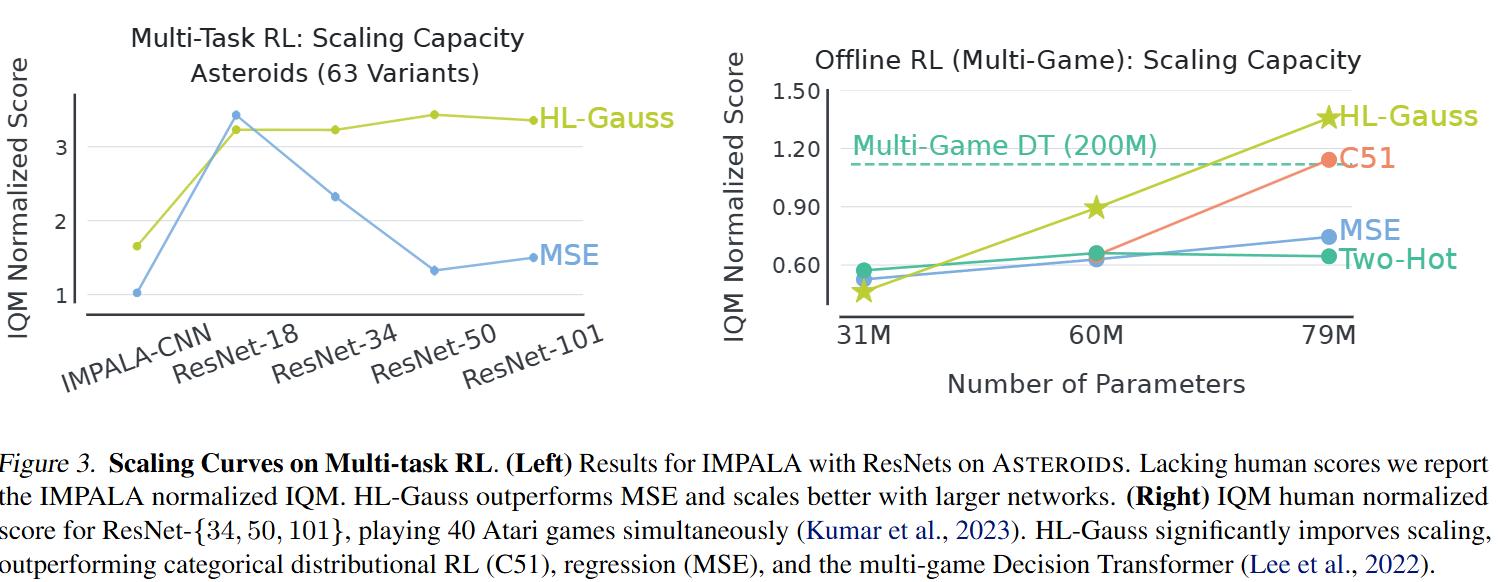
而在scale方面也证明基于分类分布的Q值再更大规模的强化学习效果也增加


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









