







 本文深入解析Redis中字典数据结构的实现原理,包括其核心组成部分如dictht表和rehashidx,以及关键操作如dictExpand和dictRehash。通过详尽的算法描述,如dictScan的遍历机制和rev函数的位操作,揭示了字典在不同大小变化时如何确保所有元素被正确遍历。
本文深入解析Redis中字典数据结构的实现原理,包括其核心组成部分如dictht表和rehashidx,以及关键操作如dictExpand和dictRehash。通过详尽的算法描述,如dictScan的遍历机制和rev函数的位操作,揭示了字典在不同大小变化时如何确保所有元素被正确遍历。
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;字典dict主要内容在于2个dictht表和rehashidx,dictht[0]表示没有进行哈希的表,dict[1]表示正在进行哈希的表,rehashidx不为-1的时候表示正在进行哈希。dictht主要内容sizemask始终是size减1。
int dictExpand(dict *d, unsigned long size)用来扩大字典大小,字典大小永远为2的倍数,方便查找。如果0号表没有初始化过,那么直接给0号表赋值,如果0号表存在的话,就扩大的表赋值给1号表,准备哈希。
int dictRehash(dict *d, int n)对字典进行哈希,参数n表示要执行次数。由于字典会有空值,所以设置空值浏览次数,这个值设置为执行次数的10倍。每次执行哈希的过程如下:首先从0号表中找到一个非空实体,把这个实体链表里的内容全部迁移到1号表对应下标的表里,往链表首部赋值。如果哈希完成则把1号表的内容全部迁移回0号表,清空1号表并返回0,否则返回1。
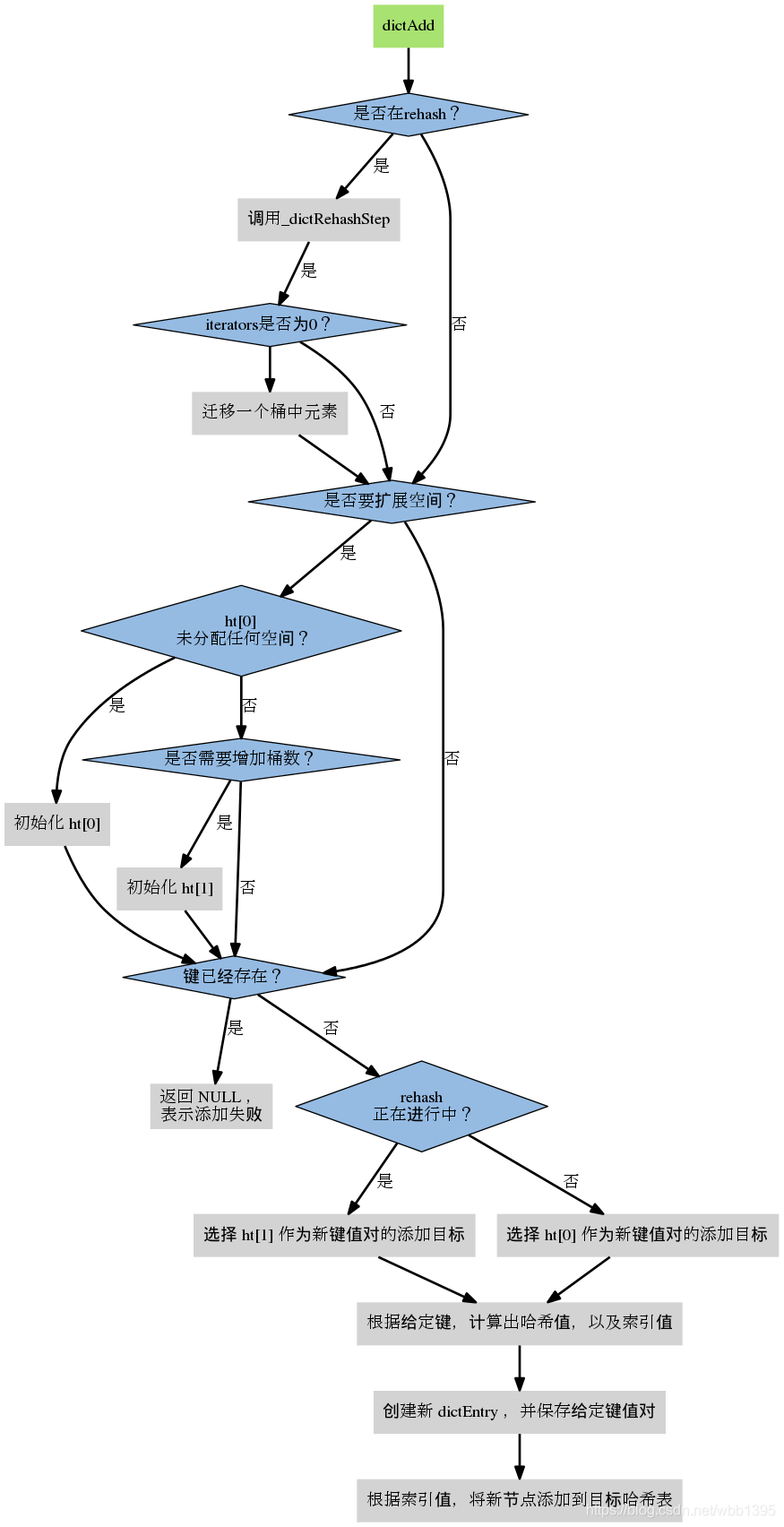
下图引用自https://redissrc.readthedocs.io/en/latest/datastruct/dict.html,把字典中添加新元素的过程描述的很清楚了。
/* Function to reverse bits. Algorithm from:
* http://graphics.stanford.edu/~seander/bithacks.html#ReverseParallel */
static unsigned long rev(unsigned long v) {
unsigned long s = 8 * sizeof(v); // bit size; must be power of 2
unsigned long mask = ~0;
while ((s >>= 1) > 0) {
mask ^= (mask << s);
v = ((v >> s) & mask) | ((v << s) & ~mask);
}
return v;
}这个对一个数进行高低位相反的操作的算法蛮有意思的,网站上讲解得很详细。
unsigned long dictScan(dict *d, unsigned long v, dictScanFunction *fn, dictScanBucketFunction* bucketfn, void *privdata)字典的数据结构和算法里,dictScan这个函数的算法特别精妙。遍历的步骤如下:第一步调用函数,游标(v)设置为0;第二步执行一次遍历,会返回一个新的游标,供下一次调用使用;第三步当游标返回为0的时候整个遍历就结束了。
由于字典在遍历的时候大小可能会扩大或者缩小,所以普通的遍历算法难免会过多或过少地遍历字典,虽然这个算法也会多遍历几次字典,但是它保证了一定会遍历所有元素。
字典的大小一定是2的n次方,字典的掩码是n位全1的数,所以取元素的时候是根据哈希值并掩码取得,保证游标一定在字典分配的大小范围内。遍历的时候字典的大小没有发生变化的这种情况没有什么好说的,关键在于字典的大小发生变化的时候。
假设字典的大小是16,掩码就是0b1111,以字典遍历到0b1100字典大小发生变化为例。
当字典的大小变大到32时,当前游标就变成了0b01100。字典遍历过的游标由0b0000,0b1000,0b0100变为0b00000,0b10000,0b01000,0b11000,0b00100,0b10100,也就是说之前遍历过的游标不会再遍历到。
当字典的大小变小到8时,当前游标就变成了0b100。字典遍历过的游标由0b0000,0b1000,0b0100变为0b000,0b100,这时候会重新遍历一次0b100这个游标,但是也保证了所有元素会被遍历到。

















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









