







 本文深入探讨决策树模型,包括ID3、C4.5和CART算法。从决策树的概念、信息熵、信息增益和增益比等方面阐述特征选择,详细讲解了决策树的生成与剪枝过程,旨在理解决策树的分类与回归原理。
本文深入探讨决策树模型,包括ID3、C4.5和CART算法。从决策树的概念、信息熵、信息增益和增益比等方面阐述特征选择,详细讲解了决策树的生成与剪枝过程,旨在理解决策树的分类与回归原理。
概述:
决策树是一种基本的分类与回归方法,表示基于特征对实例进行分类的过程。可看作 if-then规则的集合,也可认为是 定义在特征空间与类空间上的条件概率分布。
主要优点:模型可读性高,分类速度快;
决策树学习包括3个步骤:
1. 特征选择;
2. 决策树生成
3. 决策树修剪
经典算法: ID3算法、C4.5算法、CART算法
5.1 决策树模型与学习
5.1.1 决策树模型
定义5.1 (决策树)分类决策树模型是一种 描述对实例进行分类的树形结构,由结点node和有向边directed edge组成,结点有2种结构:内部节点internal node表示一个特征或属性,和 叶节点leaf node表示一个类别。
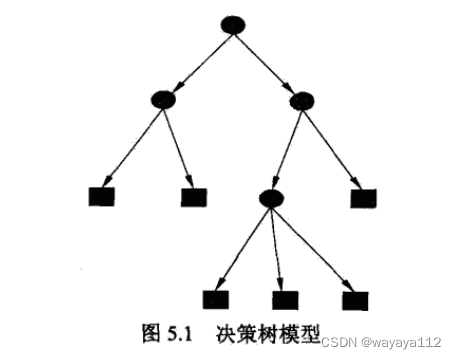
每一个子结点对应 该特征的一个取值。
如此递归地对实例进行测试并分配,直至达到叶节点。
5.1.2 决策树:if-then 规则的集合
由根节点到叶节点的每一条路径构建一条规则,路径上内部节点的特征对应着规则的条件,叶节点的类对应着规则的结论。
具有互斥且完备的重要性质:每一个实例有且只会被一条路径或规则所覆盖。
5.1.3 决策树:给定特征条件下的条件概率分布
决策树所表示的条件概率分布由 各个单元(互不相交的特征空间partition)给定条件下类的条件概率分布组成。
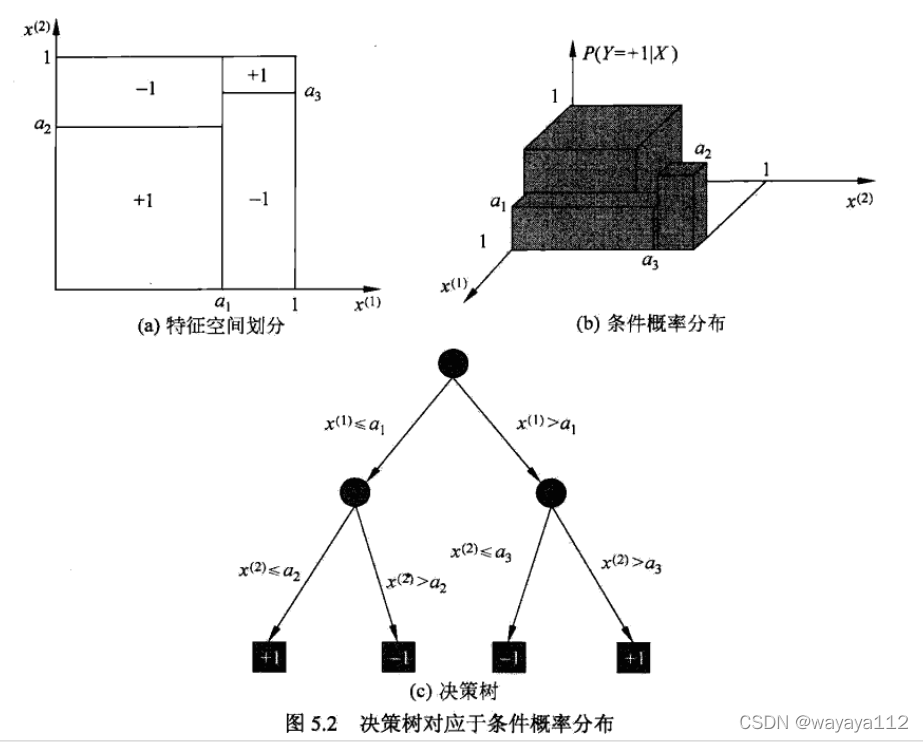
5.1.4 决策树学习
数据集
N为样本容量,n为特征个数,xi为一个输入实例(特征向量)。
目标:一个与训练数据矛盾较小的决策树,同时具有很好的泛化能力。通常是 递归地选择最优特征,并根据该特征对训练数据进行分割,使得各子数据集再当前条件下拥有好的分类结果。如可被基本正确分类,则构建叶节点,并将子集分到所对应的叶结点中去。如此递归,直至所有训练数据子集被分到叶节点,拥有明确的类。
但是会产生过拟合现象,如何解决?
对已生成的树进行自下而上的剪枝。具体地,去掉过于细分的叶节点,使其退回到父节点,甚至更高的结点,并将他们改为新的叶节点。
进行特征选择,避免模型选择 那些可能特征取值很多的特征项。
策略:确定损失函数为正则化的极大似然估计,最小化loss。
5.2 特征选择
5.2.1 特征选择问题
选择对训练数据分类能力强的特征,会提高决策树的学习效率,而 如果根据某个特征进行分类,其结果与随机分类结果没有差别,则可以不考虑这些特征。
一般来说,给定一组训练数据,我们可以使用不同的特征作为根节点,对数据进行划分子集,由此得到不同的决策树。但问题是:究竟选择哪个特征来划分特征空间,来得到一颗效率和准确率更高的决策树(使得各个子集在当前条件下有最好的分类)?
答案是:使用信息增益准则。
5.2.2 信息增益
熵(entropy):表示随机变量不确定性的度量,记 H(X) 或 H(p)
设X是 取有限个值的离散随机变量,其概率分布为:
则 随机变量X的熵为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









