




 AudioCraft是一个PyTorch库,专注于音频生成的深度学习研究。MusicGen是其一部分,能根据文本描述生成32kHz的音乐作品。MusicGen模型有不同的规模,从300M到3.3B,可以根据提供的描述或旋律生成音乐。训练过程涉及数据集准备、EnCodec的高保真音频压缩和MusicGen的自回归语言建模任务。
AudioCraft是一个PyTorch库,专注于音频生成的深度学习研究。MusicGen是其一部分,能根据文本描述生成32kHz的音乐作品。MusicGen模型有不同的规模,从300M到3.3B,可以根据提供的描述或旋律生成音乐。训练过程涉及数据集准备、EnCodec的高保真音频压缩和MusicGen的自回归语言建模任务。
AudioCraft 是一个 PyTorch 库,用于音频生成的深度学习研究。AudioCraft 包含两个先进的AI生成模型:AudioGen和MusicGen,它们共同致力于生成高质量的音频内容。
MusicGen是一个简单且可控的音乐生成模型。它利用Meta提供的20K小时授权音乐进行训练,能够根据文本描述或已有的旋律生成高质量的32kHz音乐作品。
源码:
https://github.com/facebookresearch/audiocraft
Demo示例:
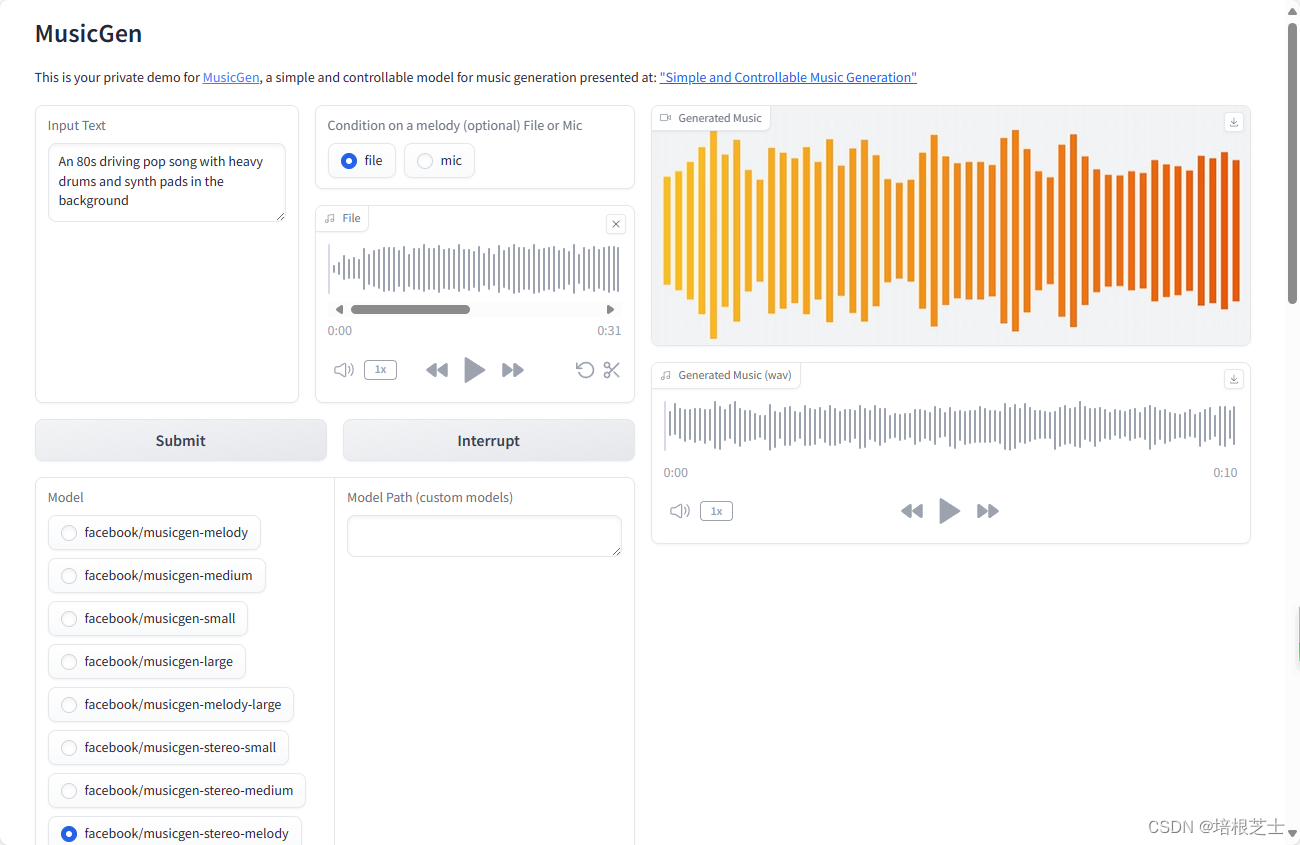
https://huggingface.co/spaces/facebook/MusicGen
安装
安装环境
conda create -n musicgen python=3.10
conda activate musicgen
pip install setuptools wheel
pip install torch==2.1.0+cu118 torchvision==0.16.0+cu118 torchaudio==2.1.0 xformers==0.0.22.post7 --extra-index-url https://download.pytorch.org/whl/cu118
conda install "ffmpeg<5" -c conda-forge
pip install dora-search
拉取源码
git clone https://github.com/facebookresearch/audiocraft
pip install -e . 启动项目
python -m demos.musicgen_app --share模型介绍
模型将根据提供的描述生成一段简短的音乐,一次可生成长达30秒的音频。
模型是根据库存音乐目录中的描述进行训练的,最有效的描述应该包括现有乐器的一些细节,以及一些预期的用例(例如,添加“perfect for a commercial”可能会有所帮助)。
10种模型变体:
- facebook/musicgen-m
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1946
1946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









