









 本文介绍了分布式锁的概念,探讨了CAP理论,并详细讲述了基于关系型数据库、缓存(Redis)及Zookeeper实现分布式锁的方法。讨论了乐观锁、悲观锁、数据库唯一约束、Redis的SETNX操作以及Zookeeper的临时有序节点策略,旨在深入理解分布式锁的多种实现策略。
本文介绍了分布式锁的概念,探讨了CAP理论,并详细讲述了基于关系型数据库、缓存(Redis)及Zookeeper实现分布式锁的方法。讨论了乐观锁、悲观锁、数据库唯一约束、Redis的SETNX操作以及Zookeeper的临时有序节点策略,旨在深入理解分布式锁的多种实现策略。
一,什么是分布式锁
在多线程并发的情况下,单机应用保证一个代码块在同一时间只能由一个线程访问 ----> 在Java中用锁来保证,比如java的synchronized语法以及reentrantlock类
如果在分布式的集群环境中,如何保证不同节点的线程的同步执行。 -----> 分布式锁
ReentrantLock的lock和unlock要求必须是在同一线程进行,而分布式应用中,lock和unlock是两次不相关的请求,因此肯定不是同一线程,因此导致无法使用ReentrantLock。

改图所示在分布式系统中,分布式锁实现不同线程对代码和资源的同步访问。
分布式锁的实现有哪些?
基于数据库:
基于数据库表做乐观锁,用于分布式锁。(version)
基于数据库表做悲观锁(InnoDB,for update)
基于数据库表数据记录做唯一约束(表中记录方法名称)
基于缓存:
常用方案:使用redis的setnx()用于分布式锁。(setNx,直接设置值为当前时间+超时时间,保持操作原子性)
使用memcached的add()方法,用于分布式锁。
基于Zookeeper:
每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。
二, CAP理论
分布式系统(distributed system)正变得越来越重要,大型网站几乎都是分布式的。
分布式系统的最大难点,就是各个节点的状态如何同步。CAP 定理是这方面的基本定理,也是理解分布式系统的起点。
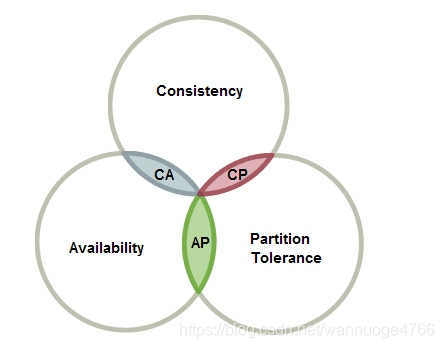
一个分布式系统有三个指标:
consistency(一致性)
availability(可用性)
partition tolerance(分区容忍性)
这三个指标不能同时做到,这个结论叫做CAP定理。
partition tolerance分区容错
一个分布式系统里面,节点组成的网络本来应该是连通的。然而可能因为一些故障,使得有些节点之间不连通了,整个网络就分成了几块区域。数据就散布在了这些不连通的区域中。这就叫分区。
当你一个数据项只在一个节点中保存,那么分区出现后,和这个节点不连通的部分就访问不到这个数据了。这时分区就是无法容忍的。提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里。容忍性就提高了。由此可见P问题主要来源于网络问题。
Consistency一致性
Consistency 中文叫做"一致性"。意思是,所有节点在同一时间的数据完全一致。也就是分布式系统中写操作之后的读操作,必须返回该值。
对于一致性,可以分为强/弱/最终一致性三类
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。
强一致性
对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。
弱一致性
如果能容忍后续的部分或者全部访问不到,则是弱一致性。
最终一致性
如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
Availability可用性
可用性指“Reads and writes always succeed”,即服务在正常响应时间内一直可用。
好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。可用性通常情况下可用性和分布式数据冗余,负载均衡等有着很大的关联。
CAP权衡
CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区不是你想不想的问题,而是始终会存在,因此CA的系统更多的是允许分区后各子系统依然保持CA。(如Oracle Mysql)
CP without A:如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。(如NoSQL: Mongo DB, HBase, Redis)
AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。(如NoSQL: CoachDB Cassandra, DynamoDB)
三,基于关系型数据库实现
基于数据库表做乐观锁,用于分布式锁。(version)
乐观锁(Optimistic Lock),顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在提交更新的时候会判断一下在此期间别人有没有去更新这个数据。乐观锁适用于读多写少的应用场景,这样可以提高吞吐量。
大多数是基于数据版本(VERSION)的记录机制实现的。何谓数据版本号?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表添加一个 “VERSION”字段来实现读取出数据时,将此版本号一同读出,之后更新时,对此版本号加1。
在更新过程中,会对版本号进行比较,如果是一致的,没有发生改变,则会成功执行本次操作;如果版本号不一致,则会更新失败。
基于数据库表做悲观锁(InnoDB,for update)
除了可以通过增删操作数据表中的记录以外,其实还可以借助数据中自带的锁来实现分布式的锁。我们还用刚刚创建的那张数据库表。可以通过数据库的排他锁来实现分布式锁。 基于MySql的InnoDB引擎,可以使用以下方法来实现加锁操作:
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
基于数据库表数据记录做唯一约束(表中记录方法名称)
要实现分布式锁,最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。当我们要锁住某个方法或资源时,我们就在该表中增加一条记录,想要释放锁的时候就删除这条记录。
四,基于缓存实现
此部分搬运自程序员小灰的文章,链接在参考文献中。
使用redis的SETNX()用于分布式锁。
(setNx,直接设置值为当前时间+超时时间,保持操作原子性)
SETNX是将 key 的值设为 value,当且仅当 key 不存在。若给定的 key 已经存在,则 SETNX 不做任何动作。
操作步骤:
1.加锁
最简单的方法是使用setnx命令。key是锁的唯一标识,按业务来决定命名。比如想要给一种商品的秒杀活动加锁,可以给key命名为 “lock_sale_商品ID” 。而value设置成什么呢?我们可以姑且设置成1。加锁的伪代码如下:
setnx(key,1)
当一个线程执行setnx返回1,说明key原本不存在,该线程成功得到了锁;当一个线程执行setnx返回0,说明key已经存在,该线程抢锁失败。
2.解锁
有加锁就得有解锁。当得到锁的线程执行完任务,需要释放锁,以便其他线程可以进入。释放锁的最简单方式是执行del指令,伪代码如下:
del(key)
释放锁之后,其他线程就可以继续执行setnx命令来获得锁。
3.锁超时
锁超时是什么意思呢?如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住,别的线程再也别想进来。
所以,setnx的key必须设置一个超时时间,以保证即使没有被显式释放,这把锁也要在一定时间后自动释放。setnx不支持超时参数,所以需要额外的指令,伪代码如下:
expire(key, 30)
综合起来,我们分布式锁实现的第一版伪代码如下:
if(setnx(key,1) == 1){
expire(key,30)
try {
do something
} finally {
del(key)
}
}
总结:1. 根据hash算法选择一个redis集群节点,执行lua脚本加锁
2. 设定原子锁生存时间
3. 锁互斥原理,并提供watch dog自动延期,每10秒检查一下
4. 持有锁期间可重入加锁
5. 锁释放
五,基于Zookeeper实现
首先要了解ZK的基础框架,Zookeeper的数据存储结构就像一棵树,这棵树由节点组成,这种节点叫做Znode。
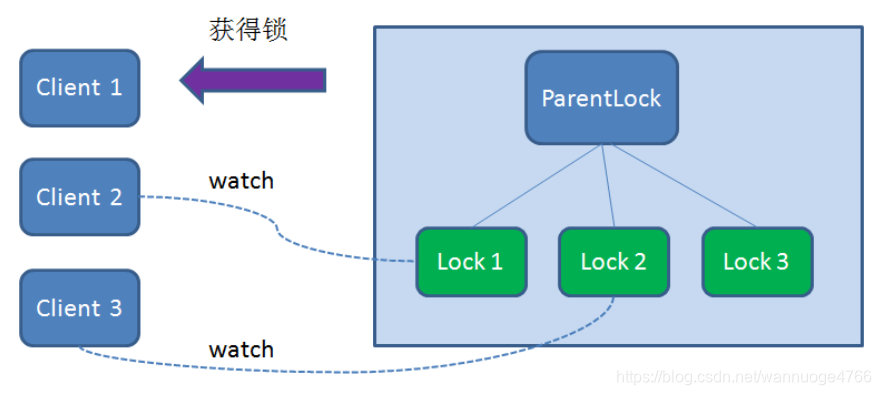
每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
总结:1. 客户端申请加锁,创建临时顺序节点
2. 判断能否加锁并加锁成功或等待
3. 若加锁失败,会对上一个顺序节点加一个监听器
4. 如果监听节点变动释放锁,则重新尝试获取锁
参考文献:

















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









