




 本文介绍如何利用ASP.NET Core、SignalR和微软语音服务实现Web实时语音识别。通过Web Audio API获取麦克风音频流,使用SignalR进行实时传输,后端调用微软语音服务进行识别。详细讲解了后端的接口配置、自定义音频流处理,以及前端Angular的SignalR集成。
本文介绍如何利用ASP.NET Core、SignalR和微软语音服务实现Web实时语音识别。通过Web Audio API获取麦克风音频流,使用SignalR进行实时传输,后端调用微软语音服务进行识别。详细讲解了后端的接口配置、自定义音频流处理,以及前端Angular的SignalR集成。
处于项目需要,我研究了一下web端的语音识别实现。目前市场上语音服务已经非常成熟了,国内的科大讯飞或是国外的微软在这块都可以提供足够优质的服务,对于我们工程应用来说只需要花钱调用接口就行了,难点在于整体web应用的开发。最开始我实现了一个web端录好音然后上传服务端进行语音识别的简单demo,但是这种结构太过简单,对浏览器的负担太重,而且响应慢,交互差;后来经过调研,发现微软的语音服务接口是支持流输入的连续识别的,因此开发重点就在于实现前后端的流式传输。
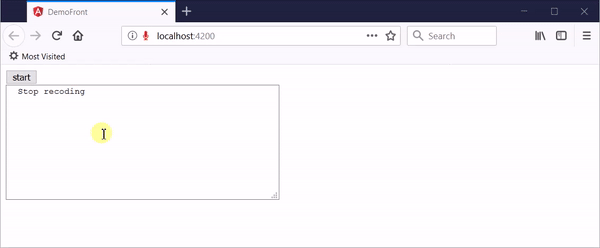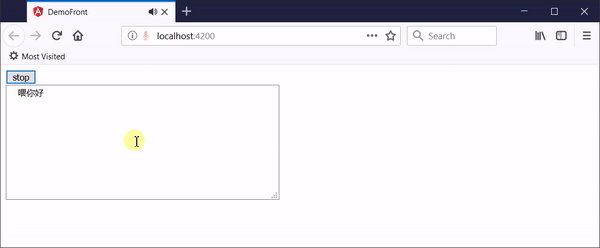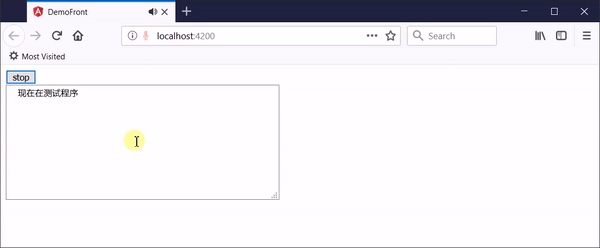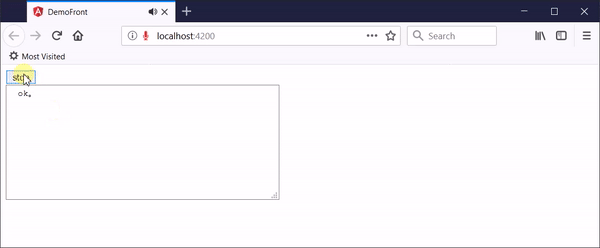
参考这位国外大牛写的博文Continuous speech to text on the server with Cognitive Services,开发的新demo可以达到理想的效果,在网页上点击“开始录音”开启一次录音,对着麦克风随意说话,网页会把实时的音频数据传递给后端,后端实时识别并返回转换结果,点击“结束录音”停止。
1 整体结构
整体结构图如下所示,在web端需要使用HTML5的Web Audio API接收麦克风输入的音频流,进行适量的处理后实时传递给服务端;web与服务端之间的音频流交互通过SignalR来实现;具体的语音识别通过调用微软语音服务实现。
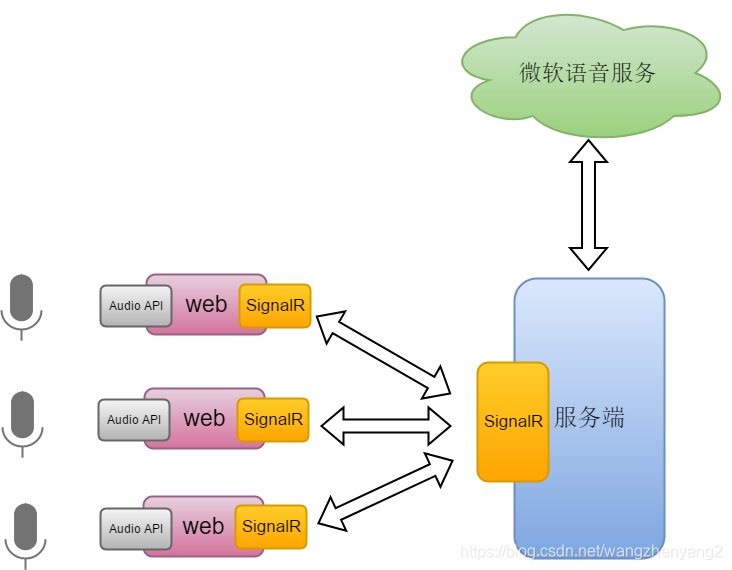 该web实时语音识别demo可以实现下面的功能:
该web实时语音识别demo可以实现下面的功能:
- 可以通过网页传入麦克风音频
- 网页可以实时显示语音识别结果,包括中间结果和最终结果
- 可以保存每一次的录音,并且录音时长可以非常长
- 支持多个web同时访问,服务端管理多个连接
2 技术栈
- ASP.NET Core开发
服务端使用较新的 ASP.NET Core技术开发,不同于传统的 ASP.NET,ASP.NET Core更加适合前后台分离的web应用,我们会用 ASP.NET Core框架开发REST API为前端服务。如果不去纠结 ASP.NET Core的框架结构,实际的开发和之前的.NET应用开发没什么不同,毕竟只是底层结构不同。 - JavaScript或TypeScript开发
前端的逻辑用JavaScript开发,具体什么框架无所谓。我是用angular开发的,因此严格的说开发语言是TypeScript了。至于网页的具体内容,熟悉html、CSS就行了。 - Web Audio API的使用和基本的音频处理的知识
采集和上传麦克风音频都在浏览器进行,对此需要使用HTML5标准下的Web API进行音频流的获取,使用音频上下文(AudioContext)实时处理音频流。具体处理音频流时,需要了解一点基本的音频知识,例如采样率、声道等参数,WAV文件格式等等。
相关资料:
HTML5网页录音和压缩
HTML5 getUserMedia/AudioContext 打造音谱图形化
Capturing Audio & Video in HTML5 - 微软语音认知服务
微软的语音识别技术是微软云服务中的成员之一,相比于国内比较熟知的科大讯飞,微软的优势在于契合 .NET Core技术栈,开发起来非常方便,支持连续识别,支持自定义训练,并且支持容器部署,这对于那些对上传云服务有安全顾虑的用户更是好消息。当然价格考虑就得看具体情况了,不过如果你有Azure账号的话,可以开通标准版本的语音识别服务,这是免费的,只有时间限制;没有账号的话可以使用微软提供的体验账号体验一个月。
官方文档: Speech Services Documentation - SignalR的使用
要实现web和服务端的流通信,就必须使用web socket一类的技术来进行长连接通信,微软的SignalR是基于web socket的实时通信技术,如果我们的web需要和服务端保持长连接或者需要接收服务端的消息推送,使用该技术可以方便的实现。需要注意的是 ASP.NET SignalR and ASP.NET Core SignalR是有区别的,在 .NET Core环境下需要导入的是SignalR Core
官方文档: Introduction to ASP.NET Core SignalR
Angular下调用SignalR: How to Use SignalR with .NET Core and Angular - 字节流和异步编程的概念
参考这篇博文Continuous speech to text on the server with Cognitive Services,在服务端需要自己实现一个特别的字节流来作为语音服务的数据源,因为语音服务在默认的字节流上一旦读取不到数据就会自动结束。在具体的实现中,将会用到一些信号量来进行读取控制。
3 后端细节
3.1 获取微软语音识别服务
如果没有Azure账号,可以用微软提供的试用账号:
有Azure账号的话,在Azure门户里开通语音识别服务
创建的时候可以选择F0类型的收费标准,这种是免费的:
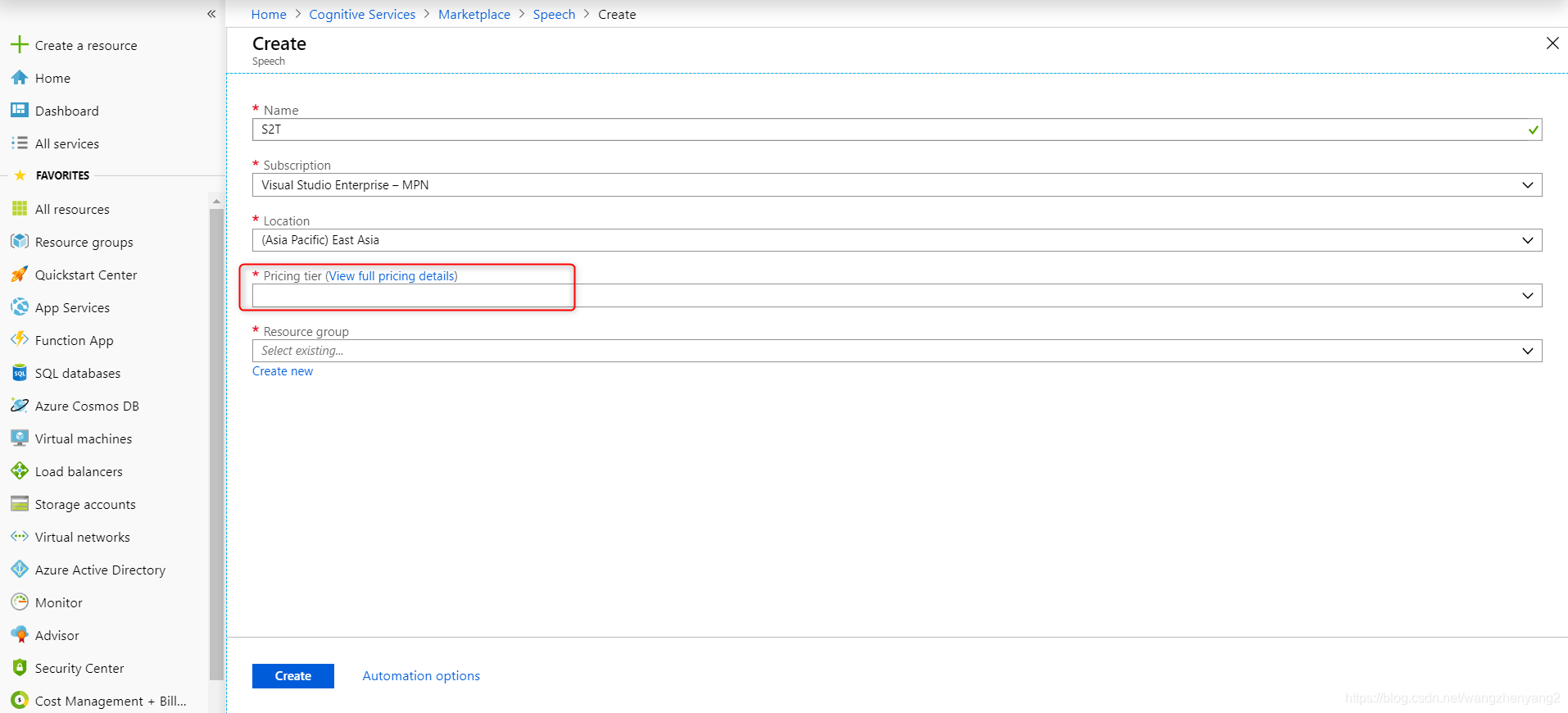
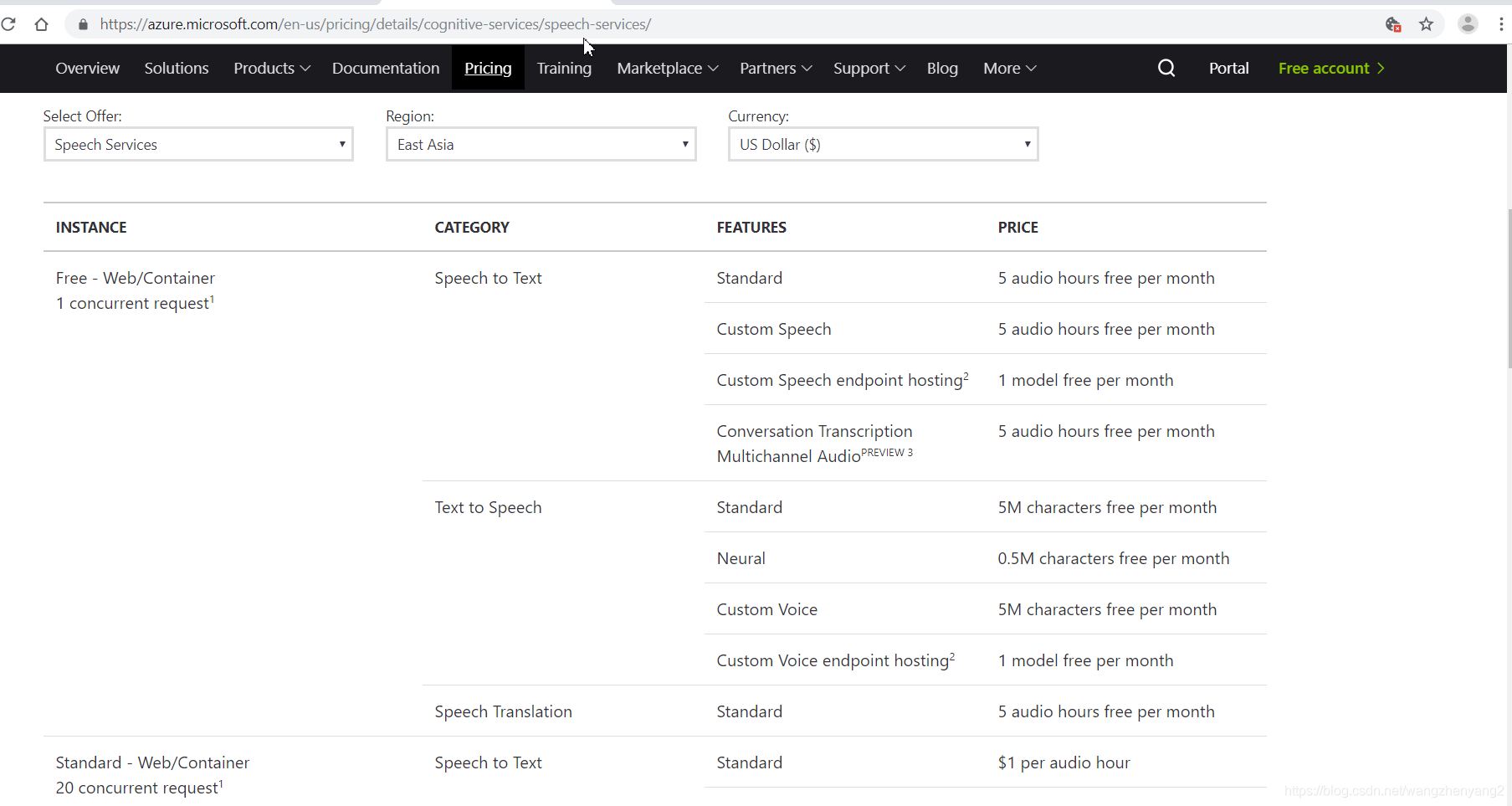
开通成功后,得到API Key的值,我们调用服务的时候传入这个参数;另一个参数是region,这个要看你创建服务的时候选择的区域,如果你选择的是East Asia,这个参数就是“eastasia”,如果用的是测试账号,统一用“westus”。
3.2 创建并配置ASP.NET Core API项目
新建一个 ASP.NET Core API项目
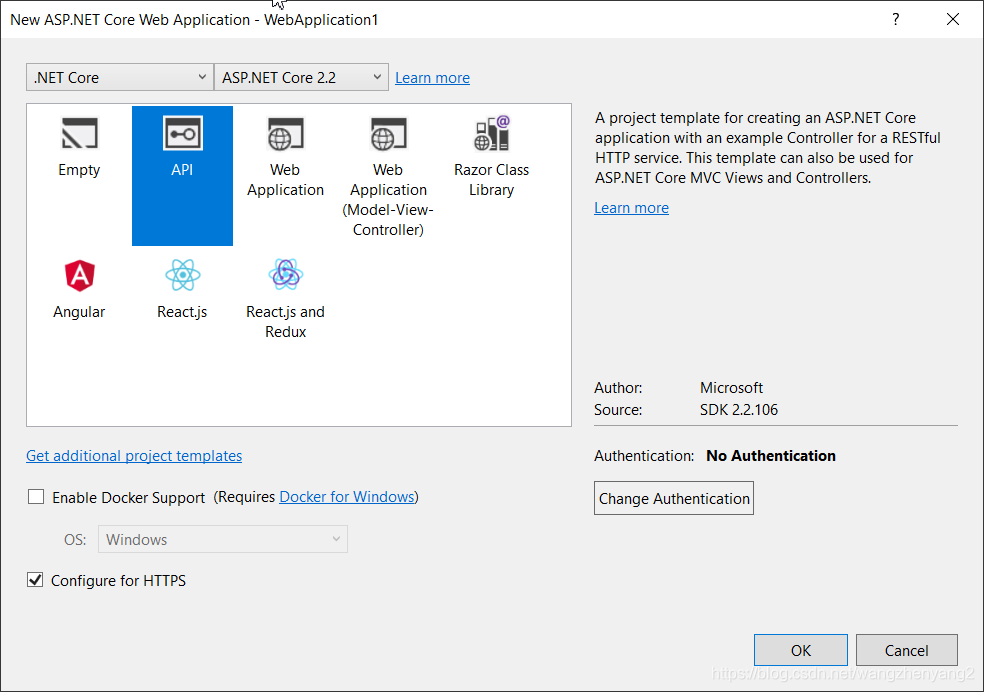
通过Nuget管理器添加语音服务和SignalR相关的包。Microsoft.CognitiveServices.Speech是微软语音服务包,Microsoft.AspNetC
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+




 到【灌水乐园】发言
到【灌水乐园】发言







