




 本文介绍如何使用Python通过websocket调用标贝科技的语音识别接口,实现语音到文字的转换。首先,需要注册并获取APIKey和APISecret,然后通过授权接口获取access_token。接着,配置接口参数,建立websocket客户端,最后执行代码实现实时识别。提供完整代码示例和官方链接。
本文介绍如何使用Python通过websocket调用标贝科技的语音识别接口,实现语音到文字的转换。首先,需要注册并获取APIKey和APISecret,然后通过授权接口获取access_token。接着,配置接口参数,建立websocket客户端,最后执行代码实现实时识别。提供完整代码示例和官方链接。
Python使用websocket调用实时语音识别,语音转文字
0. 太长不看系列,直接使用
在1.2官网注册后拿到APISecret和APIKey,直接复制文章2.5demo代码,保存为real_time_audio_recognition.py,在命令行执行
python real_time_audio_recognition.py -client_secret=您的client_secret -client_id=您的client_id -file_path=test.wav --audio_format=wav --sample_rate=16000
使用中有任何问题,欢迎留言提问。
1. Python调用标贝科技语音识别websocket接口,实现语音转文字
1.1 环境准备:
Python 3
1.2 获取权限
标贝科技 https://ai.data-baker.com/#/?source=qwer12
填写邀请码fwwqgs,每日免费调用量还可以翻倍


1.2.1 登录
点击产品地址进行登录,支持短信、密码、微信三种方式登录。

1.2.2 创建新应用
登录后进入【首页概览】,各位开发者可以进行创建多个应用。包括一句话识别、长语音识别、录音文件识别;在线合成、离线合成、长文本合成。

1.2.3 选择服务
进入【已创建的应用】,左侧选择您需调用的AI技术服务,右侧展示对应服务页面概览(您可查询用量、管理套餐、购买服务量、自主获取授权、预警管理)。
1.2.4 获取Key&Secret
通过服务 / 授权管理,获取对应参数,进行开发配置(获取访问令牌token)
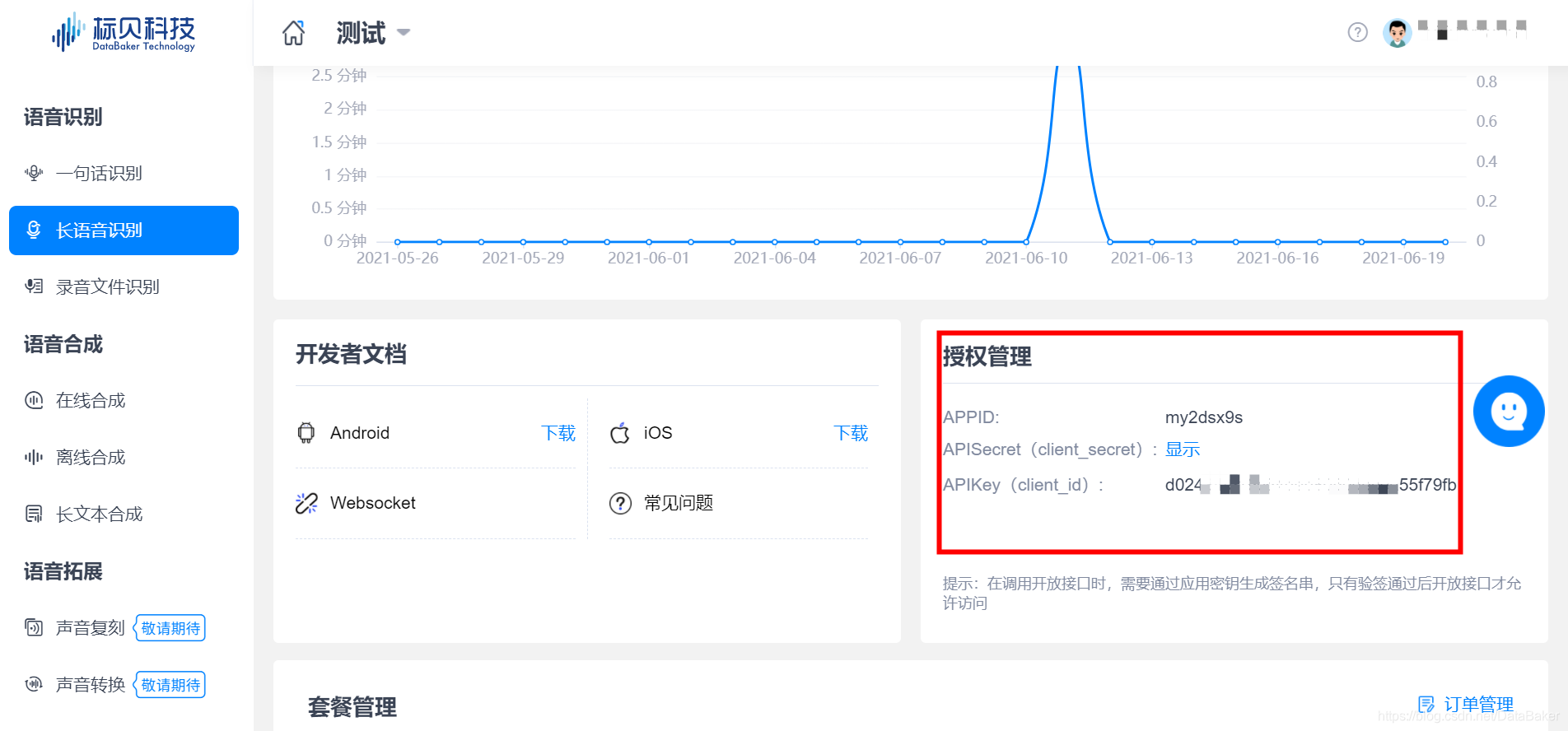
拿到Key和Secret就可以正式使用啦!
2. 代码实现
2.1 获取access_token
在拿到Key和Secret后,我们还需要调用授权接口获取access_token,这个access_token有效时长是24小时。
# 获取access_token用于鉴权
def get_access_token(client_s 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 2821
2821



 到【灌水乐园】发言
到【灌水乐园】发言







