




 本文指导如何在Linux和macOS上通过Conda安装miniconda,创建Python环境,并演示如何利用spleeter工具将音频文件分离成伴奏和人声。从环境管理到具体操作,适合初学者入门音频处理技术。
本文指导如何在Linux和macOS上通过Conda安装miniconda,创建Python环境,并演示如何利用spleeter工具将音频文件分离成伴奏和人声。从环境管理到具体操作,适合初学者入门音频处理技术。
文章目录
准备
conda
Conda是在Windows,macOS和Linux上运行的开源软件包管理系统和环境管理系统。 Conda可以快速安装,运行和更新软件包及其依赖项。 Conda可以轻松地在本地计算机上的环境中创建,保存,加载和切换。它是为Python程序创建的,但可以打包和分发适用于任何语言的软件。
conda分为anaconda和miniconda。miniconda属于精简版,不过完全满足我们的需求了,这里给出了miniconda的下载链接。
根据不同的系统,下载相应的文件,执行安装。我这里主要是Linux和macOS的安装方式。没有特殊定制的话,一路yes就可以了。
chmod 777 Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
使用
bogon:309209 xxx$ conda activate
(base) bogon:309209 xxx$
可以注意到前面的(base),是默认的conda环境。conda可以创建多个env,每个env可以安装不同版本的python以及其他软件。
(base) bogon:309209 xxx$ conda activate py38
(py38) bogon:309209 xxx$
因为新下载的conda默认python3.9版本,比较高,因此,我创建了py38这个env,并指定在这个env中使用python3.8。
conda详细的使用,这里不再赘述,可参考官方文档。
安装spleeter及使用
# install dependencies using conda
conda install -c conda-forge ffmpeg libsndfile
# install spleeter with pip
pip install spleeter
# download an example audio file (if you don't have wget, use another tool for downloading)
wget https://github.com/deezer/spleeter/raw/master/audio_example.mp3
# separate the example audio into two components
spleeter separate -p spleeter:2stems -o output audio_example.mp3
最终在output目录下,生成vocals.wav和accompaniment.wav两个文件,打开vocals.wav如下: 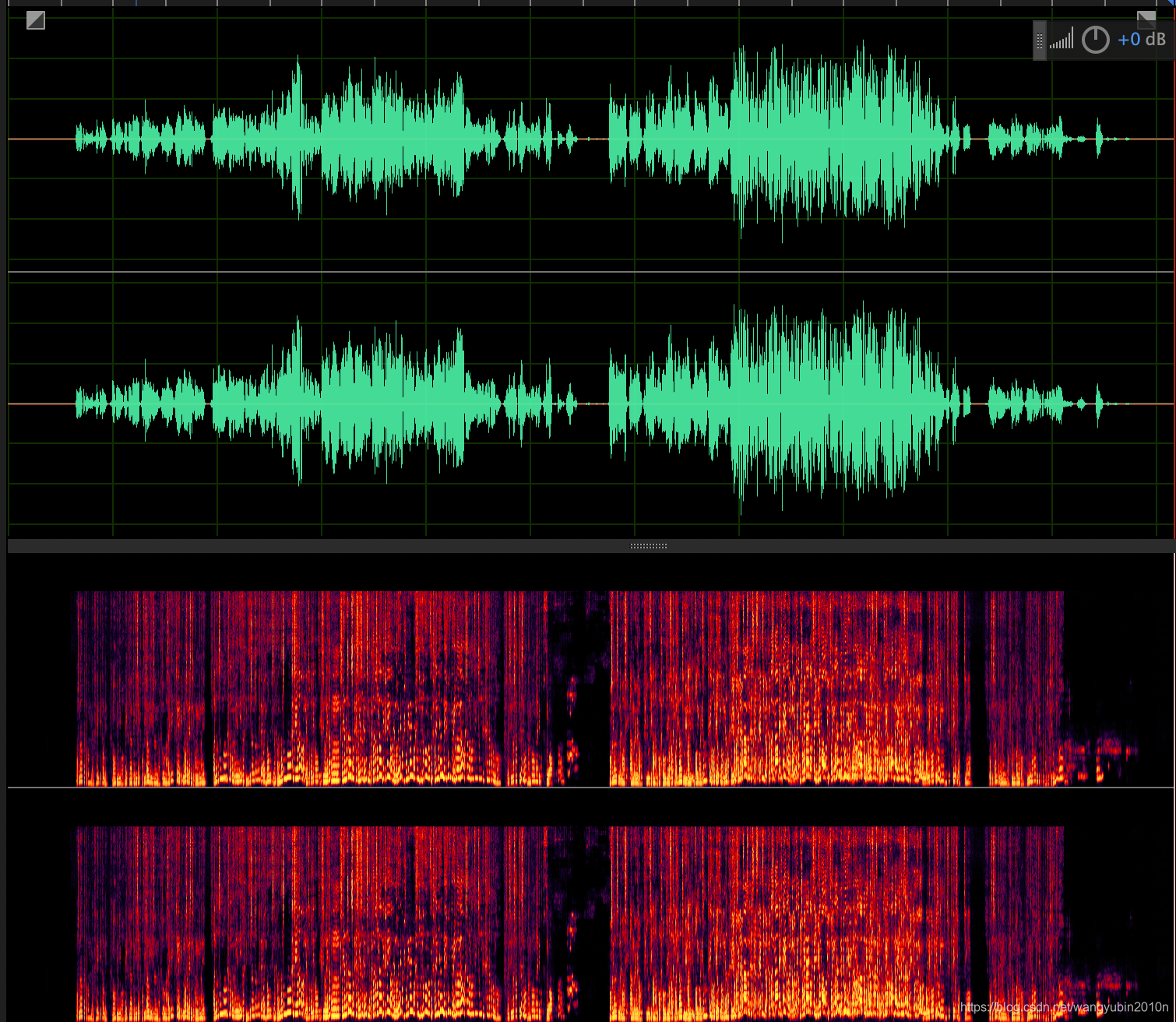
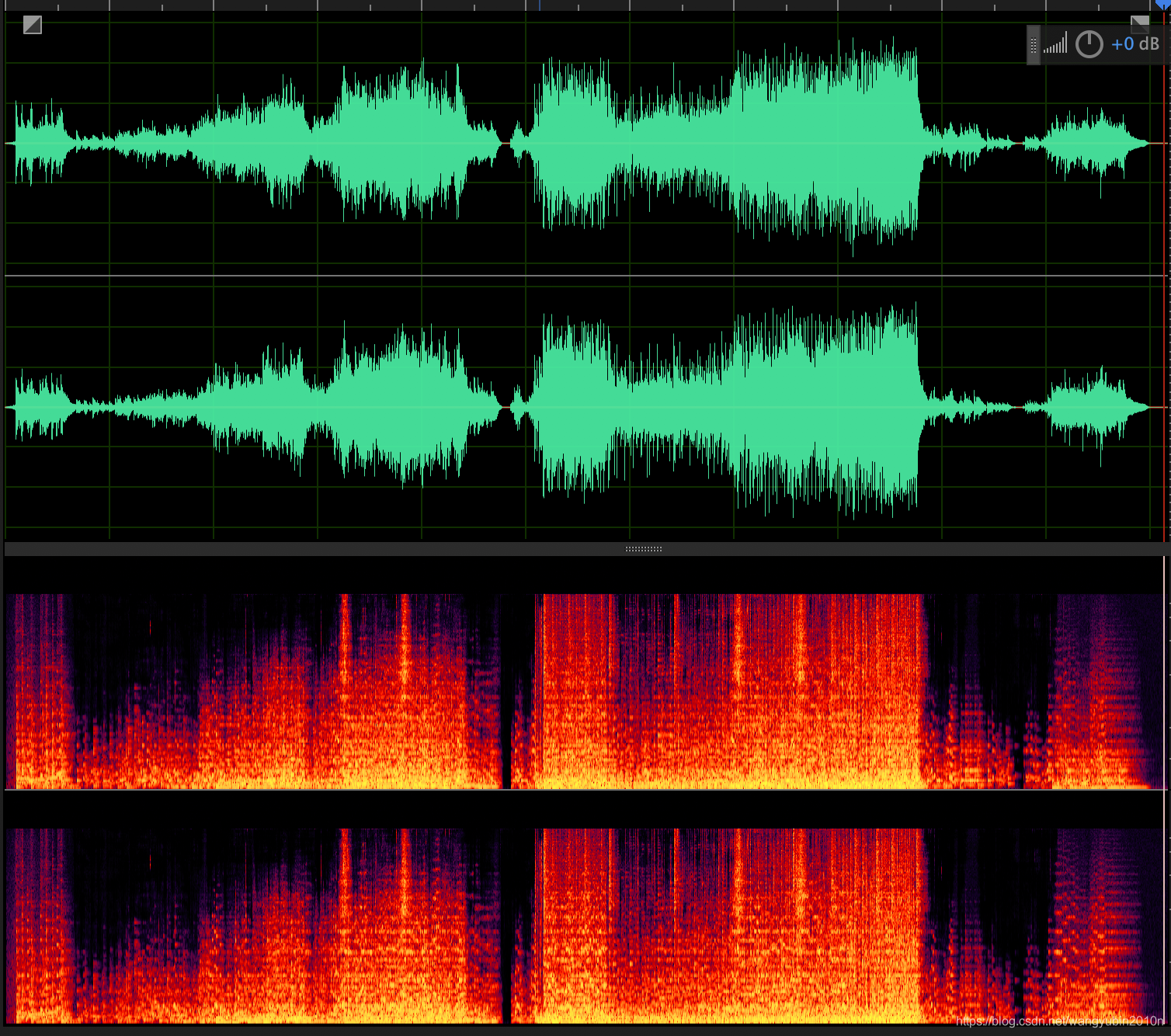
accompaniment.wav
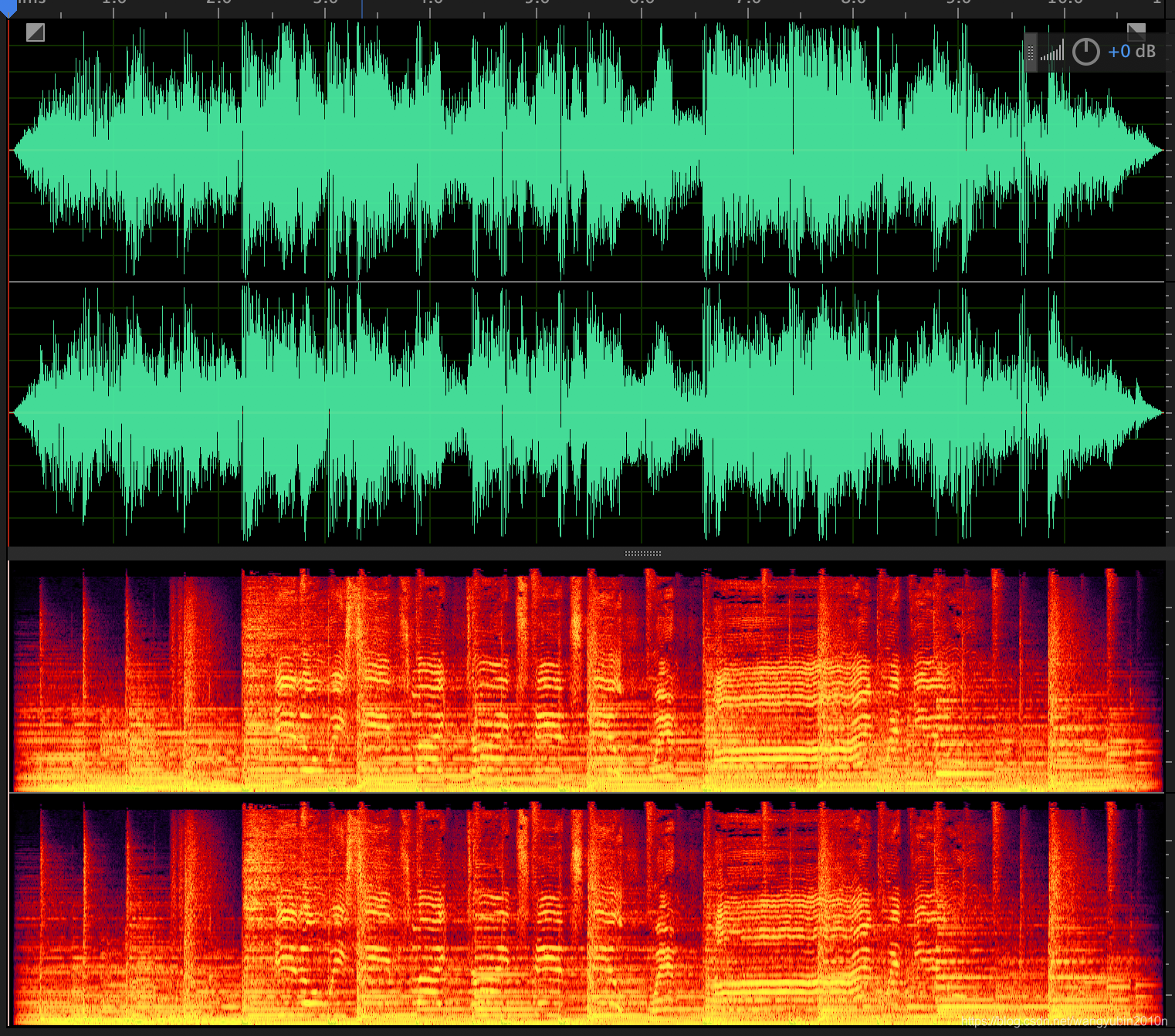
原始文件audio_example.mp3:
参考:


















 6259
6259






 到【灌水乐园】发言
到【灌水乐园】发言







