 预训练模型PDBERT助力软件漏洞分析
预训练模型PDBERT助力软件漏洞分析





全文摘要
本篇论文探讨了如何利用预训练技术提高软件漏洞分析任务的理解能力。作者提出了两个新的预训练目标:控制依赖预测和数据依赖预测,旨在仅根据源代码预测代码片段中的语句级控制依赖和标记级数据依赖。通过预训练,模型可以学习到分析代码中细粒度依赖关系所需的知识,并在微调时提升对漏洞代码的理解能力。实验结果表明,使用CDP和DDP进行预训练的Transformer模型PDBERT在三个下游任务上取得了最先进的性能,同时在部分函数和完整函数中预测控制和数据依赖性的F1得分均超过了99%和94%。
论文速读
论文方法
方法描述
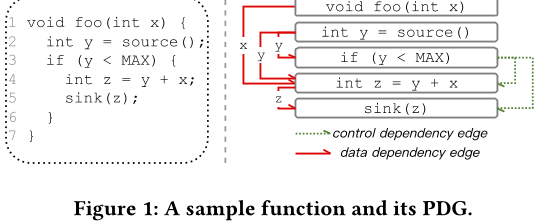
该论文提出了一种名为PDBERT的预训练模型,用于程序依赖关系分析任务。PDBERT通过将源代码作为输入,并使用多层Transformer编码上下文嵌入来捕捉程序结构信息。它使用三个预训练任务:Masked Language Model(MLM)、Statement-Level Control Dependency Prediction(CDP)和Token-Level Data Dependency Prediction(DDP),以帮助模型学习关于程序结构的知识。其中,MLM用于捕捉自然性和语法结构,CDP用于预测语句级别的控制依赖关系,DDP用于预测标记级别的数据依赖关系。
方法改进
与现有的基于自回归模型或序列到序列模型的解决方案相比,PDBERT不需要解析输入程序或构建其PDG,这使得它的应用更加方便和高效。此外,PDBERT还采用了掩码策略来处理标记类型的差异,以帮助模型更好地理解程序结构。
解决的问题
PDBERT旨在解决程序依赖关系分析问题,这是一个重要的编程挑战,因为程序中的依赖关系可以影响程序的行为、性能和安全性。PDBERT的目标是为程序依赖关系分
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1667
1667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









