








 超级会员免费看
超级会员免费看

文章大纲
神经网络模型的全周期优化方式都有哪些?
考察神经网络时期重要的激活函数sigmoid和tanh,它们有一个特点,即输入值较大或者较小的时候,其导数变得很小,而在训练阶段,需要求取多个导数值,并将每层得到的导数值相乘,这样一旦层数增加,多个很小的导数值相乘,结果便趋于零,即所谓梯度消失问题[插图],
这将会导致靠近输入层的隐含层的学习效果也趋于零。而靠近输入层的隐含层参数无法学习,就意味着它的值类似随机生成,那么有具体现实意义的输入层经过这些隐含层后会被变换成无意义的信息,继续沿着神经网络往后传递一直到输出层,也就无法得出有效的结论了。所以,深度神经网络很难训练。在深度学习中,除了改进激活函数使用ReLU函数,还提出了逐层预训练等方法来解决这个问题。
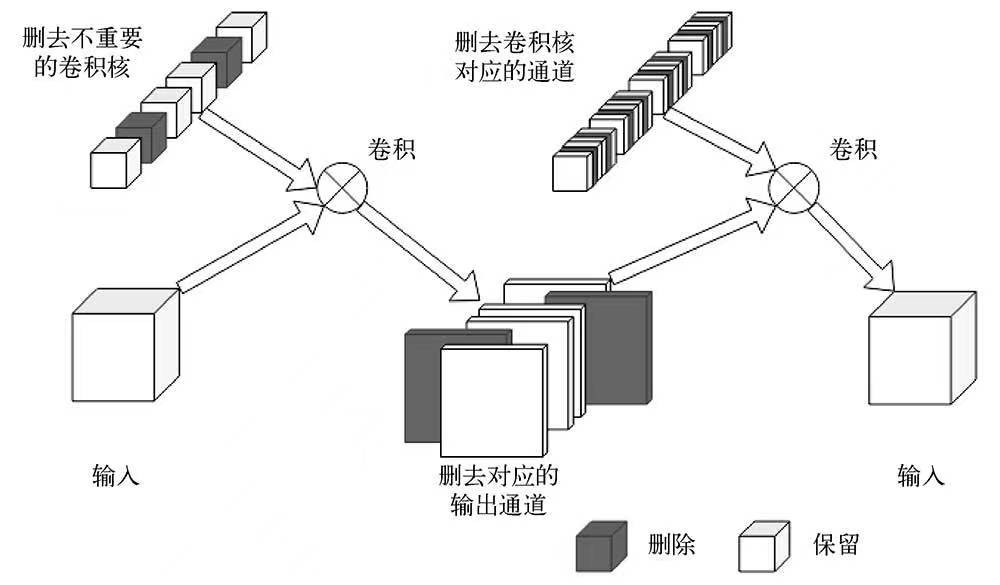
剪枝
剪枝即剪去神经网络模型中不重要的网络连接,本章使用的剪枝方式为通道剪枝,即在训练过程中逐步将权重较小的参数置零,然后将全为0的通道剪除。剪枝有一个大前提:模型结构和参数冗余。对于MobileNet这种已经简化过的轻量级网络来说,剪枝的效果不算大。
为了使模型效果尽量接近原模型,可以在训练过程中逐步将每一层中绝对值较小的参

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











