








 超级会员免费看
超级会员免费看

文章大纲
spark 等频 等宽 分箱 数据量较少时的现象
这里有一个很有趣的问题,当分箱数比较少 ,少于数据个数时候,等频分箱箱子编号是从0开始的。
当分箱数比较多的时候,多于数据数量,箱子编号是从1 开始编号的
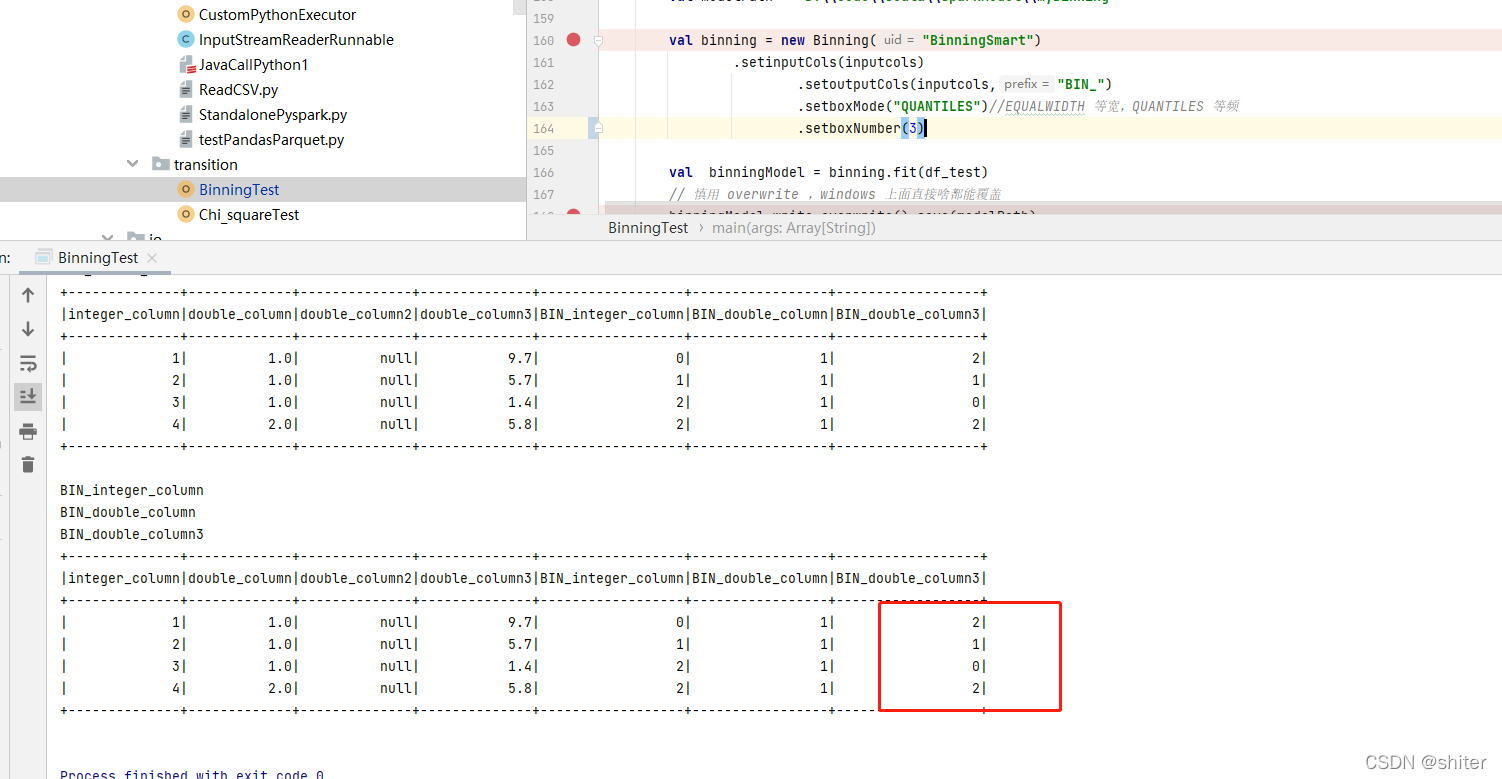
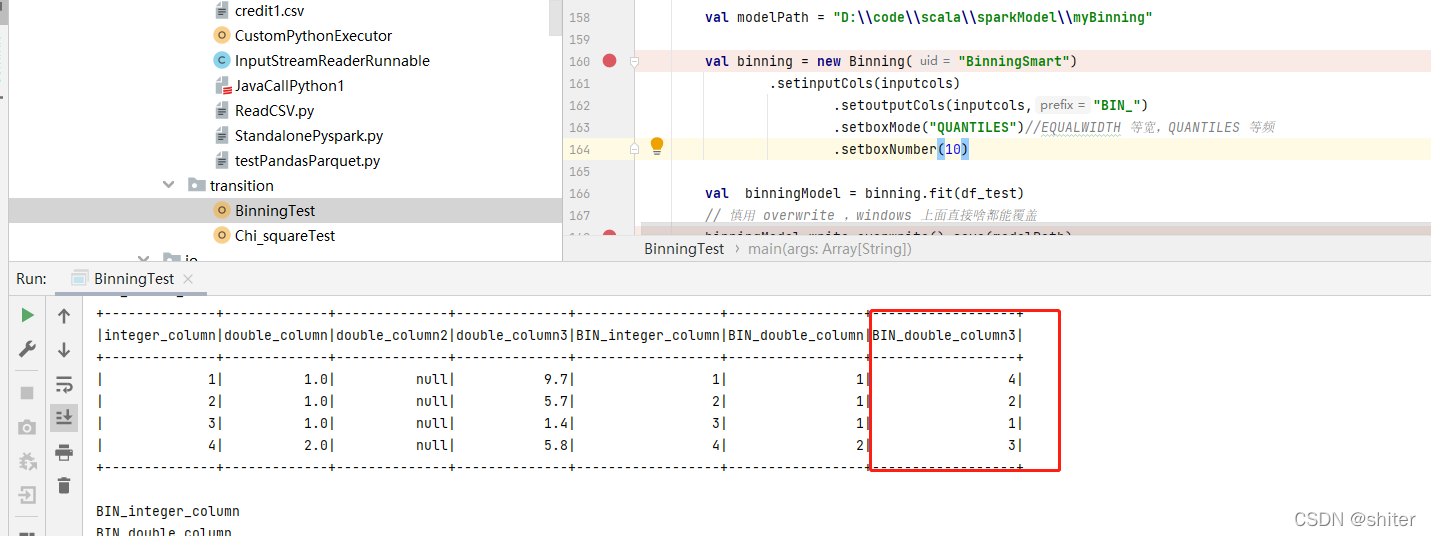
分箱编号不同的原因剖析
在下面文章中,我有提到
spark 特征工程 – 分箱 Binning(如何实现等频、等宽分箱)
QuantileDiscretizer (等频分箱)接收具有连续特征的列,并输出具有合并分类特征的列。按分位数,对给出的数据列进行离散化分箱处理。
和Bucketizer(等宽分箱处理)一样都是:
-
将连续数值特征转换为离散类别特征。
-
实际上 Class QuantileDiscretizer extends Bucketizer

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2638
2638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











