








 超级会员免费看
超级会员免费看

1.PCA简介
使用非监督学习的方式进行数据变换有非常广泛的用途。最常见的目的就是对数据进行可视化,将数据进行压缩并为进一步处理得到一个更有效的数据表示。这其中最有效使用最广泛的技术要数PCA(Principal Component Analysis)了。
主成分分析(PCA)是一种以某种方式旋转数据集的方法,使得旋转特征在统计学上不相关。这种旋转通常是根据它们能够解释数据的能力的重要性来选择新特征的子集。
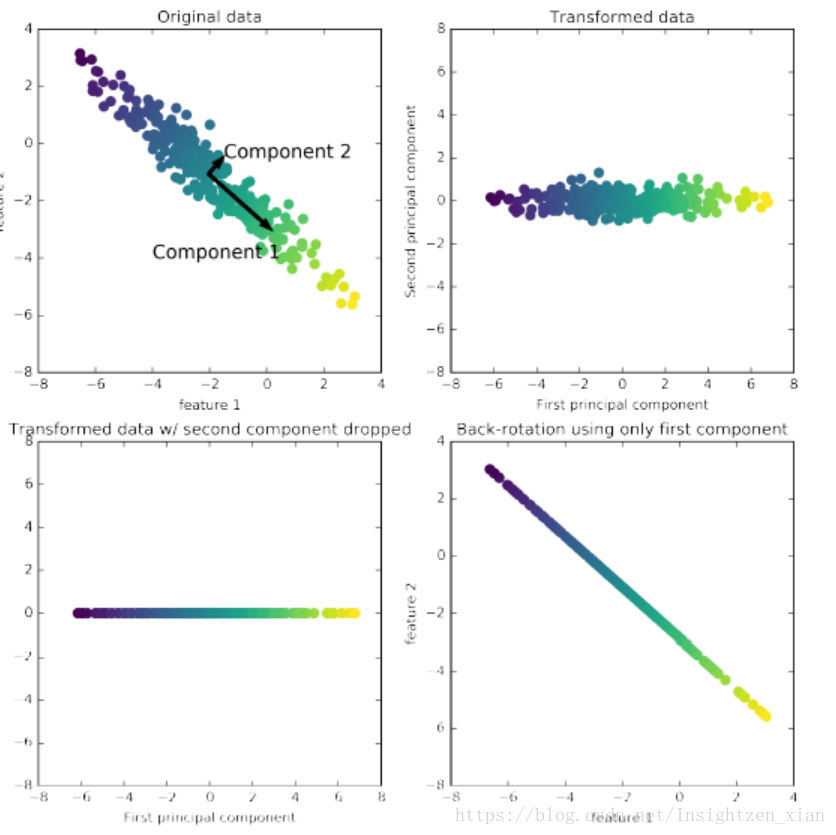
第一个图显示原始数据点,着色以区分点。算法首先找出最大方差的方向,标记为“分量1“。这是数据中包含大多数信息的方向,或者换句话说,这是每一个特征最相关的方向。然后,算法找到与第一方向正交(在直角)时包含最多信息的方向。在二维空间中,只有一个可能的方向是直角,但是在高维空间中会有无穷多个正交方向。通过这种方式找到的方向称之为“Principal Component”,它代表了数据方差的主要方向。
第二个图显示相同的数据,但现在旋转,使得第一主成分与x轴对齐,第二主成分与y轴对齐。在旋转之前,从数据中减去平均值,使得变换数据以零为中心。在PCA发现的旋转表示中,两个轴是不相关的,这意味着该表示中的数据的相关矩阵,除了对角线之外是零。我们可以通过只保留一些主成分来使用PCA进行维数约简。在这个例子中,我们可能只保留第一个主成分,如图三显示。
这将数据从二维数据集减少到一维数据集。但我

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











