







 超级会员免费看
超级会员免费看
文章大纲
简介
文本生成目前主要试用的是GPT-2 模型
基本上只要了解 Transformer 架构,你馬上就懂 GPT-2 了。因為该语言模型的本质上就是 Transformer 里的 Decoder:
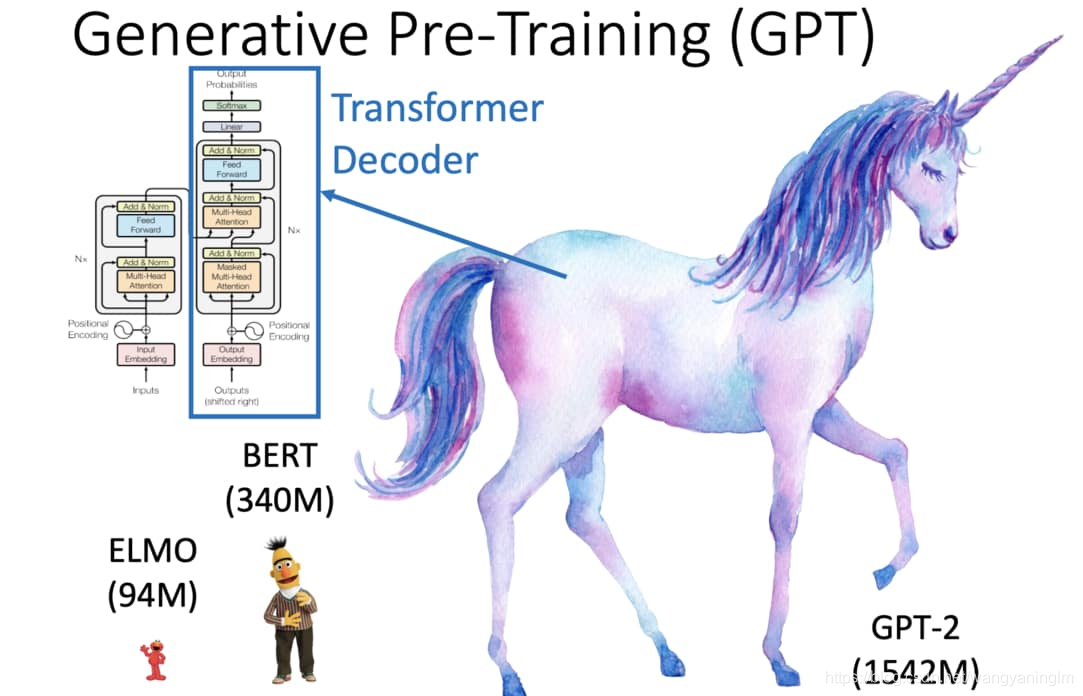
Gpt-2简述
在过去的一年中,BERT、Transformer XL、XLNet 等大型自然语言处理模型轮番在各大自然语言处理任务排行榜上刷新最佳纪录,可谓你方唱罢我登场。其中,GPT-2 由于其稳定、优异的性能吸引了业界的关注
今年涌现出了许多机器学习的精彩应用,令人目不暇接,OpenAI 的 GPT-2 就是其中之一。它在文本生成上有着惊艳的表现,其生成的文本在上下文连贯性和情感表达上都超过了人们对目前阶段语言模型的预期。仅从模型架构而言,GPT-2 并没有特别新颖的架构,它和只带有解码器的 transformer 模型很像。
然而,GPT-2 有着超大的规模,它是一个在海量数据集上训练的基于 transformer 的巨大模型。GPT-2 成功的背后究竟隐藏着什么秘密?本文将带你一起探索取得优异性能的 GPT-2 模型架构,重点阐释其中关键的自注意力(self-attention)层,并且看一看 GPT-2 采用的只有解码器的 transformer 架构在语言建模之外的应用。
作者之前写过一篇相关的介绍性文章「Th

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











