




本文对LSTM的另一篇论文进行解析:Learning to Forget: Continual Prediction with LSTM(Felix A. Gers,1999)。该论文是在论文Long Short-term Memory (Sepp Hochreiter,1997)的基础上提出了遗忘门(forget gate)。
一、为什么要提出遗忘门
Sepp Hochreiter在1999年提出了LSTM算法,该算法是对RNN的改进,论文具体解析详见LSTM思想解析—论文精读(Long Short-Term Memery)Long Short-Term MemeryLSTM思想解析—论文精读(Long Short-Term Memery)。当输入到LSTM中的数据为连续的流数据,这些数据并未预先分割成一个个具有明确起点和终点的子训练集,LSTM就无法自行判断什么时候将记忆单元的状态进行重置,这就会导致状态一直无限地增长,最后导致LSTM无法工作了。
下面通过数学公式来说明LSTM存在的不足:
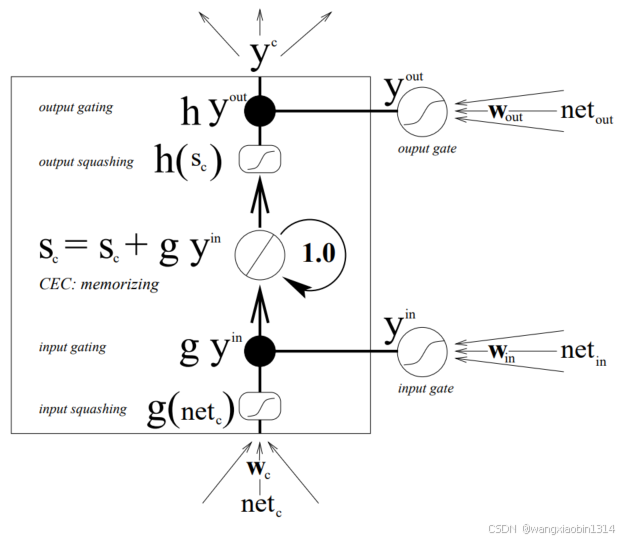
上图为论文Long Short-term Memory 提出的LSTM架构。表示记忆单元的输入,
表示输入门,
表示输出门,
表示记忆单元状态。那么:
(1)
(2)
其中,下标j代表记忆单元块的索引(即第j个记忆单元块),下标v表示记忆单元块中的第v个记忆单元。因此,就表示第j个记忆单元块中的第v个记忆单元。
表示从神经元m到神经元l的权重。
激活函数f是sigmoid函数: (3)
该记忆单元自身的输入(t-1时刻的输出,变为t时刻该记忆单元的输入):
(4)
激活函数g是sigmoid函数的变种: (5)
记忆单元状态: 对于t>0 (6)
记忆单元输出: (7)
h为激活函数 (8)
假定LSTM网络有一个输入层、一个隐藏层(由记忆单元组成)和一个输出层,那输出层的第k个神经元输出为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









