









 本文深入解析Network in Network(NIN)架构,介绍如何利用多层感知机(MLP)替代传统CNN中的广义线性模型(GLM),增强模型对局部特征的辨识能力及非线性。同时,引入全局平均池化概念,解决全连接层的过拟合问题,提升模型鲁棒性。
本文深入解析Network in Network(NIN)架构,介绍如何利用多层感知机(MLP)替代传统CNN中的广义线性模型(GLM),增强模型对局部特征的辨识能力及非线性。同时,引入全局平均池化概念,解决全连接层的过拟合问题,提升模型鲁棒性。
Network in Network
简介
本文将传统CNN中的GLM(generalized linear model)替换为MLP(Multi layer perception)从而增加模型对感受野中局部特征的辨别能力增加非线性,并引入了global average pooling的概念来代替全连接网络(有特征分类的过拟合问题)。
结构
用多个多层感知机+激活函数 代替卷积层运算:
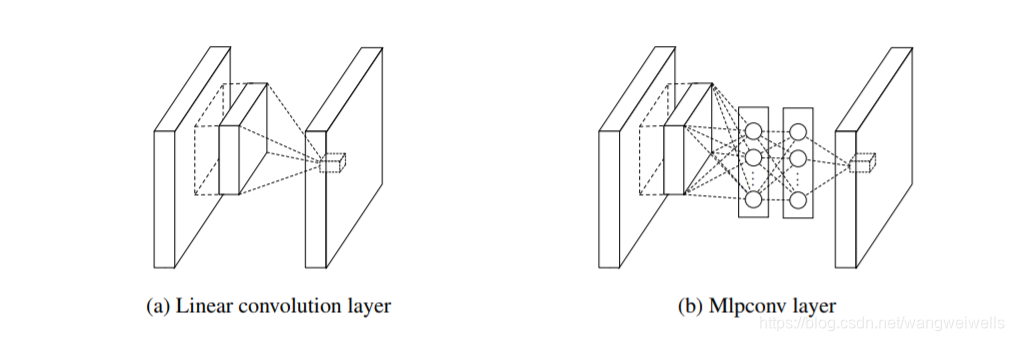
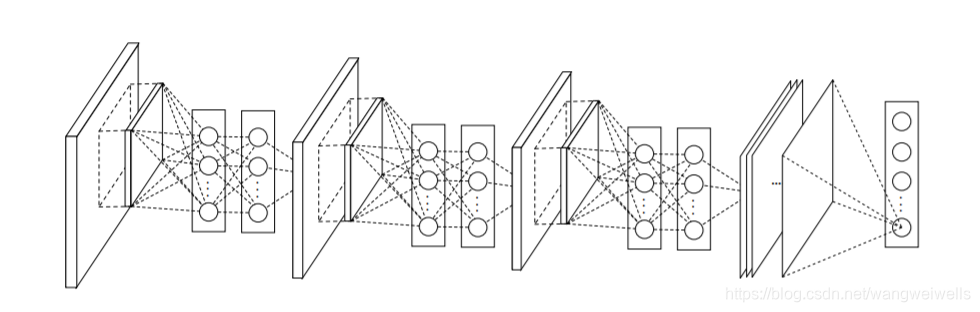
过程
- MLP Convolution Layers的实现
f i , j , k 1 1 = m a x ( w k 1 1 T x i , j + b k 1 , 0 ) . . . f i , j , k n n = m a x ( w k 1 n T f i , j n − 1 + b k n , 0 ) f^1_{i,j,k_1} = max({w^1_{k_1}}^{T}x_{i,j}+b_{k1},0)\\ .\\ .\\ .\\ f^n_{i,j,k_n} = max({w^n_{k_1}}^{T}f^{n-1}_{i,j}+b_{kn},0) fi,j,k11=max(wk11Txi,j+bk1,0)...fi,j,knn=max(wk1nTfi,jn−1+bkn,0)
The cross channel parametric pooling layer is also equivalent to a convolution layer with 1x1 convolution kernel. This interpretation makes it straightforawrd to understand the structure of NIN.
-
不过在具体实现的时候,以第一层举例,先进行一个 11 × 11 11\times11 11×11的卷积(步长为4,实现了图像压缩),后接Relu再接 1 × 1 1\times1 1×1的卷积核+Relu来代替多层感知机。
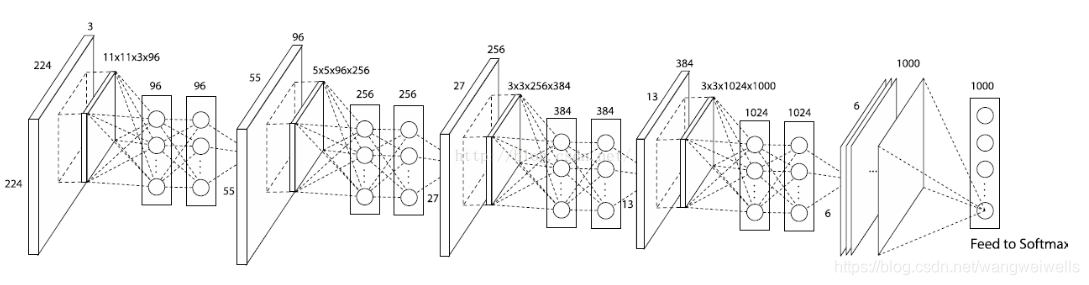
-
Global Average Pooling的实现
最后一层的feature map or confidence map全图求平均
为什么
为什么去掉CNN并改成MLP?
- 传统CNN通过 迭代(CONV+POOLING+ACTIVATION FUNCTION)来提取图象特征并引入非线性,提高模型表达能力。conv filter依然是广义线性模型,通过这中操作得到的特性是低抽象性的(我们想要达到同样concept下的特征抽象结果可以保持不变)。它默认为这些concept是线性可分的,然而有些concept 并不容易线性区分。用更有效的非线性函数代替GLM可以增强局部模型的抽象能力并提高特征的区分度。
- 浅层使用卷积网络后层使用Fc网络很容易overfitting, 需采用dropout。
First, multilayer perceptron is compatible with the structure of convolutional neural networks, which is trained using back-propagation. Second, multilayer perceptron can be a deep model itself, which is consistent with the spirit of feature re-use
为什么用 Global Average Pooling?
作者说了三点:
One advantage of global average pooling over the fully connected layers is that it is more native to the convolution structure by enforcing correspondences between feature maps and categories. Thus the feature maps can be easily interpreted as categories confidence maps.
- 与卷积结构更相似,与特征分类图联系更紧密,更容易获取特征。
Another advantage is that there is no parameter to optimize in the global average pooling thus overfitting is avoided at this layer.
- 不需要学习参数,去校正优化,避免overfitting
Futhermore, global average pooling sums out the spatial information, thus it is more robust to spatial translations of the input
- 累加了空间信息,更鲁棒
根据部分代码和论文内容可知,作者似乎是用11x11 conv+ relu + 1x1 conv +relu 代替多层感知机过程,为什么?具体又是怎么等效的呢?又是怎样处理等效多层感知机隐藏结点的运算的?
-
Equation 2 is equivalent to cascaded cross channel parametric pooling on a normal convolution layer. Each pooling layer performs weighted linear recombination on the input feature maps, which then go through a rectifier linear unit. The cross channel pooled feature maps are cross channel pooled again and again in the next layers. This cascaded cross channel parameteric pooling structure allows complex and learnable interactions of cross channel information. The cross channel parametric pooling layer is also equivalent to a convolution layer with 1x1 convolution kernel. This interpretation makes it straightforawrd to understand the structure of NIN.
1x1的卷积运算相当于做了一个多通道的线性组合变换
- - 待研究
感知机与卷积运算的变换?
- - 待研究
MIN 与 MAXOUT ?
- 拟合能力MIN 更大
Mlpconv layer differs from maxout layer in that the convex function approximator is replaced by a universal function approximator, which has greater capability in modeling various distributions of latent concepts
- - 待进一步细看
代码1
代码中,直接用11x11 conv+ relu + 1x1 conv +relu 代替多层感知机过程:
layers {
bottom: "data"
top: "conv1"
name: "conv1"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
mean: 0
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "conv1"
top: "conv1"
name: "relu0"
type: RELU
}
layers {
bottom: "conv1"
top: "cccp1"
name: "cccp1"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "cccp1"
top: "cccp1"
name: "relu1"
type: RELU
}
layers {
bottom: "cccp1"
top: "cccp2"
name: "cccp2"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "cccp2"
top: "cccp2"
name: "relu2"
type: RELU
}
思考
TO BE CONTINUE
参考文献
1.https://hackmd.io/2mQ20WNhRSCC4DKXhjhMNA
2.https://gist.github.com/mavenlin/d802a5849de39225bcc6
3.https://blog.youkuaiyun.com/hjimce/article/details/50458190
待研究参考
- https://blog.youkuaiyun.com/ld326/article/details/78933478
- https://blog.youkuaiyun.com/lanchunhui/article/details/51248510
见参考文献2 ↩︎

















 9033
9033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









