







 本文探讨生成模型在无监督学习中的应用,如PixelRNN、VAE等,展示机器如何模仿创造力,生成新图片和诗歌,揭示其在理解和生成复杂数据方面的能力。
本文探讨生成模型在无监督学习中的应用,如PixelRNN、VAE等,展示机器如何模仿创造力,生成新图片和诗歌,揭示其在理解和生成复杂数据方面的能力。
让机器有有创造力
我们知道机器是可以学习我们告诉他的东西,也可以学习没有标签的东西,但是能不能让他自己有创造力呢,这个是可以有的,比如让他看了很多动漫头像后,他自己能不能尝试着画出来没出现过的,或者让他读了很多诗之后自己写几句:
所以牛人门开始研究生成模型,比如openai发过的文章,开头引用了费曼黑板上的话,意思是说没有自己做出来不算是真正搞懂的,或许我们让机器去分类猫和狗,但是他其实并不知道什么是猫,什么是狗:

所以如果他能画出来狗或者猫的图像,或许他才能真正的理解:

生成模型
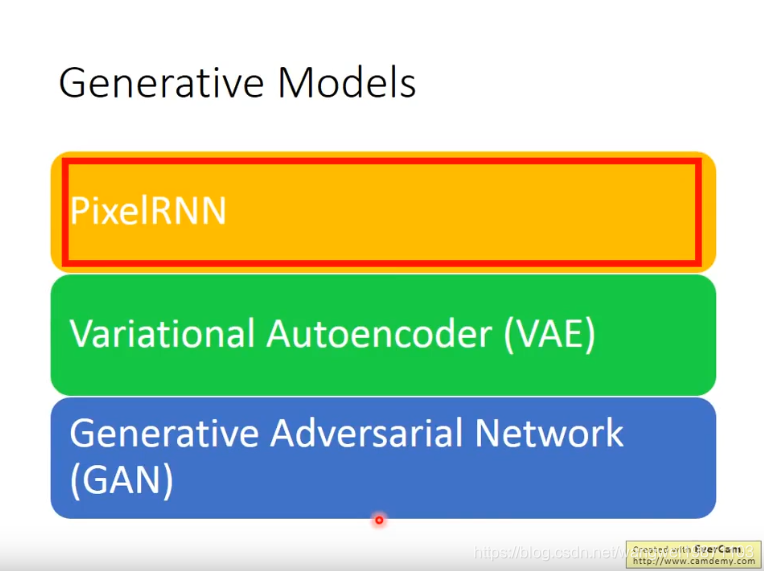
下面介绍几种生成模型:
PixelRNN
这个其实看起来像RNN的那种循环输入,RNN后面会讲到。他做的一件事就是我现在要生成一个图片,但是我只给了一个像素点,让机器根据这个点去生成整个图片,机器会根据之前生成的点来生成下一个点,比如那生成3x3图片的例子来说,最开始有一个初始的点,把他输入到一个神经网络,得到一个新的点,把他作为第二个点:

然后现在的图是这样:

然后拿这个两个点做输入,得到第三个点,可能有人会问,这个输入个数变了,这个可以用RNN处理,后面学到的时候就知道了:

然后现在的图是这样:

然后我们继续这样做,直到生成9个像素为止:
我们最后得到:

有人会问,这个能行么,当然行啦,我们拿别人做的实验来说下,左边是一张狗的图,机器没看到过的,我们把狗的下半身遮住,然后让机器来补全,最后发现他会补全,但是很奇怪,或许他的训练图片里都是这样的下半身,所以他大概率都补全成这样:

当然也可以用在语音合成上,比如著名的WaveNet,他就是用类似的方法,把生成出来的新点加到输入中,继续生成后面的点:

来举一个我们比较熟悉的例子,又是宝可梦哈哈,李宏毅老师比较喜欢,我们现在不去抓宝可梦,而是去创造新的宝可梦,原始的宝可梦图是40x40的,我们缩小到20x20:

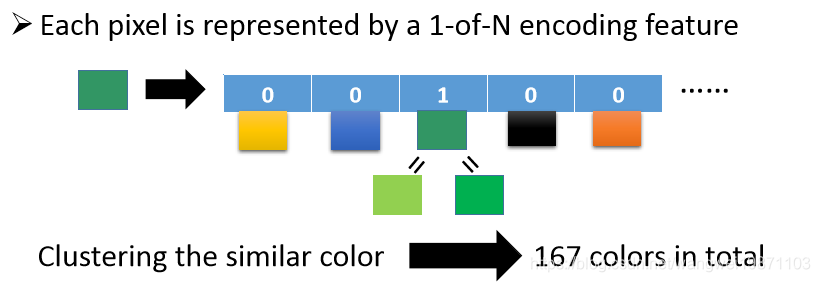
我们知道像素是RGB三个颜色合起来的值,但是如果三个颜色都比较接近,点就比较暗:
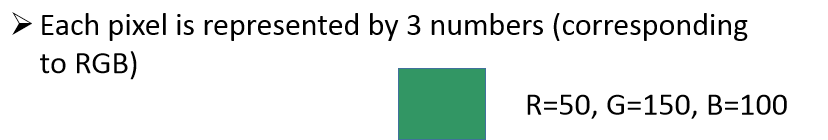
所以我们做了个处理,把每个颜色的用1-of-N encoding向量来处理,那这样有很多颜色,不是很麻烦么,没事,我们再做一层聚类,把相似的颜色用同一个向量来表示,最后发现颜色有167个:
下面老师把处理好的图片文件,每一行是一个宝可梦,数字所代表的颜色在图右边,接下来用一个512的LSTM来训练,LSTM是RNN的一种,后面文章会讲到:

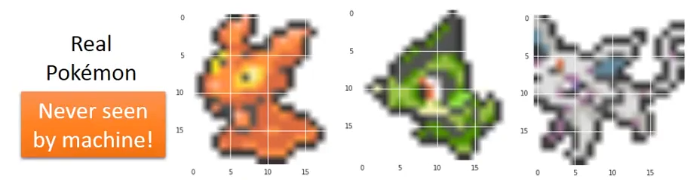
训练完后我们做生成测试,我们拿机器没看过的图片:
如果只给他看50%的部分:
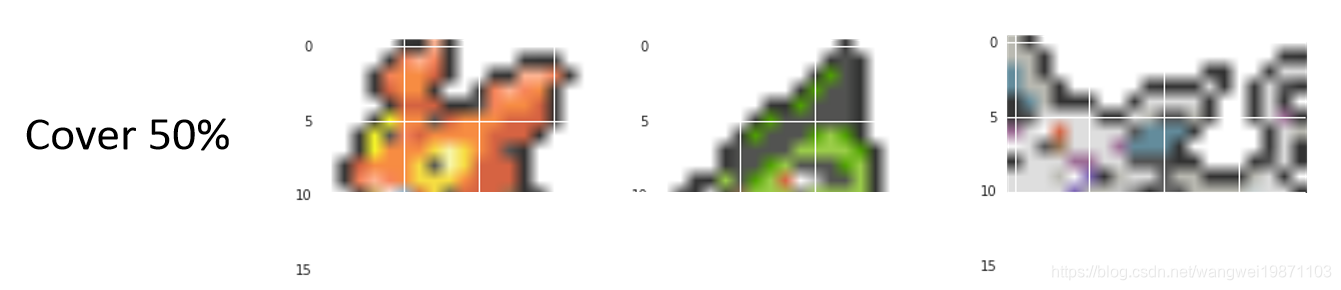
他补全的结果如下,左边的好像穿了个背带裤,中间的变长了,右边的把身体和脚生成出来了,效果还不错:
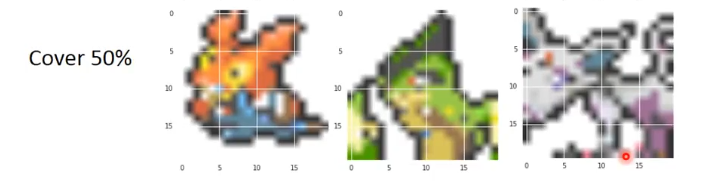
再来看看只给25%:
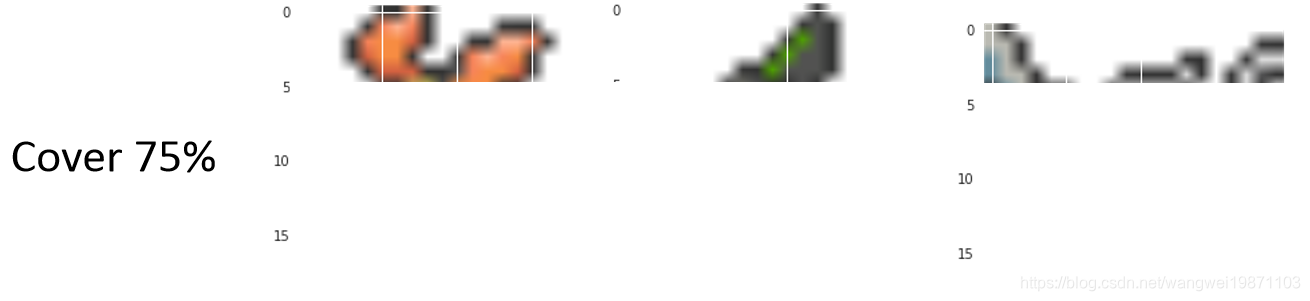
结果左边好像变腊肠了,中间产生了一个眼睛,右边产生了一个兔子的脸,还有耳朵:
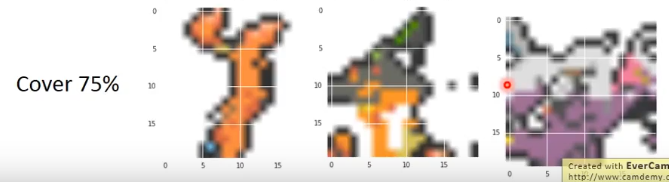
如果让他从头开始画呢,好像有点有意思的图案,但是不太看的出是什么:

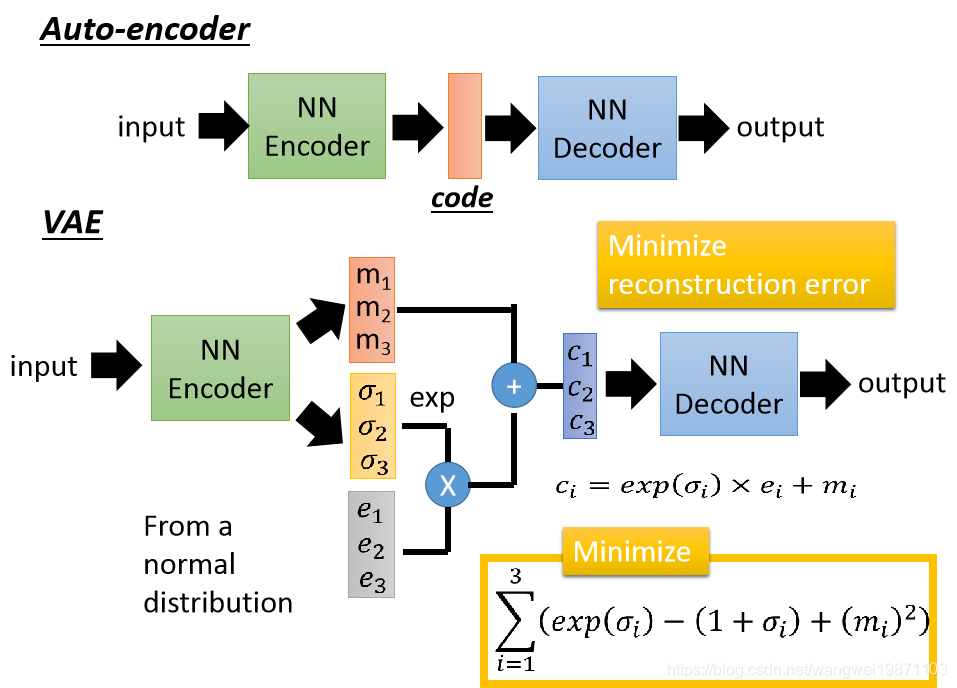
VAE
先看看我们之前的自编码器的结构,输入一张图片,生成一个code,然后再还原,我们能不能控制产生什么样的图片呢,能不能通过调节code来生成一些我们想要的图片:
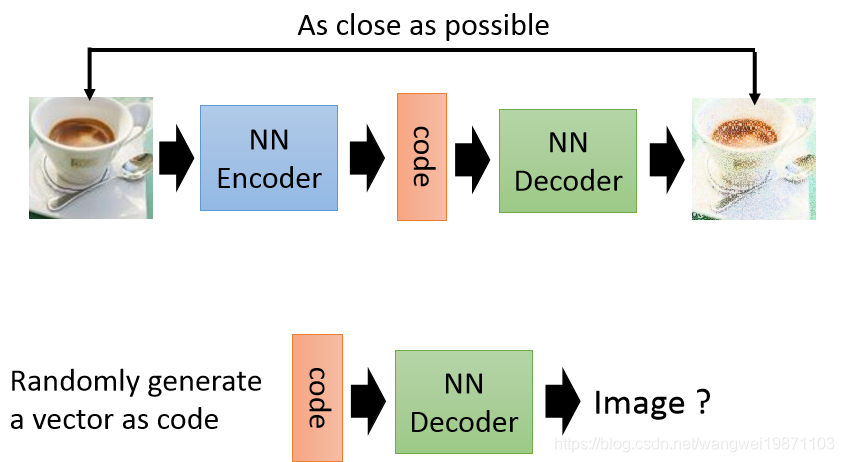
我们可以在code这层做点改变,让他变成从某个高斯混合分布里采样出来的code,具体的理论可以看我写的文章,我就不多说了:
这个是openai在cifar-10上的结果,还挺奇怪的:

但是我们已经可以控制生成的一些特征了,比如宝可梦的例子,生产了一个10维的向量,我们固定其中的8维,然后把剩下的两维采样很多的点,生成很多个图,然后观察他们之间的变化,这样我们就可以知道这两个维度是干嘛的,也就可以取不同的值对生成的图片进行调整,同样的方法可以确定所有的维度代表着什么意义:
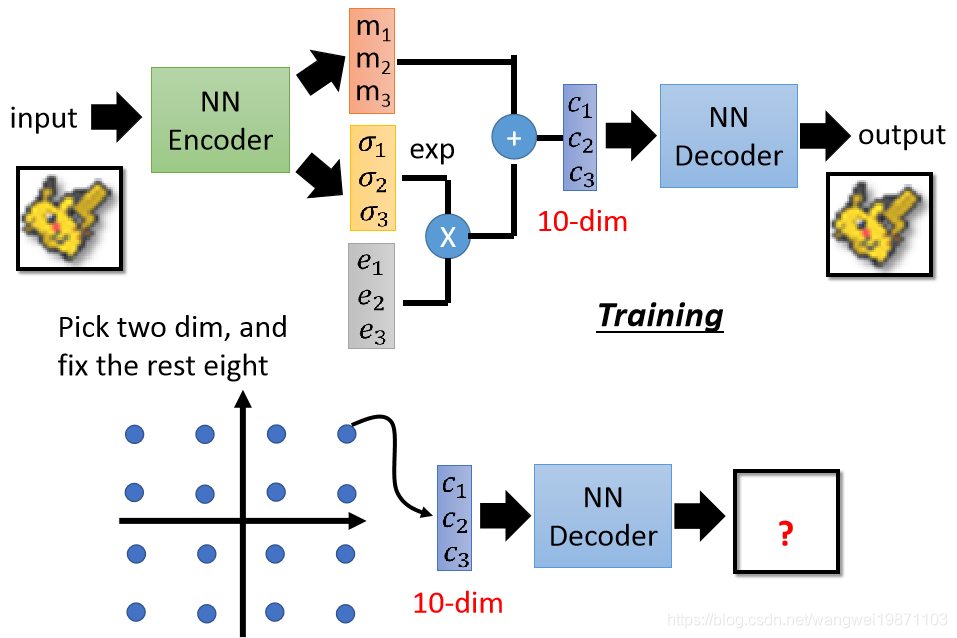
我们来看看变化了两个维度的结果,很明显左到右,好像是站起来了,上到下好像是爬下去了,这样我们就可以控制这两个维度来调节这两个特征:

如何用VAE来写诗呢,原理是一样的,输入一句诗,转成一个code,然后输出一句诗:
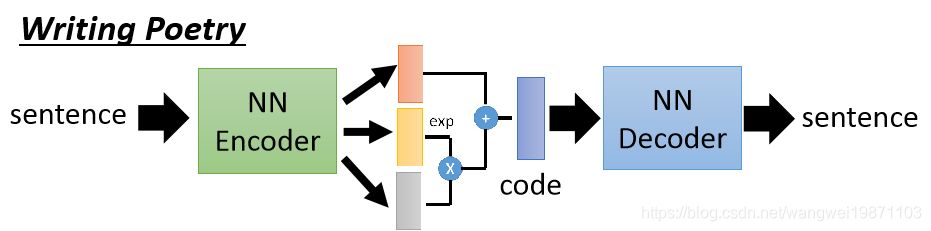
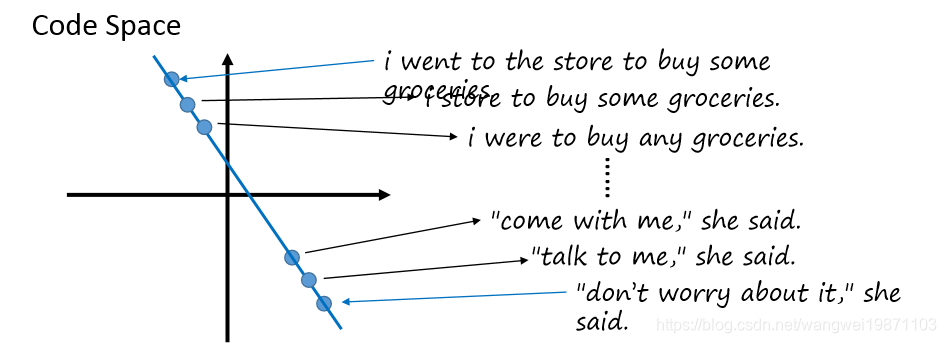
比如我们有两句话,我们把他们的code找出来,然后在明天之间等间隔采样一些code,然后用解码器解码,就可以写出一些句子了:
总结
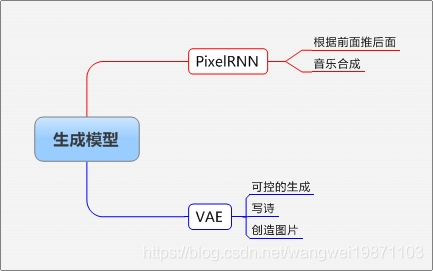
本篇主要介绍了一些生成模型,可以用来创造东西,后面还有个GAN可以看我其他的文章,有一个GAN系列,后面会讲。附思维导图:
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,图片来自李宏毅课件,侵删。

















 7266
7266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









