







 本文深入解析自编码器原理,涵盖其在图像压缩、文本处理、去噪及生成新内容等领域的应用,展示自编码器的强大功能。
本文深入解析自编码器原理,涵盖其在图像压缩、文本处理、去噪及生成新内容等领域的应用,展示自编码器的强大功能。
李宏毅机器学习系列-无监督学习之自编码器
自编码器是什么
先举个例子,比如我们用一个神经网络要把一张图片压成一个code,希望这个code的维度比图片小,我们有很多的图片,但是没有code的标签,也就是我们有输入,没有输出,好像没办法学习:
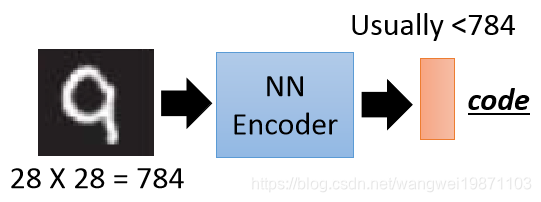
同理我们可以给一个随机的code,通过一个网络输出一堆图片,我们有输出的图片,但是我们不知道code,好像也没办法训练:

但是如果我们把前面两个网络接起来,貌似是可以的:
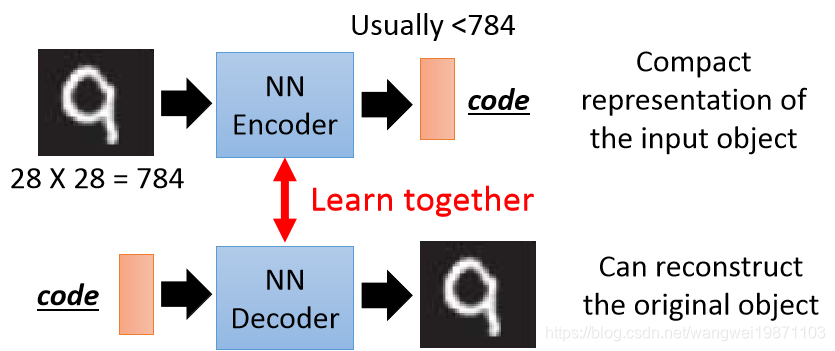
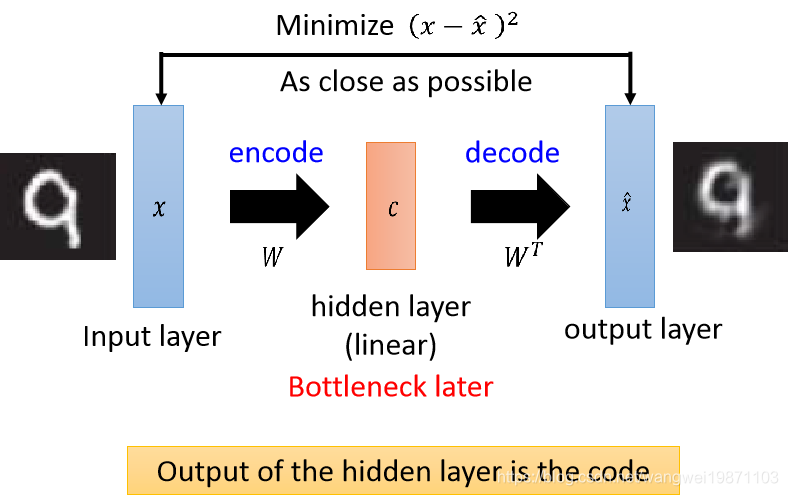
前面讲过PCA可以用神经网络训练,也就是将输入
x
x
x通过一个矩阵W变换为一个向量c,然后在用c通过W的转置变换为一个
x
^
\hat x
x^,然后希望
x
,
x
^
x,\hat x
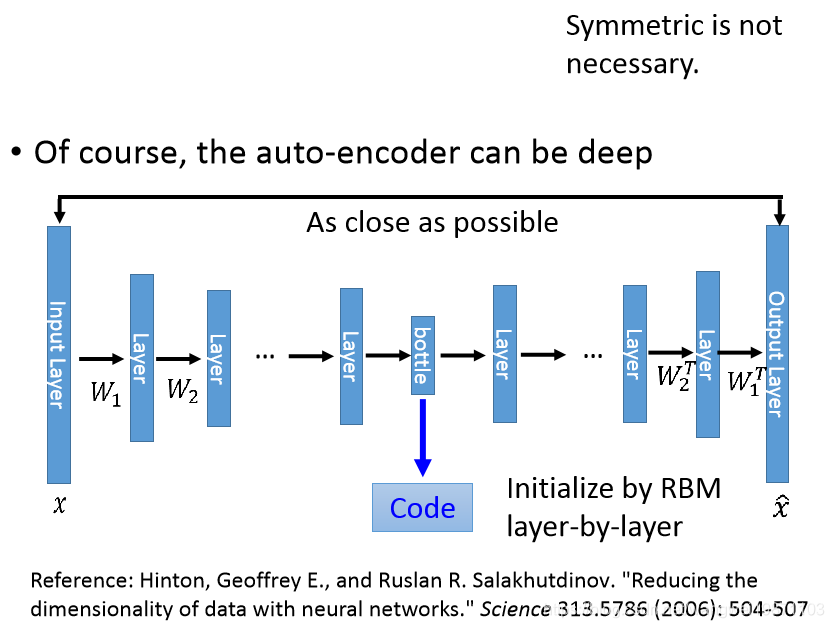
x,x^的差距越小越好,我们把中间的向量c层叫做瓶颈层,因为他维度比输入小,所以很短,像瓶颈一样,这个就是一个单层的自编码器,那能不能是更深的呢:
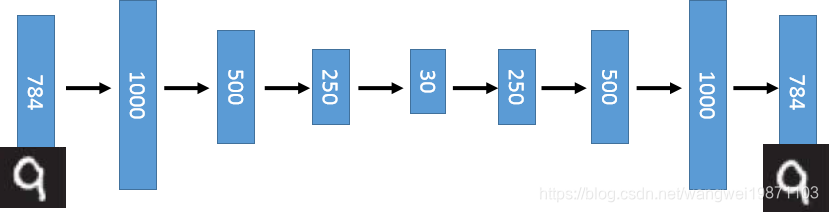
我们来看看深层的自编码器,原理的一样的,只是中间的层数变多了,既然是神经网络,参数W是学出来的,就没必要是对称的了:
我们来看下深度自编码器的效果,很明显,要比PCA清晰很多:

PCA其实就只是做了那么一层:
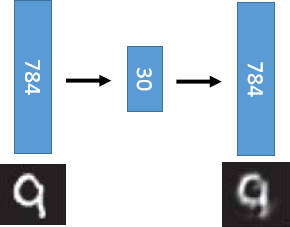
但是深度自编码器是这样,或许因为层数多了,处理的更加精确了,留下了更多细节,可能会比较清晰:
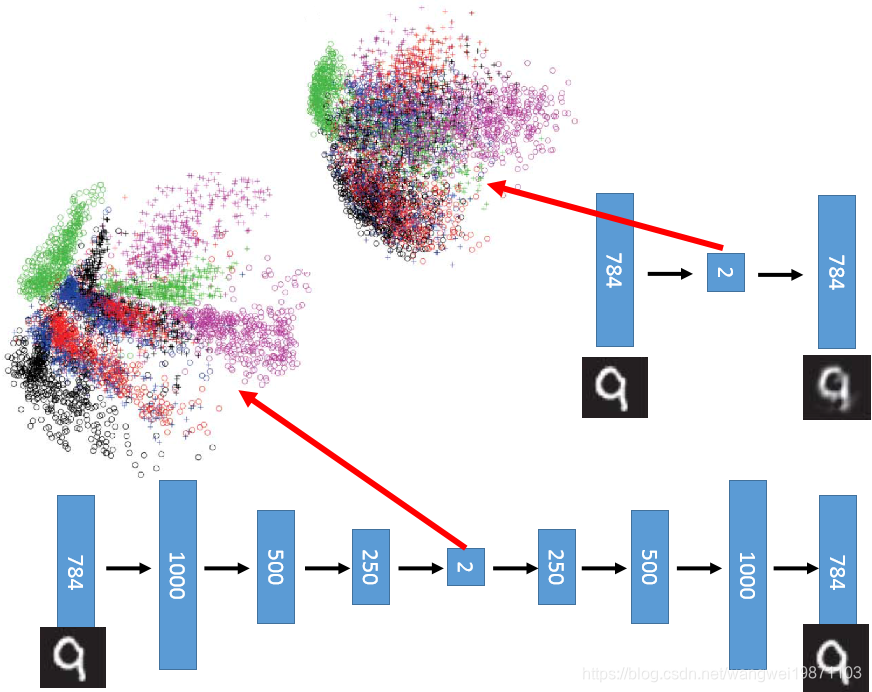
如果我们把他们都压缩到二维来看看他们的分布,可以看到PCA不同的数字之间还是混在一起的多,而深度自编码器是能比较好的区分的:
自编码器文字处理
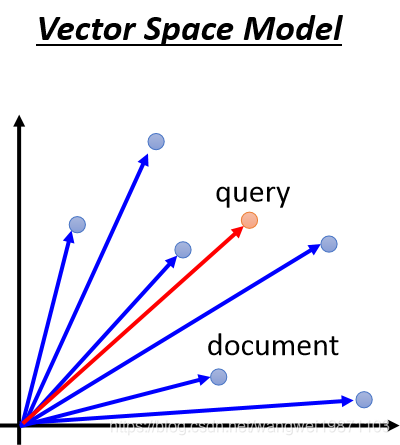
我们可以把自编码器用在文字处理上,我们会把一篇文章压成一个向量,为什么要这么做的,这样做我们就可以做文字搜索,具体来看看是怎么做的吧。我们通常会有一个向量空间模型,我们把很多的文章压成向量,如果来了一格搜索词,我们把他也放进这个空间里,然后看他跟哪些文章的向量距离比较近,或者预先相似度比较高,我们就会把这些文章选出来,比如下面的红色点是搜索的词,那应该会选出左边的那篇文章了:
那这个模型好不好用,取决于怎么来表示这些文章向量,有一个叫Bag-of-word的方法,每一个单词一个维度,如果有10万个单词,那就是10万维的,但是这样不能表达句子之间的语义关系,他的每一个词之间都是无关的:
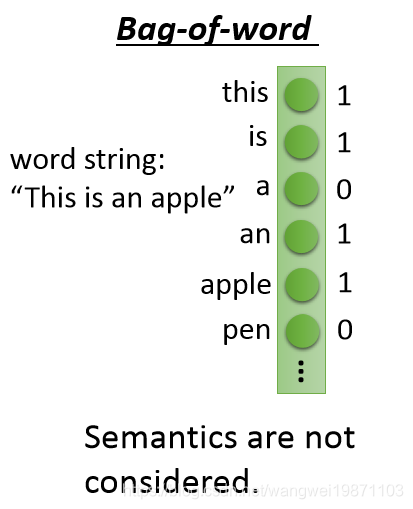
但是我们可以自编码器最后压倒二维,比如下图:
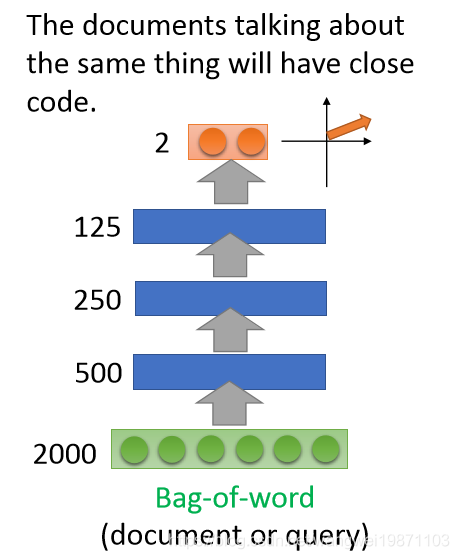
编码后的分布为下图,其实挺清楚了,他把一些文章都分类了,然后我们的搜索词就是大的红色的点,可以看到,离’Energy markets’比较近,所以他会把相关的文章给找出来:
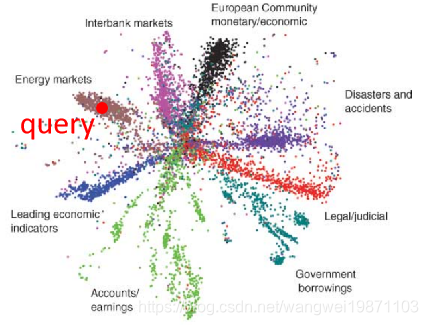
如果用LSA的话是这个样子,可能矩阵转换的效果还不够吧:

自编码器搜索相似图片
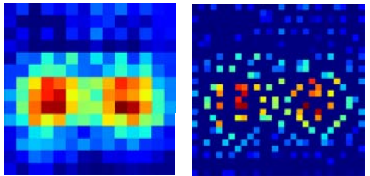
假如我们要找出跟迈克尔杰克逊相似的图片,根据像素点的相似来找的话,我们可能找到下面的图,有马蹄和头盔,是不是很奇怪啊,因为是像素相似度,只是考虑了像素值是不是相近:

如果我们用自编码器来训练的话,把图片压成256维度的向量,进行编码,然后解码:
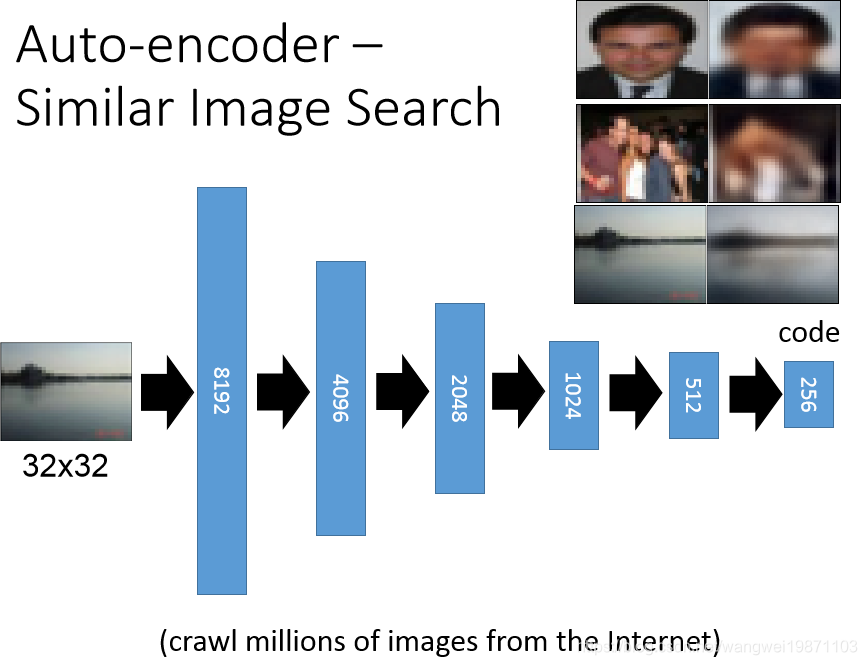
最后找出来的效果是这样的,确实比直接用像素相似要好一点,虽然看起来不是很像,但是通过编码后的向量还是很相似的:

自编码器预训练DNN
自编码器还可以用于预训练模型,比如我们要把MNIST图片压缩到10维,我们可以一层层的训练,首先训练1000个神经元的那层,这个时候要小心,网络可能会直接把784的数值复制过去,学不到什么东西,也就是会过拟合,所以遇到隐藏层神经元个数比输入还要大的时候需要一定的正则化,比如L1正则化:
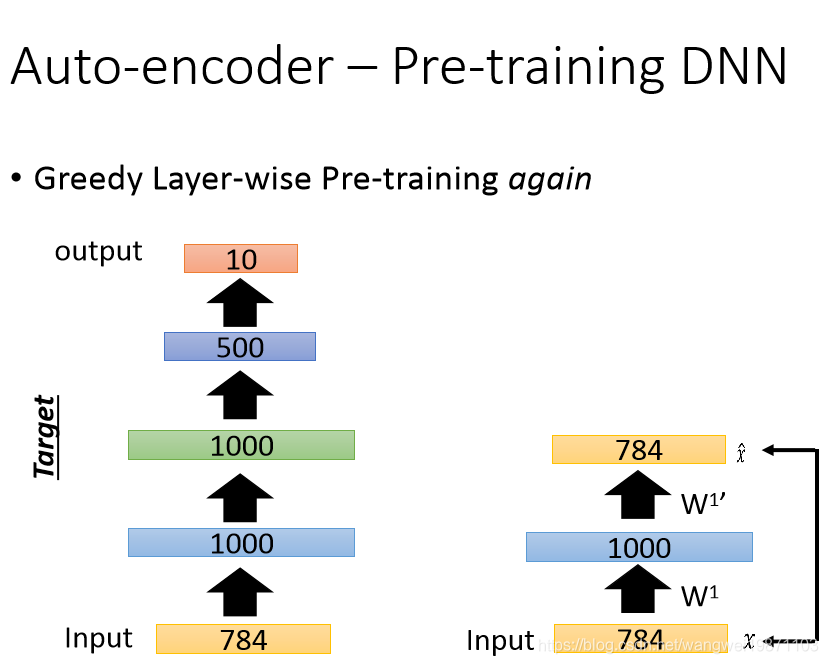
然后固定住第一层参数,训练第二层:
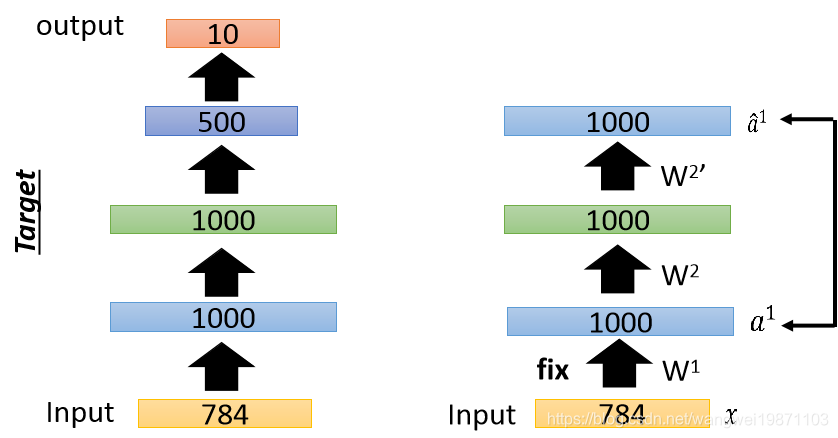
然后固定第二次参数,训练第三层:
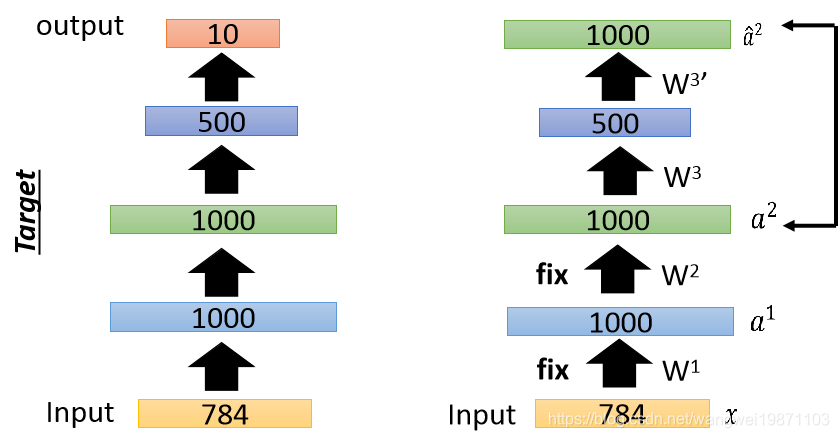
最后再进行微调:
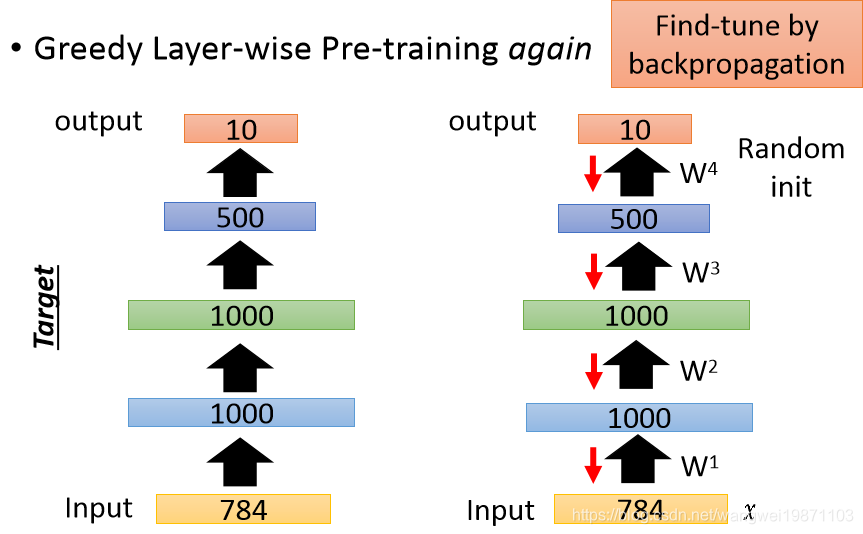
这个技术以前还很有用,但是现在基本不太需要了,可以直接训练。
自编码器去噪
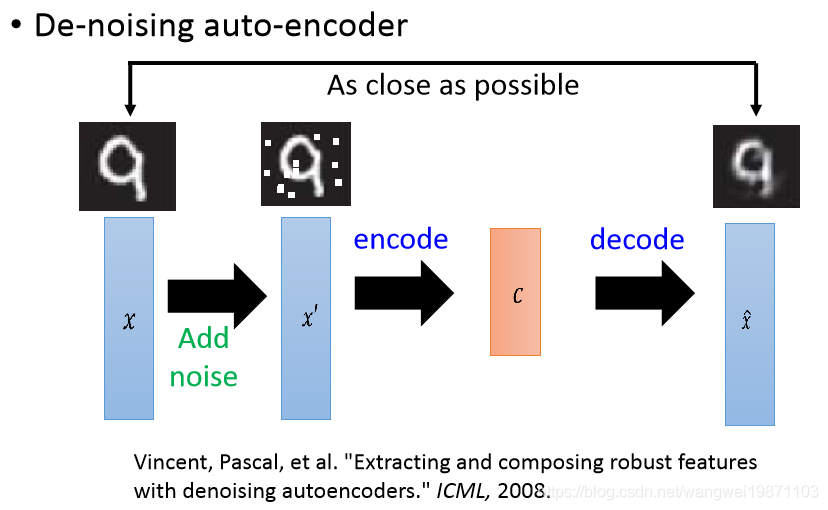
自编码器可以用在很多地方,比如去噪,我们把原来的图片加上噪声,然后放进去训练,他可以有去噪的功能:
还有几个参考的网络有兴趣可以看下:


自编码器用于CNN
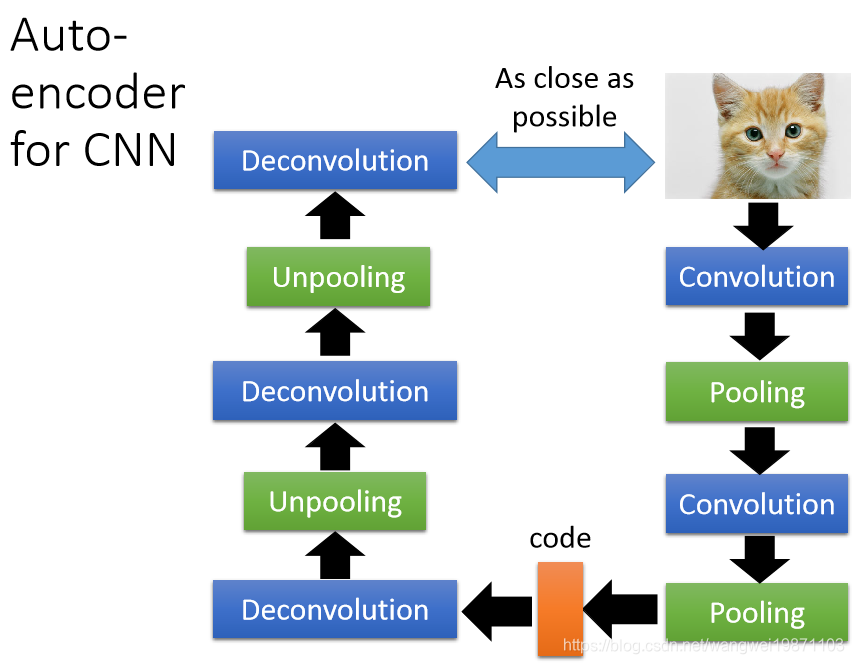
我们知道CNN里面会进行卷积核池化,那如果用自编码器我们就需要反采样和反卷积,其实应该叫上采样和反卷积:
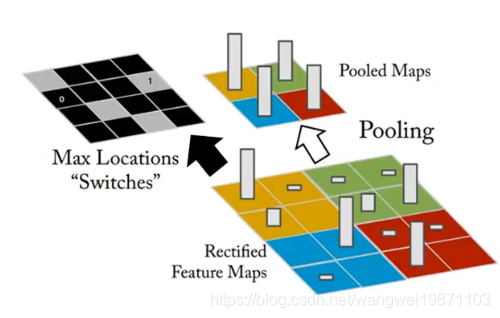
我们先来回顾下池化是怎么做的,比如最大池化,他就是把区域内最大的选出来,然后放一起:
那反过来怎么做的,这个过程也叫上采样,需要有之前位置的记录,记录最大值是从哪个位置采样出来的,然后恢复到那个位置,其他地方补0:
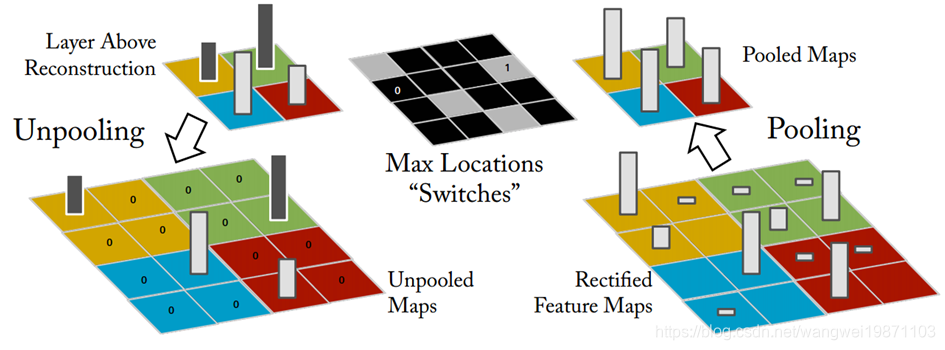
看看效果,会更加分散:
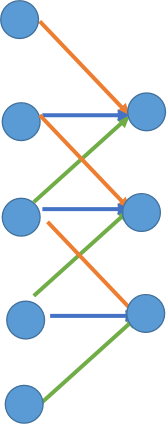
再来看看反卷积是怎么做的,先看下卷积操作,比如3X3的卷积核,步长为1.作用在5x5的图上:
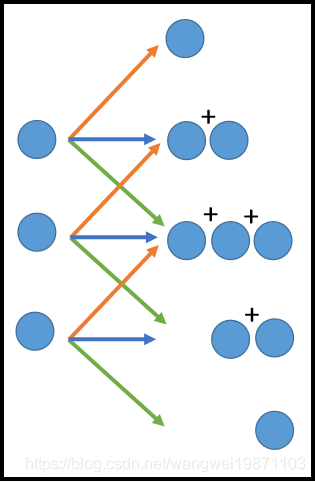
那我们反过来就应该这样做:
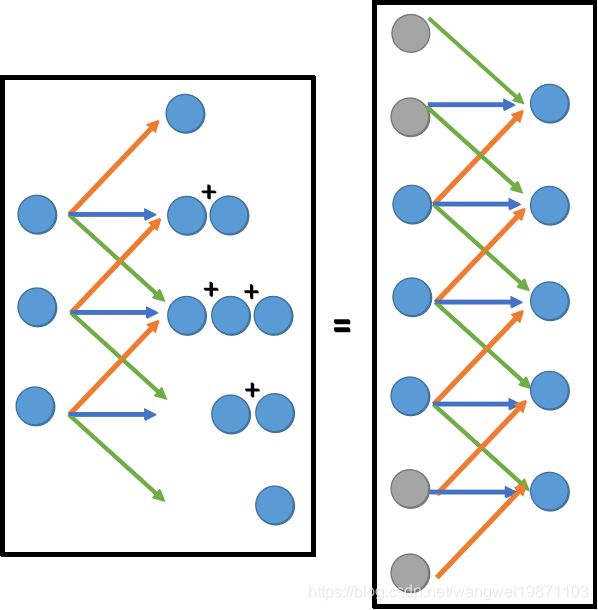
其实这样可以等价于padding后的卷积,如果在上下补0的话,再来一次卷积,可以得到原始的5x5的图,也就是说反卷积其实就是卷积操作,padding了0而已:
自编码器可当做生成器
如果我们拿自编码器后面的解码部分,随机输入一个code,就可以得到一张新的图片,比如下面的MNIST的例子,如果在压缩到二维的code上等距离采样一个红色的框区域,得到的数字图就是右边的,很多图片是新生产的:
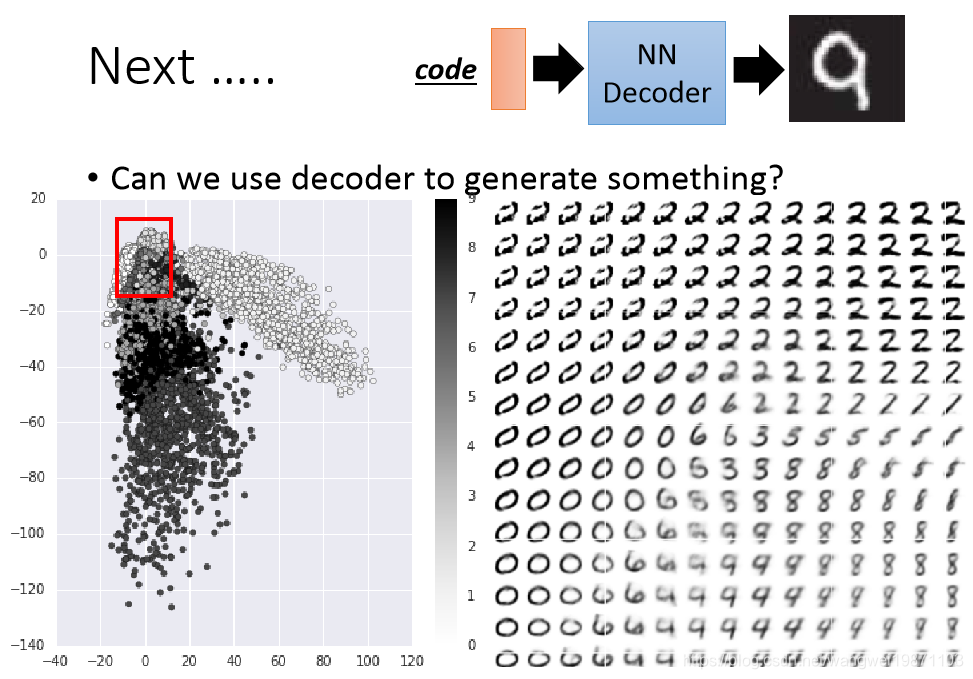
我们可以看到图片的左上角的图片好像不是数字,因为对应二维空间里也没有code,也就是说我们要采样出数字,还得分析code的分布,不然可能采样出很奇怪的图片,那有没什么办法可以采样到数字呢,可以对code加L2的正则化,让他都接近0,然后再0附近采样,可能出来的都是数字,我们来看看:
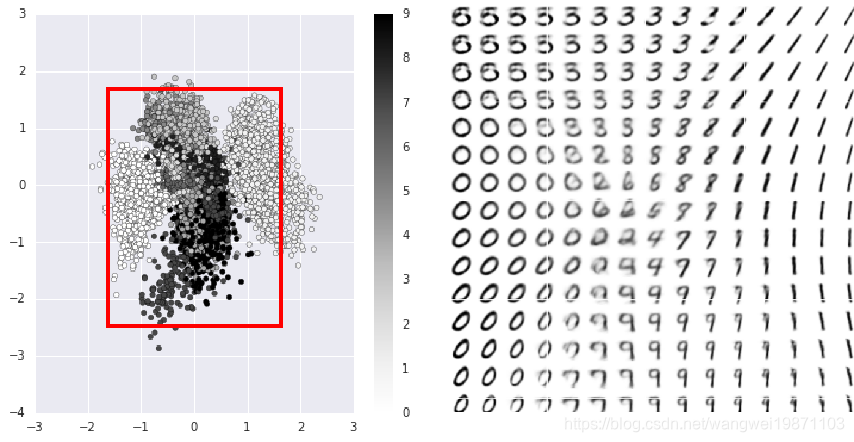
果然上图显示的基本都是数字了,而且可以看到横轴从左到右的特性好像把圈变没了,纵轴是角度变了。所以是不是很神奇,机器自己画出了不存在的东西。
总结
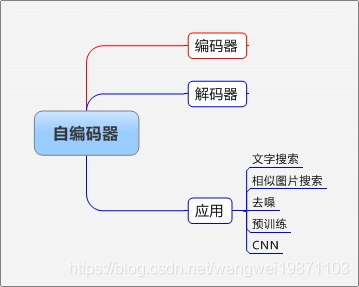
本篇主要介绍了自编码器的原理和结构,也举了一些应用,最后发现它还能生成不存在的东西,很神奇,其实还有个很厉害的技术,叫GAN,可以生成不存在的东西,效果更好,有兴趣的可以看看我写的一些文章。同时我也有自编码器的应用文章,可以看看更好的理解下。附思维导图:
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,图片来自李宏毅课件,侵删。


















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









