




 本文介绍了无监督学习中的生成模型,包括Component-by-Component、AutoEncoder和GAN。生成模型学习样本数据分布,用于创建新数据。AutoEncoder通过降维和重构数据,VAE通过加入噪声确保code分布,而GAN通过生成器和判别器的对抗训练来生成逼真图像。
本文介绍了无监督学习中的生成模型,包括Component-by-Component、AutoEncoder和GAN。生成模型学习样本数据分布,用于创建新数据。AutoEncoder通过降维和重构数据,VAE通过加入噪声确保code分布,而GAN通过生成器和判别器的对抗训练来生成逼真图像。
🚀 优质资源分享 🚀
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| 💛Python量化交易实战💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
前面无监督学习主要针对的是一种“降维”的学习任务,将数据降维到另一个能够表达数据含义的某种空间中,本节主要是无监督学习中的另一个任务——生成进行介绍。
生成模型
0.生成模型介绍
通常生成模型是指学习样本数据的分布,可以生成一些新的数据,是相对于判别模型而言的,并不特指有监督学习和无监督学习,比如朴素贝叶斯模型就是一种生成模型。
在这里生成模型主要指的是无监督学习中的生成模型,在无监督学习中的主要任务是让机器学习给定的样本,然后生成一些新的东西出来。比如:

给机器看一些图片,能够生成一些新的图片出来,给机器读一些诗,然后能够自己写诗出来。
在前面所学习的无监督学习主要是针对降维的,成为化繁为简,那么在这里的生成模型则称之为无中生有。
有三种常见的生成模型:
1、Component-by-Component
2、AutoEncoder
3、Generative Adversarial NetWork(GAN)
下面就对这三种方法进行简单的介绍,这里还是主要介绍其大致概念,后面深度学习会具体展开讨论。
1.Component-by-Component
这种方法类似于前面说的Predicted-based的方法,即根据前面的来预测后面的。比如一张3*3大小的图片:
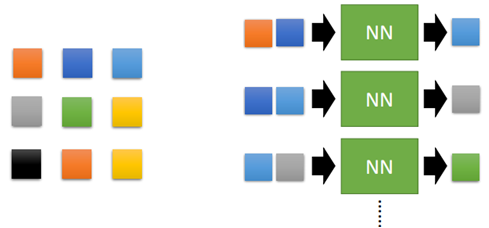
我们希望有一个网络,输入相邻的两个像素,然后输出下一个像素。通过大量的图片来训练网络,然后给定一个初始的像素,就可以生成一张新的图片出来。
又或者通过阅读大量的文章,然后输出一张新的文章出来。
这个任务也称作Seq2Seq的学习任务,其网络主要用的就是RNN。后面到深度学习部分会对RNN再进行了解。这里先举个简单的例子:让机器自己创造一些宝可梦出来。
通过大量的宝可梦的图片训练一个网络,然后让这个网络生成一些图片出来,如图:

在测试时,首先拿一些真实的宝可梦的图片,然后盖住一部分,比如盖住50%,让机器生成这50%的图片,可以得到如右图所示的结果(并非对应关系)。
2.AutoEncoder
2.1 Review AutoEncoder
在前面说过AutoEncoder的基本概念,即通过encoder对数据的降维,而在生成模型中,decoder则可以用来生成新的数据出来。
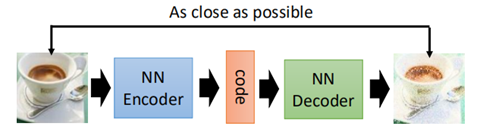
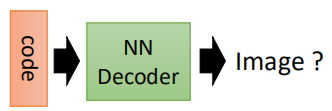
当把AutoEncoder的网络层数增加时,就变成了deep AutoEncoder。通过给定一个code,然后输入到decoder中,就会产生新的image出来。
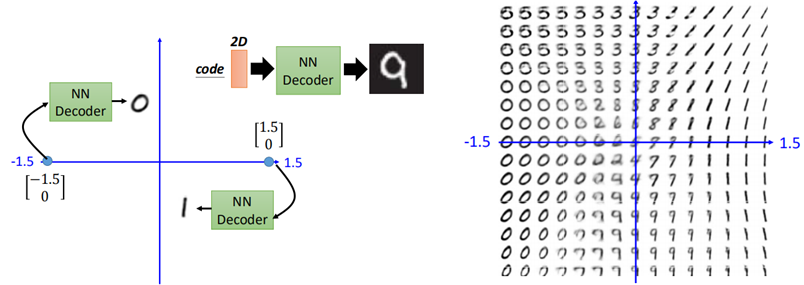
比如在手写识别中,数据降到2维后,给定一个二维code,则可以生成一张手写数字出来。
然而在实际中,通常对于未知的code,我们并不能保证所给的code与产生的图片属于同一个分布,这也就可能会导致当给一个code时,所生成的图片是一个“四不像”,与预期不符。
比如对于月球图片的学习,将图片降到1维(中间红色的线),然后再decode回去,如图:
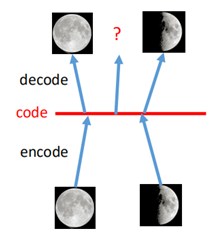
假设两边的状态一个是满月一个是新月,我们想要中间找个点,得到弦月的图片,然而当我们在中间的位置任意找一个code输入到decoder进去时,并不一定能保证得到的是弦月。
也就是说我们无法真正的构造出code,我们并不知道code来自于哪个分布,因此为解决这一问题,需要变分自编码器(VAE)。
2.2 VAE简介
VAE在进行图片还原时,要保证code与decoder的输出服从一定的分布,所以V的意思代表Variational。换句话说,就是在生成code的时候我们限制这些code服从一定的分布。
VAE的直观理解是,在生成的code上加上一些“噪音”,如图:
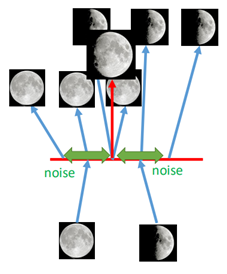
在生成的code上面加上噪音,例如满月的图片生成code之后,在其周围加上噪音之后,那么在噪音范围内所生成的图片都是满月的图片,同理新月也是。
当我们在满月和新月的code的中间取一点时(红色的箭头),此时相当于对新月和满月进行一个加权,从而生成了弦月。
上面就是VAE的直观的解释,那么通常这个code的“噪声”是如何加呢?又为什么这么加,下面就是VAE的网络结构和原理:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









