




编程总结
每每刷完一道题后,其思想和精妙之处没有地方记录,本篇博客用以记录刷题过程中的遇到的算法和技巧

链表基本操作
什么是链表,链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
链表的入口节点称为链表的头结点也就是head。
链表的类型
接下来说一下链表的几种类型:
#单链表
刚刚说的就是单链表。
typedef struct ListNodeT {
int val;
struct ListNodeT next;
} ListNode;
#双链表
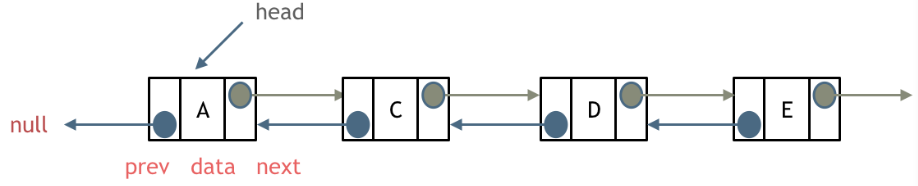
单链表中的指针域只能指向节点的下一个节点。
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
双链表 既可以向前查询也可以向后查询。
如图所示: 链表2
#循环链表
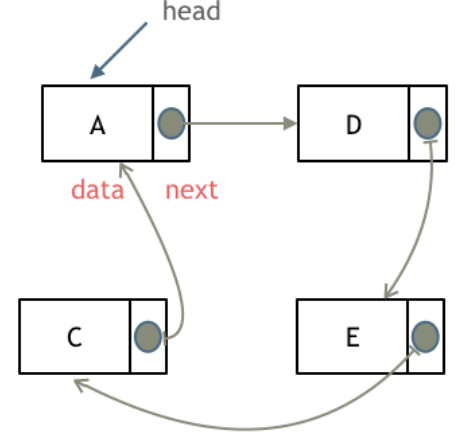
循环链表,顾名思义,就是链表首尾相连。
循环链表可以用来解决约瑟夫环问题。
链表基础操作
typedef struct ListNode_t {
int val;
struct ListNode_t *next;
} ListNode;
// 1.创建链表
ListNode *ListCreate() {
// 在链表的第一个结点之前会额外增设一个结点,头结点
ListNode *head = (ListNode *)malloc(sizeof(ListNode));
if (head == NULL) {
return NULL;
}
head->next = NULL;
head->val = 0; // 头结点的val用来指示链表长度
return head;
}
// 2.获取链表中第index个节点的索引值,如果索引无效,则返回-1
int ListIndexGet(ListNode *obj, int index)
{
int cnt = 0;
ListNode *tmp = obj->next; // 手法: 因为我们是以首元结点开始index为0,所以要obj->next以首元开始
// 而不是 ListNode *tmp = obj;
while (tmp) {
if (index == cnt) {
return tmp->val;
}
cnt++;
tmp = tmp->next;
}
return -1;
}
// 首元结点:链表中第一个元素所在的结点,它是头结点后边的第一个结点
/* 在链表的第一个元素之前添加值为val的节点。插入后,新节点将成为链表的第一个节点 */
/* obj -> node1 -> node2 */
/* obj -> newNode -> node1 -> node2 */
void ListAddAtHead(ListNode *obj, int val)
{
ListNode *newNode = (ListNode *)malloc(sizeof(ListNode));
if (newNode == NULL) {
return;
}
obj->val++; // 记录链表长度
newNode->val = val;
newNode->next = obj->next;
obj->next = newNode;
}
/* 将值为val的节点附加到链表的最后一个元素 */
/* head -> node1 -> node2 */
/* head -> node1 -> node2 -> tail */
void ListAddAtTail(ListNode *obj, int val)
{
ListNode *tail = (ListNode *)malloc(sizeof(ListNode));
ListNode *tmp = obj;
if (tail == NULL) {
return;
}
obj->val++; // 记录链表长度
tail->val = val;
tail->next = NULL;
while (tmp->next) {
tmp = tmp->next;
}
tmp->next = tail;
}
/* 在链表的索引节点之前添加一个值为val的节点。如果索引等于链表的长度,
则节点将附加到链表的末尾。如果索引大于长度,则不会插入节点 */
/* obj -> node1 -> node2 */
/* obj -> node1 -> newNode -> node2 */
void ListAddAtIndex(ListNode *obj, int index, int val)
{
int cnt = 0;
if (index == obj->val) {
ListAddAtTail(obj, val);
return;
} else if (index > obj->val) {
return;
}
ListNode *tmp = obj;
ListNode *newNode = (ListNode *)malloc(sizeof(ListNode));
newNode->val = val;
while (tmp) {
if (cnt == index) {
break;
}
tmp = tmp->next;
cnt++;
}
obj->val++; // 记录链表长度
newNode->next = tmp->next;
tmp->next = newNode;
return;
}
/* 如果索引有效,请删除链表中的第index个节点 */
/* head -> node1 -> node2 -> node3 */
/* head -> node1 -> node3 */
void ListDeleteAtIndex(ListNode *obj, int index)
{
ListNode *node = NULL;
ListNode *tmp = obj;
int cnt = 0;
while (tmp) {
if (cnt == index) {
break;
}
cnt++;
tmp = tmp->next;
}
if (tmp->next == NULL) {
// 删除的是最后的NULL,直接返回,手法
return;
}
obj->val--;
node = tmp->next;
tmp->next = node->next;
free(node);
}
/* head -> node1 -> node2 -> node3 */
void ListFree(ListNode *obj)
{
ListNode *tmp = obj;
ListNode *freeNode;
while (tmp) {
// 释放头结点->首元结点内的
freeNode = tmp;
tmp = tmp->next;
freeNode->next = NULL;
freeNode->val = 0;
free(freeNode);
}
}
203. 删除链表的节点_ED
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
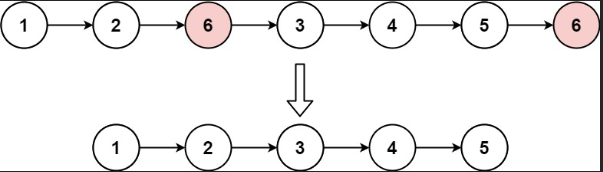
示例 1:
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1
输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7
输出:[]
提示:
列表中的节点数目在范围 [0, 104] 内
1 <= Node.val <= 50
0 <= val <= 50
用 temp 表示当前节点。如果 temp 的下一个节点不为空且下一个节点的节点值等于给定的 val,则需要删除下一个节点。
删除下一个节点可以通过以下做法实现:temp.next=temp.next.next
如果 temp 的下一个节点的节点值不等于给定的 val,则保留下一个节点,将 temp 移动到下一个节点即可。当 temp 的下一个节点为空时,链表遍历结束,此时所有节点值等于 val 的节点都被删除。
具体实现方面,由于链表的头节点 head 有可能需要被删除,因此创建哑节点 dummyHead,令 dummyHead.next=head,初始化 temp=dummyHead,然后遍历链表进行删除操作。最终返回 dummyHead.next 即为删除操作后的头节点
创建虚拟头结点,来处理
// dummyHead -> head
// temp -> (temp->next) -> (temp->next->next)
struct ListNode *removeElements(struct ListNode *head, int val)
{
struct ListNode *dummy_head = (struct ListNode *)malloc(sizeof(struct ListNode));
dummy_head->next = head;
struct ListNode *cur = dummy_head;
// dummy_head是哑节点,看的是 cur->next 节点
while ((cur->next != NULL)) {
if (cur->next->val == val) {
cur->next = cur->next->next;
} else {
cur = cur->next 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









