







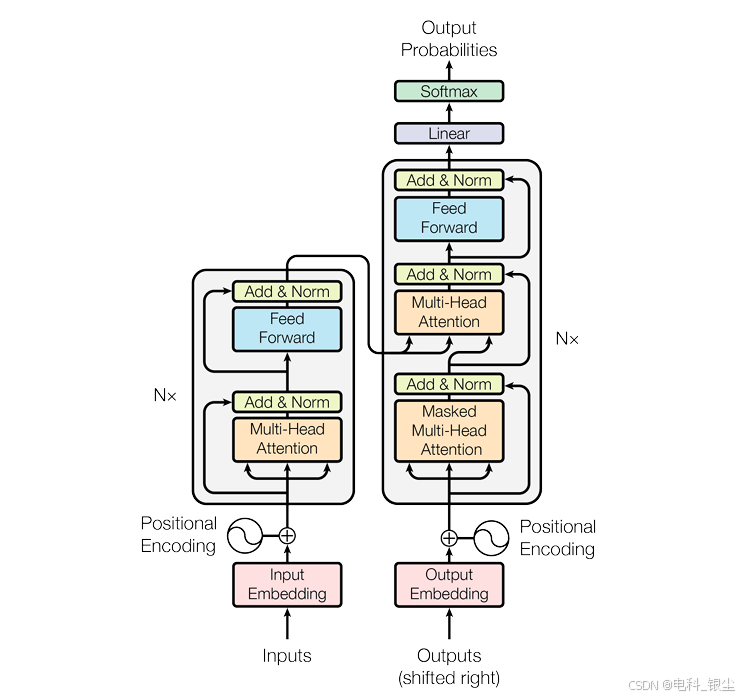
文章目录
文章目录
写在前面
根据博主文章,学习Transformer、Vit、SwinTransformer、SwinUnetr原理,原理博主文章已讲解较为详细,本文主要从代码角度学习各个模块的原理。
图解Vit 1:Vision Transformer——图像与Transformer基础 - 知乎
图解Vit 2:Vision Transformer——视觉问题中的注意力机制 - 知乎
图解Vit 3:Vision Transformer——ViT模型全流程拆解(Layer Normalization, Position Embedding) - 知乎
图解+代码 Swin Transformer 1: W-MSA和Patch Merging - 知乎
图解+代码 Swin Transformer 2: SW-MSA(Shifted Window Multi-head Self Attention) - 知乎
WindowAttention3D
class WindowAttention3D(nn.Module):
""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The temporal length, height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wd, Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1) * (2 * window_size[2] - 1), num_heads)) # 2*Wd-1 * 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_d = torch.arange(self.window_size[0])
coords_h = torch.arange(self.window_size[1])
coords_w = torch.arange(self.window_size[2])
coords = torch.stack(torch.meshgrid(coords_d, coords_h, coords_w)) # 3, Wd, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 3, Wd*Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 3, Wd*Wh*Ww, Wd*Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wd*Wh*Ww, Wd*Wh*Ww, 3
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 2] += self.window_size[2] - 1
relative_coords[:, :, 0] *= (2 * self.window_size[1] - 1) * (2 * self.window_size[2] - 1)
relative_coords[:, :, 1] *= (2 * self.window_size[2] - 1)
relative_position_index = relative_coords.sum(-1) # Wd*Wh*Ww, Wd*Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
""" Forward function.
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, N, N) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # B_, nH, N, C
q = q * self.scale
attn = q @ k.transpose(-2, -1)
relative_position_bias = self.relative_position_bias_table[self.relative_position_index[:N, :N].reshape(-1)].reshape(
N, N, -1) # Wd*Wh*Ww,Wd*Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wd*Wh*Ww, Wd*Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0) # B_, nH, N, N
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
相对位置编码理解
有关swin transformer相对位置编码的理解:_swin transformer 相对编码-优快云博客
coords = torch.stack(torch.meshgrid(coords_h, coords_w)) # 2, Wh, Ww
- torch.stack(…):torch.stack 将生成的两个二维数组堆叠成一个三维张量。堆叠的维度是新的维度(默认为第0维)。因此,coords 的形状为 (2, Wh, Ww),其中:
- 第一个维度(大小为2)分别表示行坐标和列坐标。
- 第二个维度(大小为Wh)表示网格的高度。
- 第三个维度(大小为Ww)表示网格的宽度。
- torch.flatten(coords, 1):torch.flatten 函数用于将张量的指定维度展平。这里的参数 1 表示从第1维开始展平(即保留第0维)。因此,coords 的形状 (2, Wh, Ww) 会被展平为 (2, Wh * Ww)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
-
- coords_flatten[:, :, None] 和 coords_flatten[:, None, :]
- coords_flatten是一个二维张量,形状为 (2, N),其中:
- 2 表示两个坐标维度(例如,行和列)。
- N 表示网格中的点数(网格的总像素或单元数)。
- coords_flatten[:, :, None]:在第三个维度上增加一个新的维度,形状变为 (2, N, 1)。
- coords_flatten[:, None, :]:在第二个维度上增加一个新的维度,形状变为 (2, 1, N)。
-
- 广播机制
- 当执行 coords_flatten[:, :, None] - coords_flatten[:, None, :] 时,广播机制会自动扩展两个张量的维度以匹配对方的形状:
- coords_flatten[:, :, None] 的形状为 (2, N, 1)。
- coords_flatten[:, None, :] 的形状为 (2, 1, N)。
通过广播,两个张量的形状会被扩展为 (2, N, N),然后逐元素相减。
- 结果解释
- 最终得到的 relative_coords 是一个三维张量,形状为 (2, N, N),其中:
- 第一个维度(2):表示两个坐标的差异(例如,行坐标差和列坐标差)。
- 第二个和第三个维度(N, N):表示网格中每个点与其他所有点的相对位置。
例如,假设网格中有 4 个点,relative_coords 的形状为 (2, 4, 4)。每个点 (i, j) 的相对坐标差表示点 i 和点 j 之间的位置差异。
self.window_size
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 2] += self.window_size[2] - 1
- 假设窗口大小为 (Wd, Wh, Ww),分别表示窗口在深度、高度和宽度方向的大小。
- 例如,Wd = 5,则窗口在深度方向上的范围为 0 到 4。
- relative_coords[:, :, 0] += self.window_size[0] - 1:
- 对于深度维度(0),将相对坐标差加上 Wd - 1,以确保最小的相对坐标差值为 0。
- 假设 Wd = 5,则 self.window_size[0] - 1 = 4。
- 如果相对坐标差为 -2,加上 4 后变为 2。
- 作用:
- 确保每个相对坐标差在平移后为非负数,并且范围为 [0, 2 * Wd - 2]。
- 例如,原始相对坐标差的范围为 [-4, 4](假设窗口大小为 5),平移后变为 [0, 8]。
relative_coords
relative_coords[:, :, 0] *= (2 * self.window_size[1] - 1) * (2 * self.window_size[2] - 1)
relative_coords[:, :, 1] *= (2 * self.window_size[2] - 1)
relative_position_index = relative_coords.sum(-1) # Wd*Wh*Ww, Wd*Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
这两行代码对三维相对坐标差 relative_coords 的前两个维度应用了缩放因子,以便将三维相对坐标转换为一维索引,用于查询相对位置偏置表(relative_position_bias_table)。
- 内容分解
假设相对坐标 relative_coords 的形状为 (N, N, 3),其中 N 是窗口中的元素数量,3 表示三维坐标(深度、高度、宽度)。
第一行代码:
relative_coords[:, :, 0] *= (2 * self.window_size[1] - 1) * (2 * self.window_size[2] - 1)
-
relative_coords[:, :, 0]:表示三维相对坐标的第一个维度(深度方向)。
-
2 * self.window_size[1] - 1:计算窗口在高度方向的扩展范围。如果窗口的高度为 Wh,那么扩展后的高度范围为 2*Wh-1。
-
2 * self.window_size[2] - 1:计算窗口在宽度方向的扩展范围。如果窗口的宽度为 Ww,那么扩展后的宽度范围为 2*Ww-1。
-
*=:将深度方向的坐标值乘以高度和宽度的扩展范围之积。这相当于为深度方向的坐标值赋予一个较大的权重,使其在后续的一维索引计算中占据更高的基数。
第二行代码:
relative_coords[:, :, 1] *= (2 * self.window_size[2] - 1) -
relative_coords[:, :, 1]:表示三维相对坐标的第二个维度(高度方向)。
-
2 * self.window_size[2] - 1:计算窗口在宽度方向的扩展范围。
-
*=:将高度方向的坐标值乘以宽度方向的扩展范围。这相当于为高度方向的坐标值赋予一个中等权重,使其在后续的一维索引计算中占据中等的基数。
-
目的
通过这两行代码,我们将三维的相对坐标 (dx, dy, dz) 转换为一个唯一的一维索引,以便能够从相对位置偏置表(relative_position_bias_table)中查询对应的偏置值。这类似于将三维坐标 (x, y, z) 转换为一维索引 z + y * Ww + x * Wh * Ww,其中 Ww 和 Wh 是窗口的宽度和高度。 -
一维索引计算示例
假设窗口大小为 Wd = 3、Wh = 2、Ww = 2,则:
- 各维度的扩展范围为:
- 深度方向:2*3-1 = 5
- 高度方向:2*2-1 = 3
- 宽度方向:2*2-1 = 3
对于一个相对坐标 (2, 1, 1),按以下方式计算一维索引:
1.深度坐标 dx = 2:
- 权重为:(2*2-1)*(2*2-1) = 3 * 3 = 9
- 乘积:2 * 9 = 18
2.高度坐标 dy = 1:
- 权重为:2*2-1 = 3
- 乘积:1 * 3 = 3
3.宽度坐标 dz = 1:
- 权重为:1(无需缩放)
- 乘积:1 * 1 = 1
总的一维索引为:18 + 3 + 1 = 22
注意力分数计算
- 计算注意力分数
q = q * self.scale
attn = q @ k.transpose(-2, -1)
- q * self.scale:
-
将查询矩阵 q 与缩放因子 self.scale 相乘。self.scale 通常设置为 head_dim ** -0.5,其中 head_dim 是每个注意力头的维度。这个缩放因子是为了稳定注意力分数的数值分布,避免梯度消失或爆炸。
-
k.transpose(-2, -1):
-
对键矩阵 k 的最后两个维度进行转置。假设 k 的形状为 (B_, N, C),转置后形状变为 (B_, C, N)。
-
q @ k.transpose(-2, -1):
-
计算查询矩阵 q 和转置后的键矩阵 k 的矩阵乘积,得到原始的注意力分数矩阵 attn。形状为 (B_, N, N),表示每个查询与每个键之间的相似度。
- 添加相对位置偏置
relative_position_bias = self.relative_position_bias_table[self.relative_position_index[:N, :N].reshape(-1)].reshape(N, N, -1)
-
self.relative_position_bias_table:
-
一个存储相对位置偏置的张量,形状为 (2Wd-1)(2Wh-1)(2*Ww-1), num_heads),其中 Wd、Wh、Ww 是窗口在深度、高度和宽度方向的大小。
-
self.relative_position_index[:N, :N]:
-
一个二维索引矩阵,形状为 (N, N),其中 N 是窗口中的元素数量。它用于从 self.relative_position_bias_table 中提取对应的偏置值。
-
.reshape(-1):
-
将索引矩阵展平为一维数组,以便从 self.relative_position_bias_table 中提取偏置值。
-
.reshape(N, N, -1):
-
将提取的偏置值重新 reshape 为 (N, N, num_heads),其中 num_heads 是注意力头的数量。
- 调整维度顺序
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
-
permute(2, 0, 1):
-
调整偏置张量的维度顺序,使其变为 (num_heads, N, N),以便与注意力分数矩阵的形状匹配。
-
contiguous():
-
确保张量在内存中是连续的,便于后续操作。
- 合并注意力分数和相对位置偏置
attn = attn + relative_position_bias.unsqueeze(0)
-
relative_position_bias.unsqueeze(0):
-
在第0维添加一个新的维度,将偏置张量的形状变为 (1, num_heads, N, N),以匹配注意力分数矩阵 attn 的形状 (B_, num_heads, N, N)。
-
attn + relative_position_bias.unsqueeze(0):
-
将相对位置偏置加到注意力分数矩阵上,得到最终的注意力矩阵。这一步是为了引入位置信息,使注意力机制能够更好地捕捉不同位置之间的关系。
trunc_normal_(self.relative_position_bias_table, std=.02)
在 PyTorch 中,trunc_normal_ 是一个用于参数初始化的函数,它生成截断正态分布(truncated normal distribution)的随机数。以下是对代码的解释:
trunc_normal_(self.relative_position_bias_table, std=.02)
- self.relative_position_bias_table:
- std=.02:std 是截断正态分布的标准差。trunc_normal_ 函数会生成一个在均值附近截断的正态分布。默认情况下,截断范围是均值的两个标准差之外的值被重新采样。
assert
assert 0 <= self.shift_size[0] < self.window_size[0], "shift_size must in 0-window_size"
assert 0 <= self.shift_size[1] < self.window_size[1], "shift_size must in 0-window_size"
assert 0 <= self.shift_size[2] < self.window_size[2], "shift_size must in 0-window_size"
assert 是一个 Python 关键字,用于对表达式进行断言。如果表达式的值为 False,程序会抛出一个 AssertionError,并显示错误信息。
cyclic shift
# cyclic shift
if any(i > 0 for i in shift_size):
shifted_x = torch.roll(x, shifts=(-shift_size[0], -shift_size[1], -shift_size[2]), dims=(1, 2, 3))
attn_mask = mask_matrix
else:
shifted_x = x
attn_mask = None
这段代码实现了循环平移(cyclic shift)操作,通常用于视觉网络(如 Swin Transformer)中增强模型的空间感受能力。以下是对代码的详细解释:
- 循环平移条件判断
if any(i > 0 for i in shift_size):
- shift_size:一个包含三个整数的数组或元组,表示在深度、高度和宽度方向上的平移尺寸。
- 条件:如果 shift_size 的任何维度大于 0,则执行循环平移操作。
- 循环平移操作
shifted_x = torch.roll(x, shifts=(-shift_size[0], -shift_size[1], -shift_size[2]), dims=(1, 2, 3))
- torch.roll:将张量 x 在指定维度上进行循环平移。
- shifts:指定每个维度的平移量。例如,(-shift_size[0], -shift_size[1], -shift_size[2]) 表示在深度、高度和宽度方向上分别平移 -shift_size[0]、-shift_size[1] 和 -shift_size[2] 个单位。
- dims:指定平移的维度。这里 dims=(1, 2, 3) 表示在第 1、2、3 维度上进行平移。
- 负数是往右移,正数是往左移。
- 注意力掩码
attn_mask = mask_matrix
- 如果执行了循环平移操作,则设置注意力掩码 attn_mask 为 mask_matrix。这个掩码用于在后续的注意力计算中屏蔽掉无效的位置。
- 不进行循环平移的情况
else:
shifted_x = x
attn_mask = None
- 如果 shift_size 的所有维度都为 0,则直接使用原始输入张量 x,并且不使用注意力掩码(attn_mask = None)。
关键点总结 - 循环平移的作用:通过平移操作,打破局部特征的平移不变性,增强模型的空间感受能力。
- torch.roll:用于实现张量的循环平移,shifts 参数控制平移量,dims 参数控制平移的维度。
- attn_mask:用于在注意力计算中屏蔽无效区域,确保模型只关注有效的位置。
论文下载
Attention Is All You Need
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images
SwinUNETR-V2: Stronger Swin Transformers with Stagewise Convolutions for 3D Medical Image Segmentation


















 2148
2148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











