







【机器学习21】-多标签分类(Multi-label Classification)
以下是基于3张图片核心内容的多标签分类(Multi-label Classification)系统解析与实现指南:
1. 核心概念解析(图1-图3)
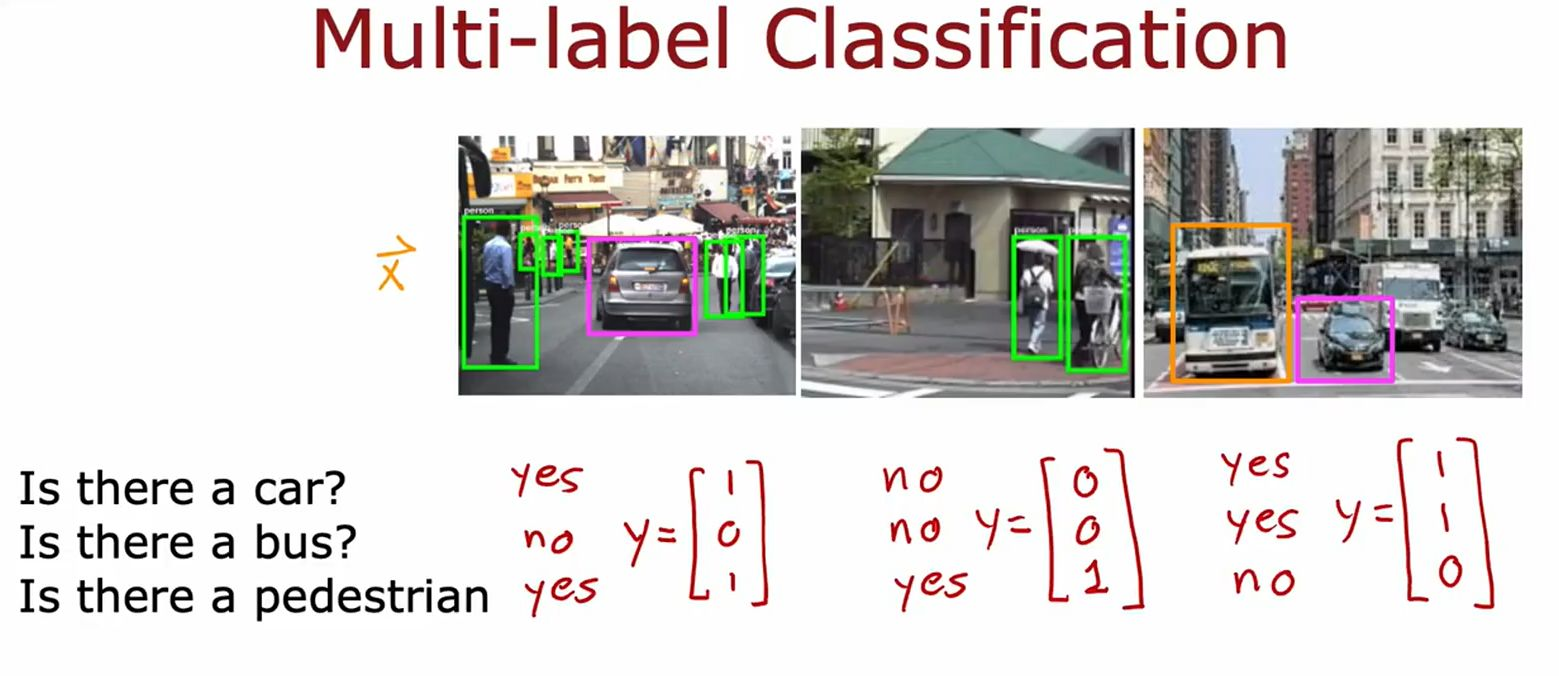
什么是多标签分类?
• 定义:单个输入同时属于多个类别(如一张图片包含"车"+“行人”)。
• 对比传统分类:
| 多类分类(MNIST) | 多标签分类(图2场景) |
|---|---|
| 仅一个正确标签(数字7) | 多个标签可同时为真(车+行人) |
| 使用Softmax输出概率和 | 每个输出独立使用Sigmoid |
典型应用(图2)
• 自动驾驶:检测图像中是否存在"车"(y₁)、“公交车”(y₂)、“行人”(y₃)。
• 标签格式:y = [1, 0, 1](有车、无公交、有行人)。
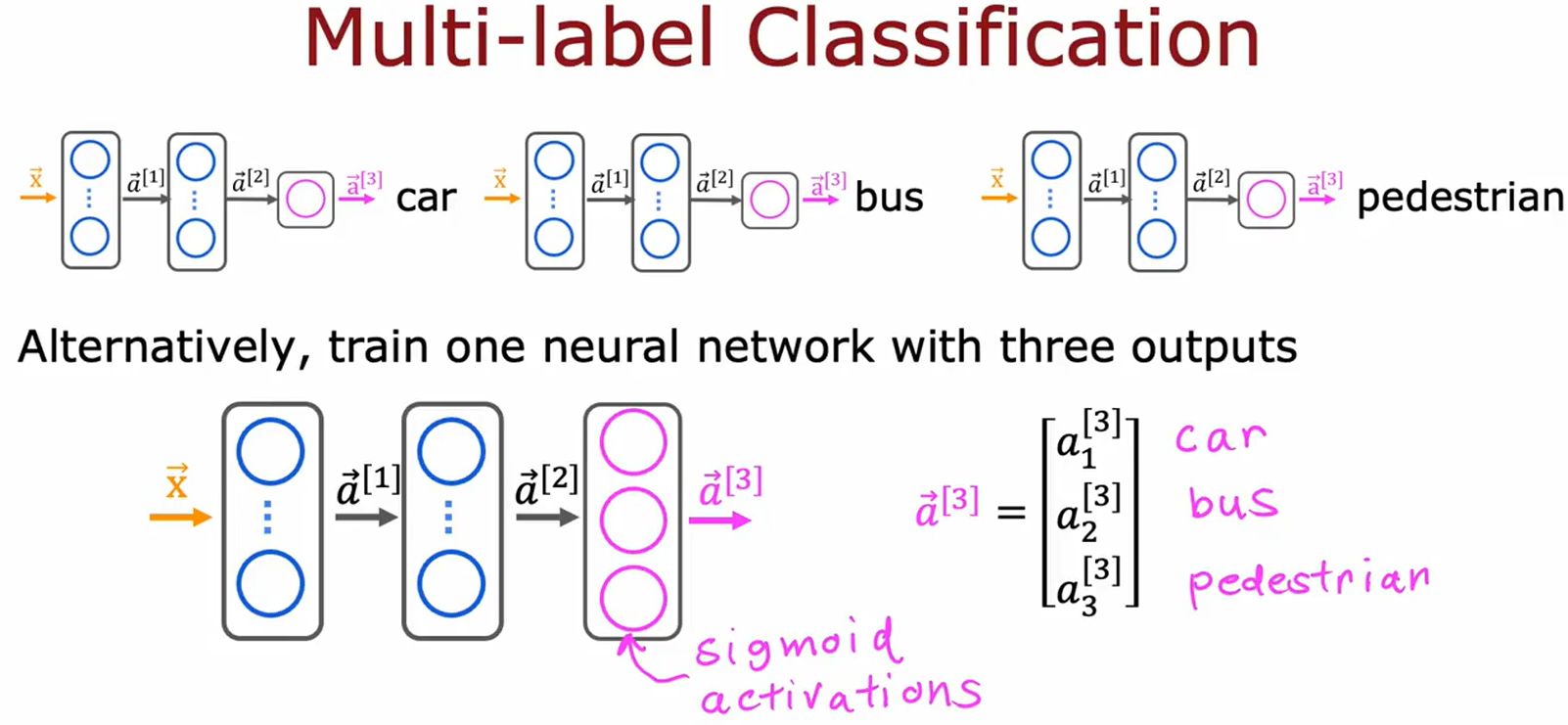
2. 两种实现方案(图3)
方案A:独立模型(低效)
# 为每个标签训练单独的二分类模型(不推荐)
model_car = Sequential([Dense(1, activation='sigmoid')]) # 检测车
model_bus = Sequential([Dense(1, activation='sigmoid')]) # 检测公交
# ...需重复训练和推理
方案B:单模型多输出(高效,图3下方)
model = Sequential([
Dense(64, activation='relu', input_shape=(256,)), # 共享特征提取层
Dense(3, activation='sigmoid') # 3个独立输出
])
• 输出层设计:
• 单元数 = 标签数量(如3类)。
• 必须用Sigmoid:每个输出独立计算概率(0-1之间)。
3. 关键实现细节
损失函数选择
• Binary Crossentropy:每个输出节点独立计算损失,总损失为平均值。
model.compile(
loss='binary_crossentropy', # 自动适配多标签
optimizer='adam',
metrics=['accuracy']
)
标签与预测处理
• 标签格式:Numpy数组,形状为(样本数, 标签数),例如:
y_train = np.array([
[1, 0, 1], # 样本1:有车、无公交、有行人
[0, 1, 0] # 样本2:无车、有公交、无行人
])
• 预测阈值:对Sigmoid输出设定阈值(如0.5)转为0/1:
predictions = (model.predict(X_test) > 0.5).astype(int)
4. 完整代码示例(自动驾驶场景检测)
import tensorflow as tf
from tensorflow.keras import Sequential, Dense
import numpy as np
# 1. 模拟数据(实际需替换为真实数据)
X_train = np.random.rand(100, 256) # 100张图片,每张256维特征
y_train = np.random.randint(0, 2, size=(100, 3)) # 3个标签的二进制矩阵
# 2. 模型构建
model = Sequential([
Dense(64, activation='relu', input_shape=(256,)),
Dense(32, activation='relu'),
Dense(3, activation='sigmoid') # 3个标签输出
])
# 3. 编译与训练
model.compile(optimizer='adam', loss='binary_crossentropy')
model.fit(X_train, y_train, epochs=10, batch_size=32)
# 4. 预测示例
X_test = np.random.rand(5, 256)
probabilities = model.predict(X_test) # 输出概率(0-1)
binary_preds = (probabilities > 0.5).astype(int) # 转为0/1
print("预测结果(车/公交/行人):\n", binary_preds)
5. 常见问题与调优策略
问题1:模型对所有标签预测为0或1
• 原因:样本不平衡(如"行人"标签极少)。
• 解决:
• 对每个标签使用类别权重:
python weights = {0: 1, 1: 10} # 正样本权重提高 model.fit(X_train, y_train, class_weight=weights)
问题2:训练损失震荡
• 调优:
• 调整学习率(如Adam(learning_rate=0.001))。
• 增加隐藏层单元数或层数(提升特征提取能力)。
总结
• 核心要点:
- 多标签分类需独立处理每个标签(Sigmoid输出)。
- 单模型多输出比独立模型更高效(图3对比)。
- 评估指标需按标签分别计算(如精确率/召回率)。
• 延伸学习:
• 目标检测(如YOLO)是多标签分类的进阶应用。
• 尝试使用预训练模型(如ResNet)提取特征。
如需进一步探讨具体应用场景或调试代码,请提供更多细节!


















 3077
3077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









