







【机器学习-15】 - 神经网络
以下是关于神经网络的详细解析,涵盖核心概念、工作原理、应用场景及代码示例:
1. 神经网络的定义
神经网络(Neural Network)是一种模仿生物神经元工作方式的机器学习模型,由多层互联的“神经元”(数学函数)组成,能够通过数据学习复杂的非线性关系。
神经网络逐渐兴起于二十世纪八九十年代,应用得非常广泛。但由于各种原因,在90年代的后期应用减少了。但是最近,神经网络又东山再起了。其中一个原因是:神经网络是计算量有些偏大的算法。然而大概由于近些年计算机的运行速度变快,才足以真正运行起大规模的神经网络。正是由于这个原因和其他一些我们后面会讨论到的技术因素,如今的神经网络对于许多应用来说是最先进的技术。当你想模拟大脑时,是指想制造出与人类大脑作用效果相同的机器。大脑可以学会去以看而不是听的方式处理图像,学会处理我们的触觉。
2. 核心组成
(1)神经元(Neuron)
• 功能:接收输入信号,加权求和后通过激活函数输出。
• 数学表示:
output = activation(w1*x1 + w2*x2 + ... + wn*xn + bias)
(2)网络结构
| 层类型 | 作用 |
|---|---|
| 输入层 | 接收原始数据(如图像像素、数值特征) |
| 隐藏层 | 通过权重和激活函数提取特征(深度网络含多个隐藏层) |
| 输出层 | 生成最终预测(如分类概率、回归值) |
(3)激活函数(关键非线性工具)
| 函数 | 公式 | 用途 |
|---|---|---|
| Sigmoid | 1/(1 + e^(-x)) | 二分类输出(0~1概率) |
| ReLU | max(0, x) | 解决梯度消失,常用隐藏层 |
| Softmax | e^x / sum(e^x) | 多分类概率归一化 |
3. 工作原理(前向传播 + 反向传播)
(1)前向传播
# 示例:2层神经网络计算
import numpy as np
def relu(x):
return np.maximum(0, x)
# 输入数据
X = np.array([[0.5, -1.2]]) # 1个样本,2个特征
# 参数(实际需训练)
W1 = np.random.randn(2, 4) # 第一层权重(2输入→4神经元)
b1 = np.zeros(4)
W2 = np.random.randn(4, 1) # 第二层权重(4→1输出)
b2 = np.zeros(1)
# 计算过程
z1 = X.dot(W1) + b1 # 线性变换
a1 = relu(z1) # 激活函数
z2 = a1.dot(W2) + b2
y_pred = 1 / (1 + np.exp(-z2)) # Sigmoid输出概率
(2)反向传播
• 目标:通过梯度下降优化权重(W)和偏置(b)。
• 关键步骤:
- 计算损失函数(如交叉熵损失)。
- 利用链式法则求各层梯度。
- 更新参数:
W = W - learning_rate * dW
4. 神经网络的类型
| 类型 | 结构特点 | 典型应用 |
|---|---|---|
| 前馈神经网络(FFN) | 单向传播,无循环 | 图像分类、房价预测 |
| 卷积神经网络(CNN) | 含卷积层、池化层 | 计算机视觉 |
| 循环神经网络(RNN) | 具有时间循环结构 | 自然语言处理、时间序列 |
| Transformer | 自注意力机制 | 大语言模型(如GPT) |
5. 实际应用示例
(1)图像分类(CNN)
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([
Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)),
MaxPooling2D((2,2)),
Flatten(),
Dense(10, activation='softmax') # 10分类输出
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
(2)文本情感分析(RNN)
from tensorflow.keras.layers import LSTM, Embedding
model = Sequential([
Embedding(10000, 32), # 词嵌入层
LSTM(64), # 循环层
Dense(1, activation='sigmoid') # 二分类
])
6. 神经网络的优缺点
| 优点 | 挑战 |
|---|---|
| 自动学习特征(无需手动设计) | 需要大量数据和计算资源 |
| 处理高维数据(如图像、文本) | 模型解释性较差(黑盒问题) |
| 可解决非线性问题 | 超参数调优复杂 |
图片1:需求预测的数学模型(单神经元)
• 主题:使用Sigmoid函数预测商品是否为畅销品。
• 关键内容:
• 输入:商品价格(x轴),输出:是否为畅销品(yes/no,y轴)。
• 公式:
a
=
1
1
+
e
−
(
w
x
+
b
)
a = \frac{1}{1 + e^{-(wx + b)}}
a=1+e−(wx+b)1,表示价格与畅销概率的关系。
• 图示:T恤图标代表商品,神经元结构展示输入(价格)到输出(概率)的转换。
• 用途:解释单变量逻辑回归模型的基本原理。

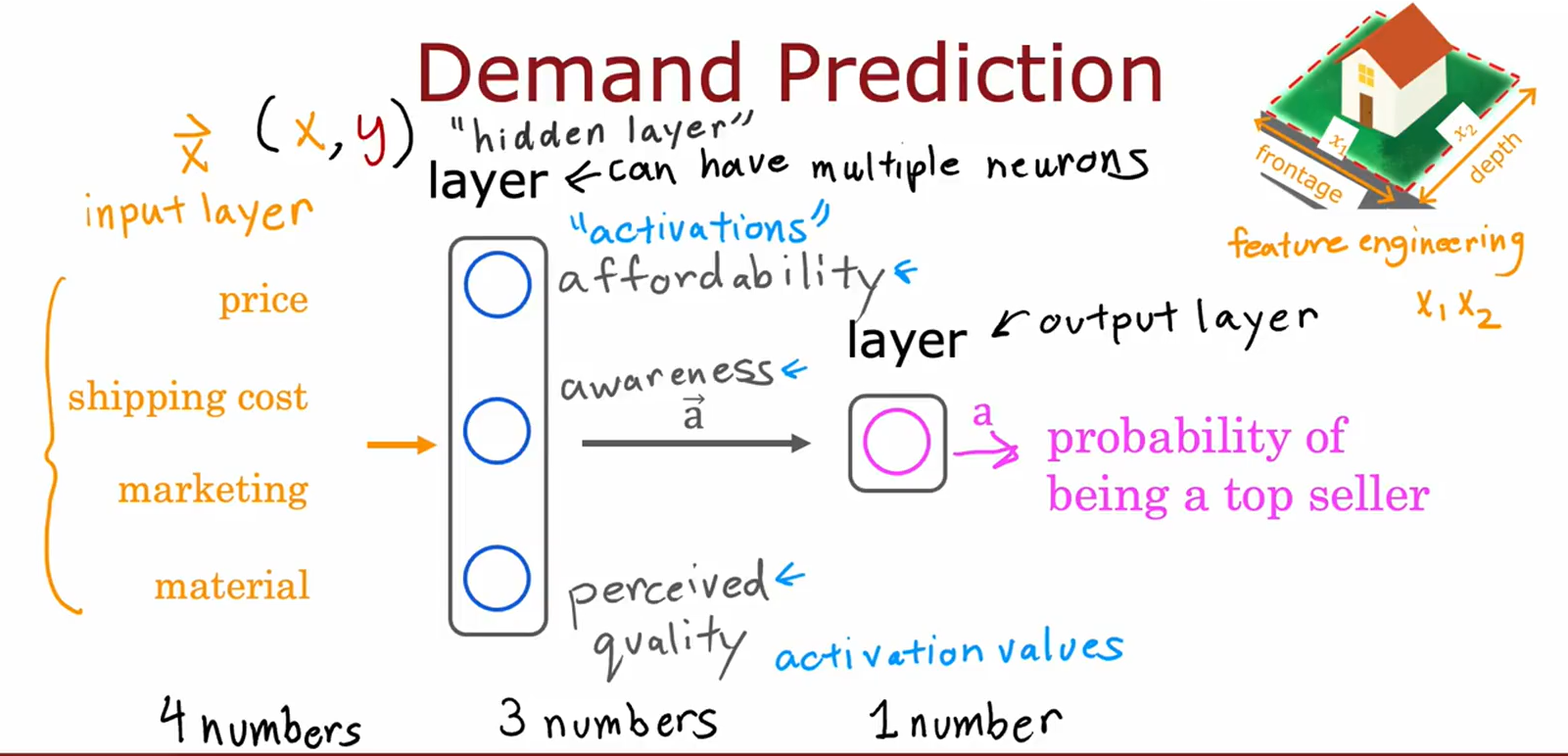
图片2:需求预测的神经网络(多输入)
• 主题:多因素需求预测的神经网络结构。
• 关键内容:
• 输入层:价格、运输成本、营销、材料等4个特征。
• 隐藏层:处理特征(如可负担性、感知质量),输出层生成畅销概率。
• 强调特征工程(如“房屋正面/深度”的衍生特征)。
• 用途:展示多变量神经网络在需求预测中的应用。
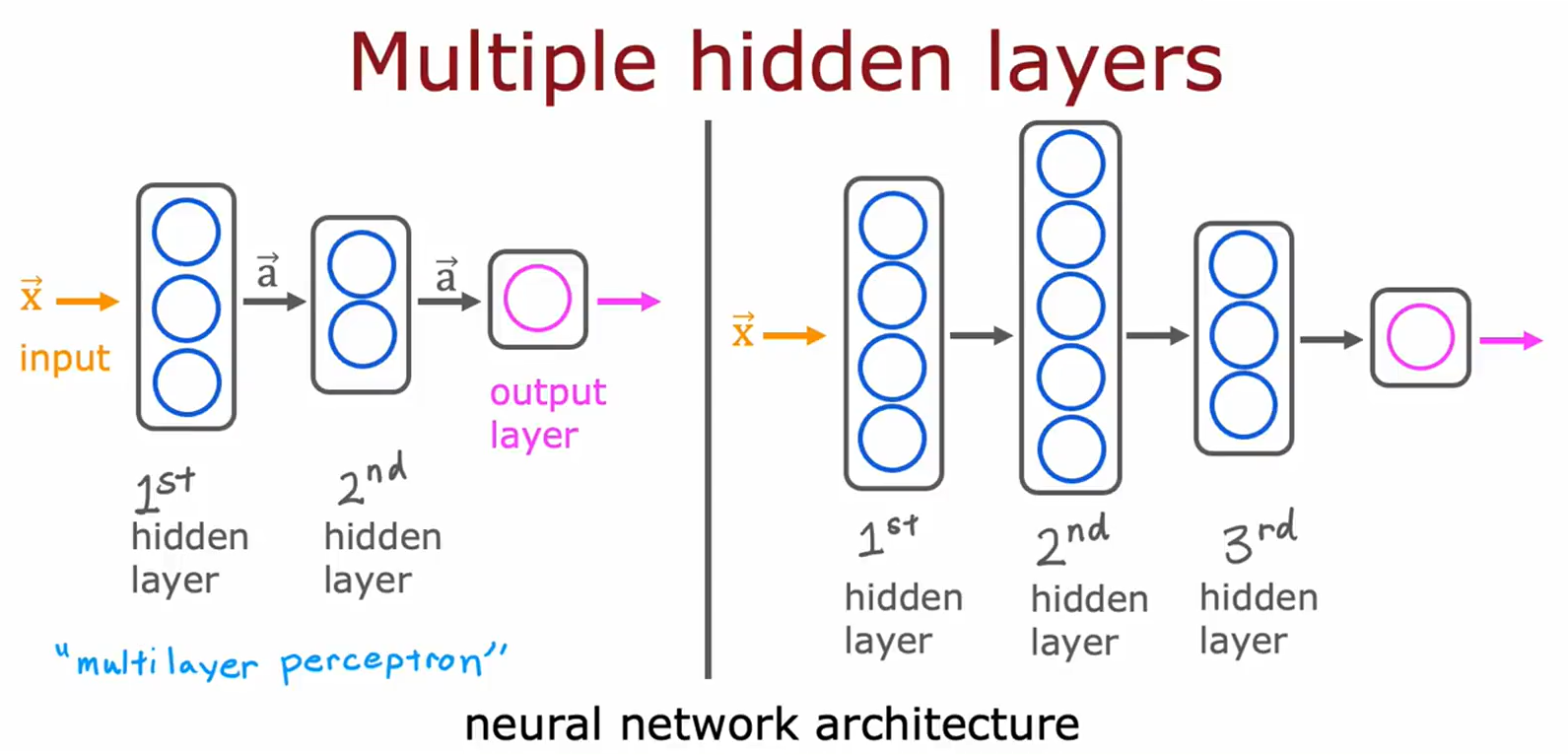
图片3:多层神经网络架构
• 主题:多层感知器(MLP)的层级结构。
• 关键内容:
• 输入层 → 多个隐藏层(1st/2nd/3rd)→ 输出层。
• 右侧展示更复杂的深层网络架构。
• 用途:对比浅层与深层神经网络的结构差异。
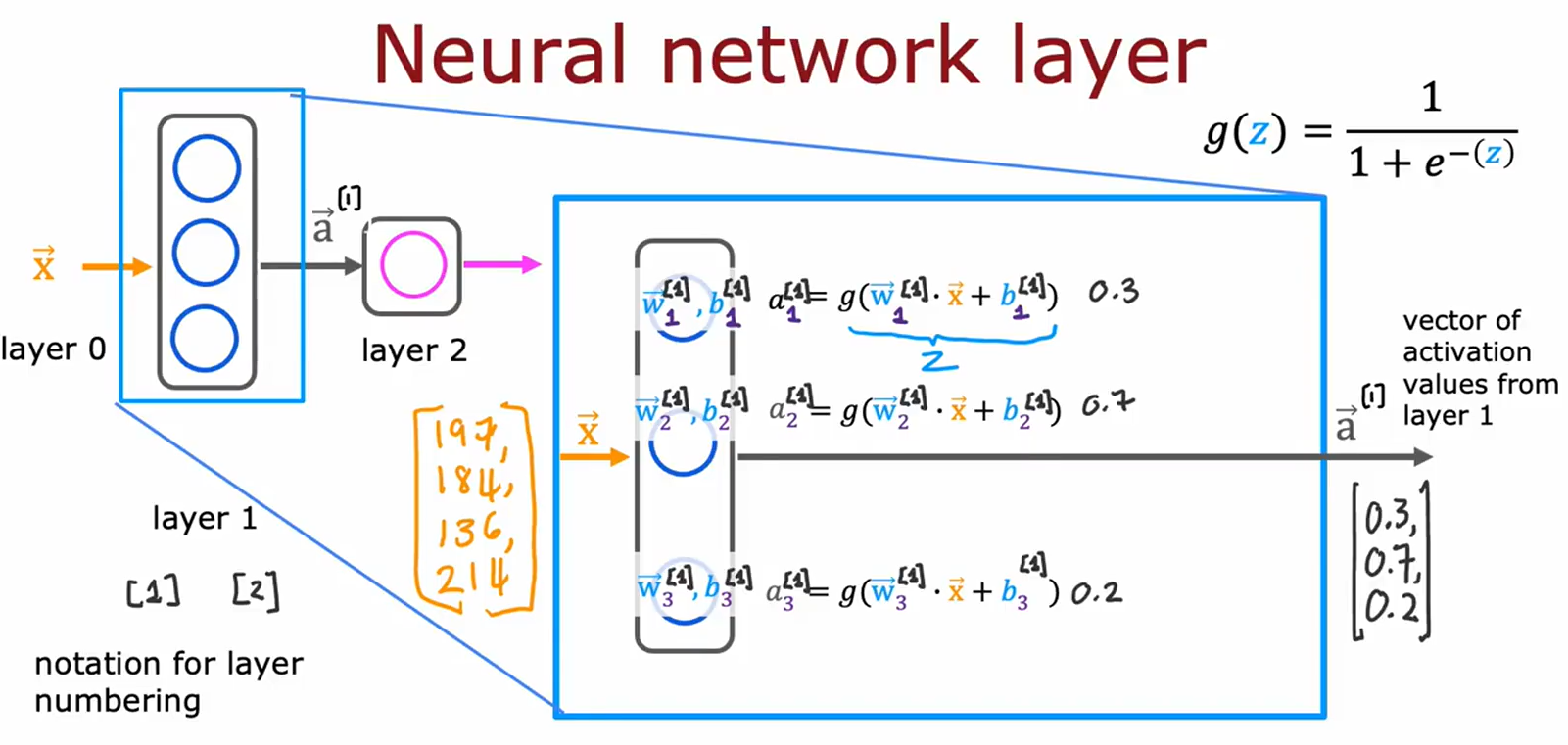
图片4:神经网络层的计算细节
• 主题:单层神经网络的数学计算过程。
• 关键内容:
• 公式:激活函数
g
(
z
)
=
1
1
+
e
−
z
g(z) = \frac{1}{1 + e^{-z}}
g(z)=1+e−z1。
• 逐层计算:权重(W)、偏置(b)、激活值(a)的传递。
• 标注:层编号
l
a
y
e
r
0
/
1
/
2
layer 0/1/2
layer0/1/2和向量表示。
• 用途:详解神经网络前向传播的数学实现。
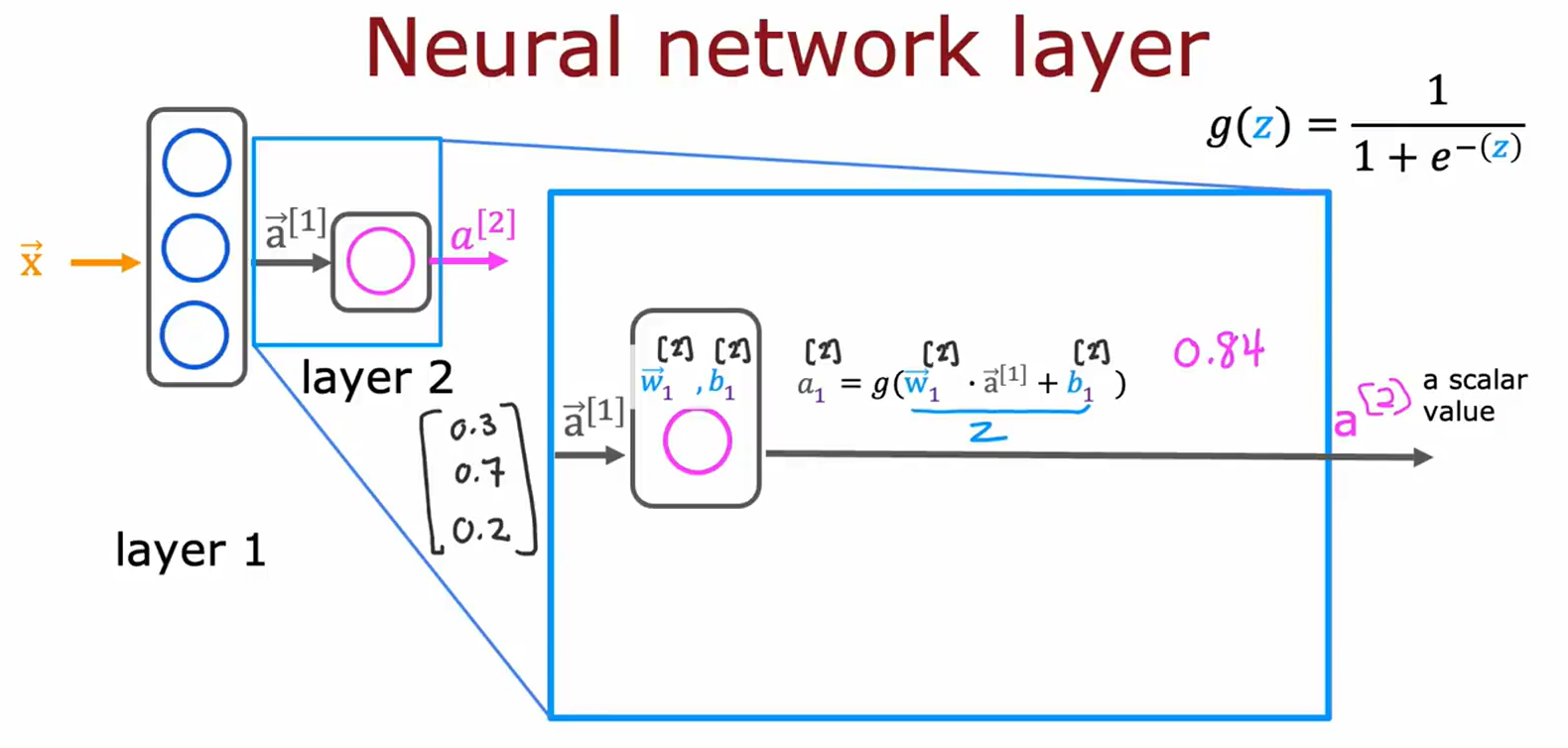
图片5:神经网络层的数值示例
• 主题:具体数值演示单层计算。
• 关键内容:
• 输入通过权重和偏置计算,输出激活值(如a[1]=0.84)。
• 使用Sigmoid函数
g
(
z
)
g(z)
g(z) 处理加权和。
• 用途:通过实例说明神经元如何生成输出。
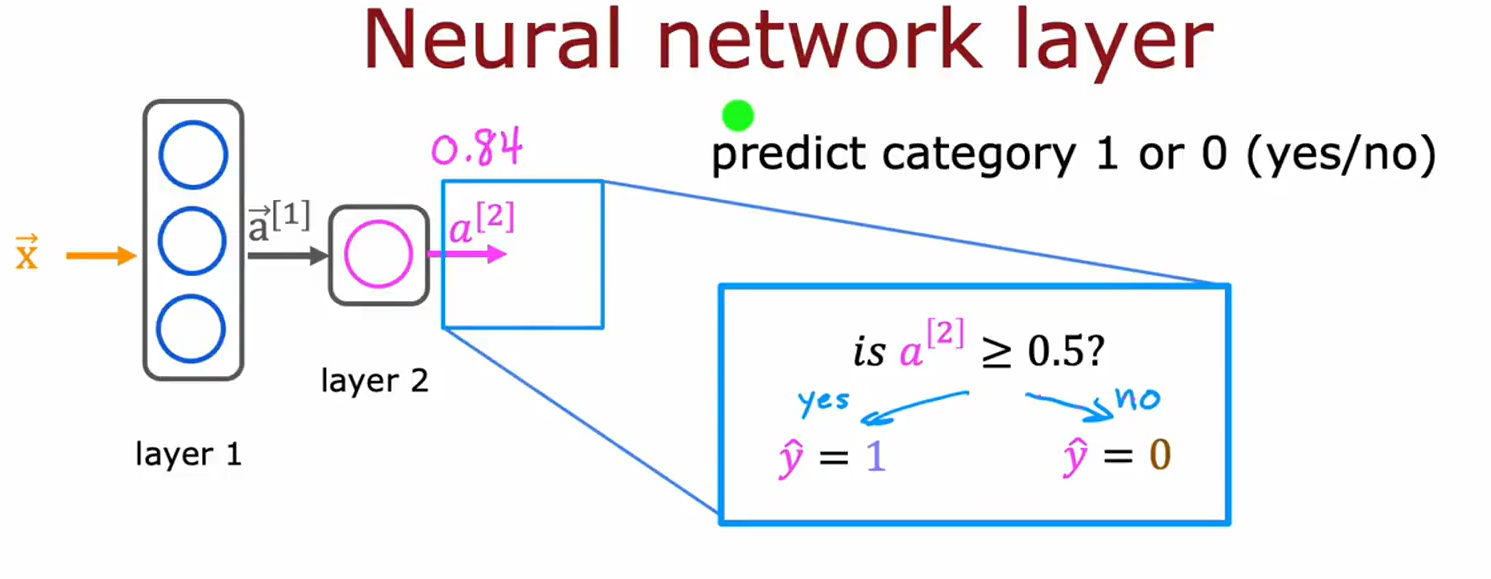
图片6:二分类预测逻辑
• 主题:基于阈值的分类决策。
• 关键内容:
• 输出层值
如
a
[
2
]
=
0.84
如a[2]=0.84
如a[2]=0.84与阈值0.5比较。
• 预测规则:≥0.5为“是”(1),否则为“否”(0)。
• 用途:解释神经网络如何完成二分类任务。
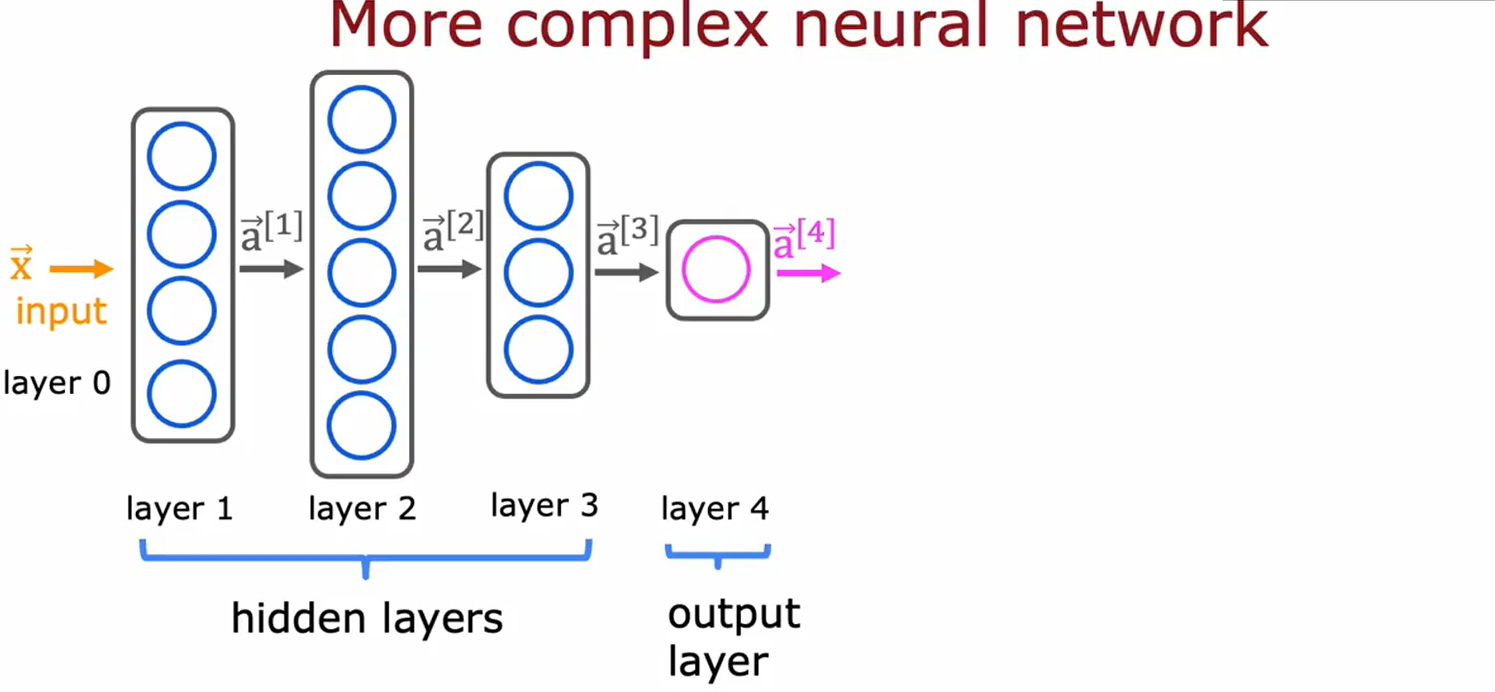
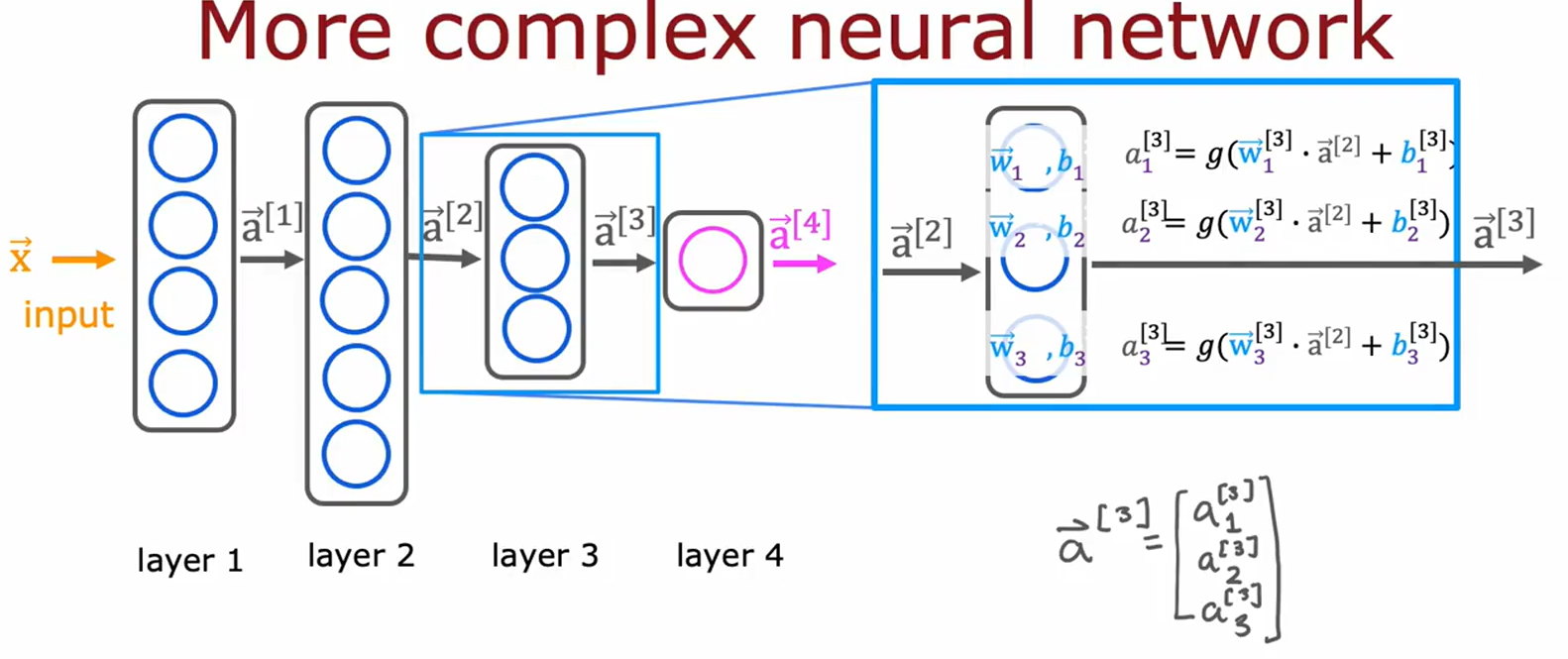
图片7-8:复杂神经网络结构
• 主题:深层网络的层级与计算。
• 关键内容:
• 结构:输入层(layer 0)→ 多个隐藏层(layer 1/2/3)→ 输出层(layer 4)。
• 公式:
a
[
l
]
=
g
(
W
[
l
]
⋅
a
[
l
−
1
]
+
b
[
l
]
)
a^{[l]} = g(W^{[l]} \cdot a^{[l-1]} + b^{[l]})
a[l]=g(W[l]⋅a[l−1]+b[l])。
• 用途:展示深层网络的信息传递与参数计算。
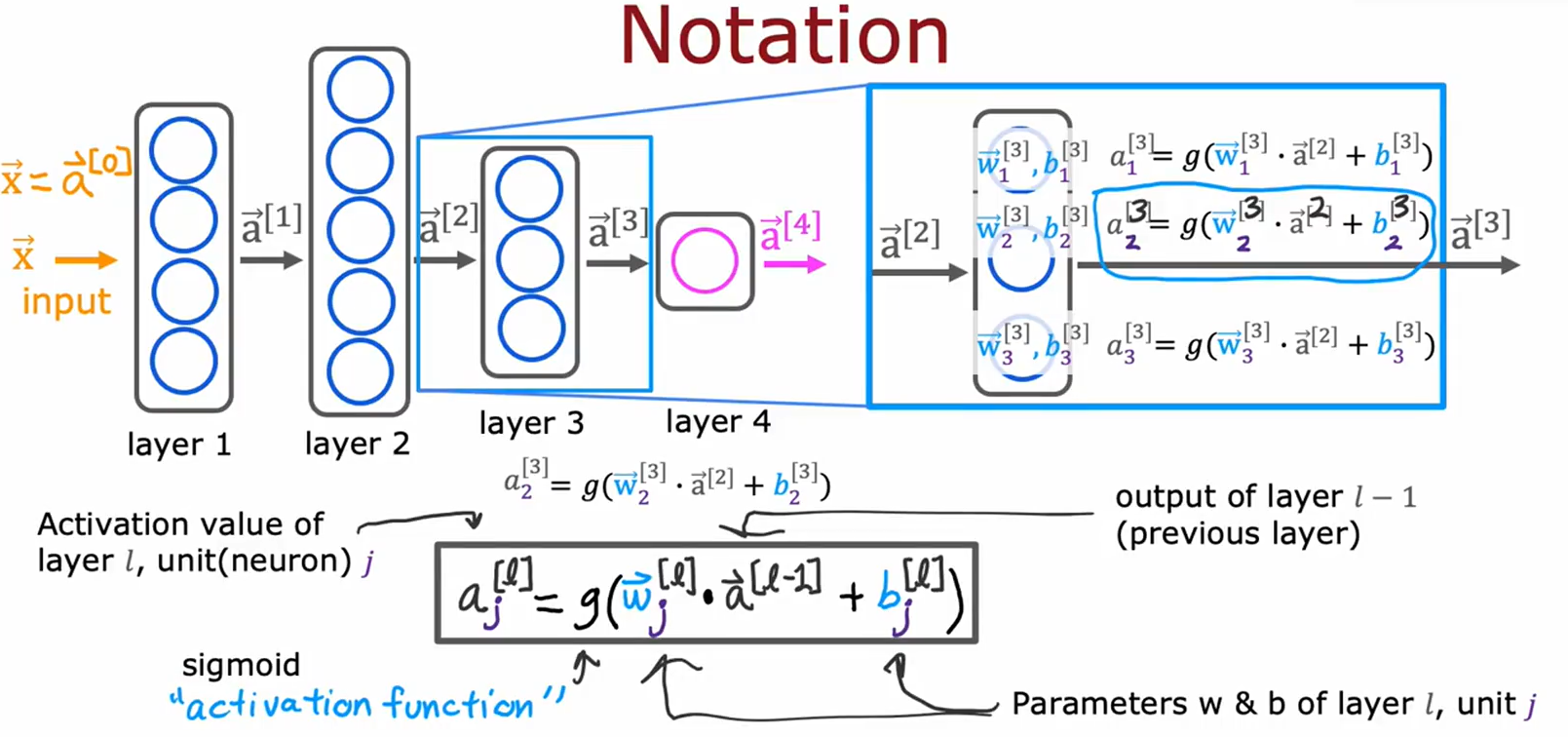
图片9:符号表示与参数定义
• 主题:神经网络中各层参数的数学表示。
• 关键内容:
• 定义:权重 $w_j^{[l]} )、偏置 ( b_j^{[l]}4、激活值
a
j
[
l
]
a_j^{[l]}
aj[l]。
• 强调激活函数(如Sigmoid)的作用。
• 用途:规范神经网络公式的符号系统。
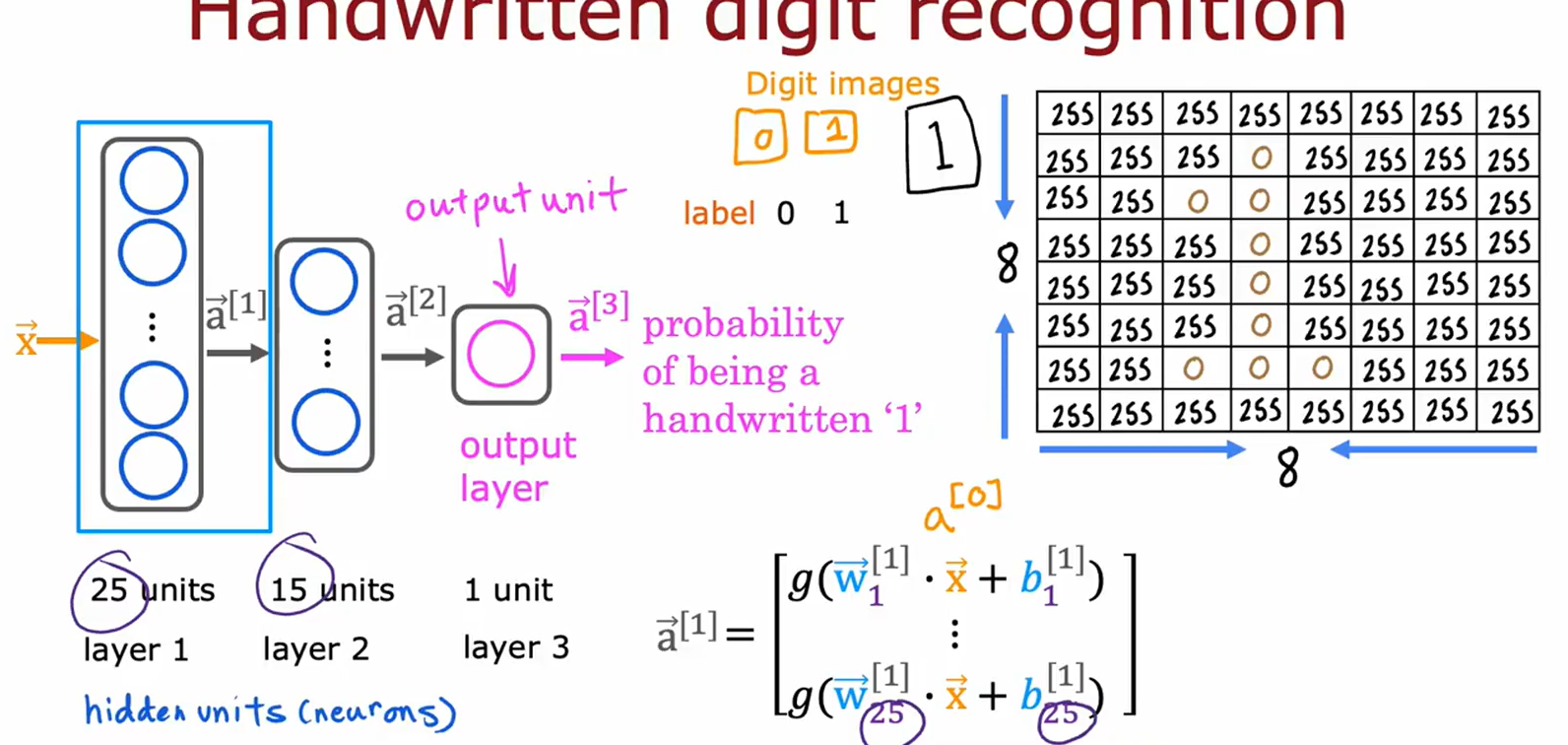
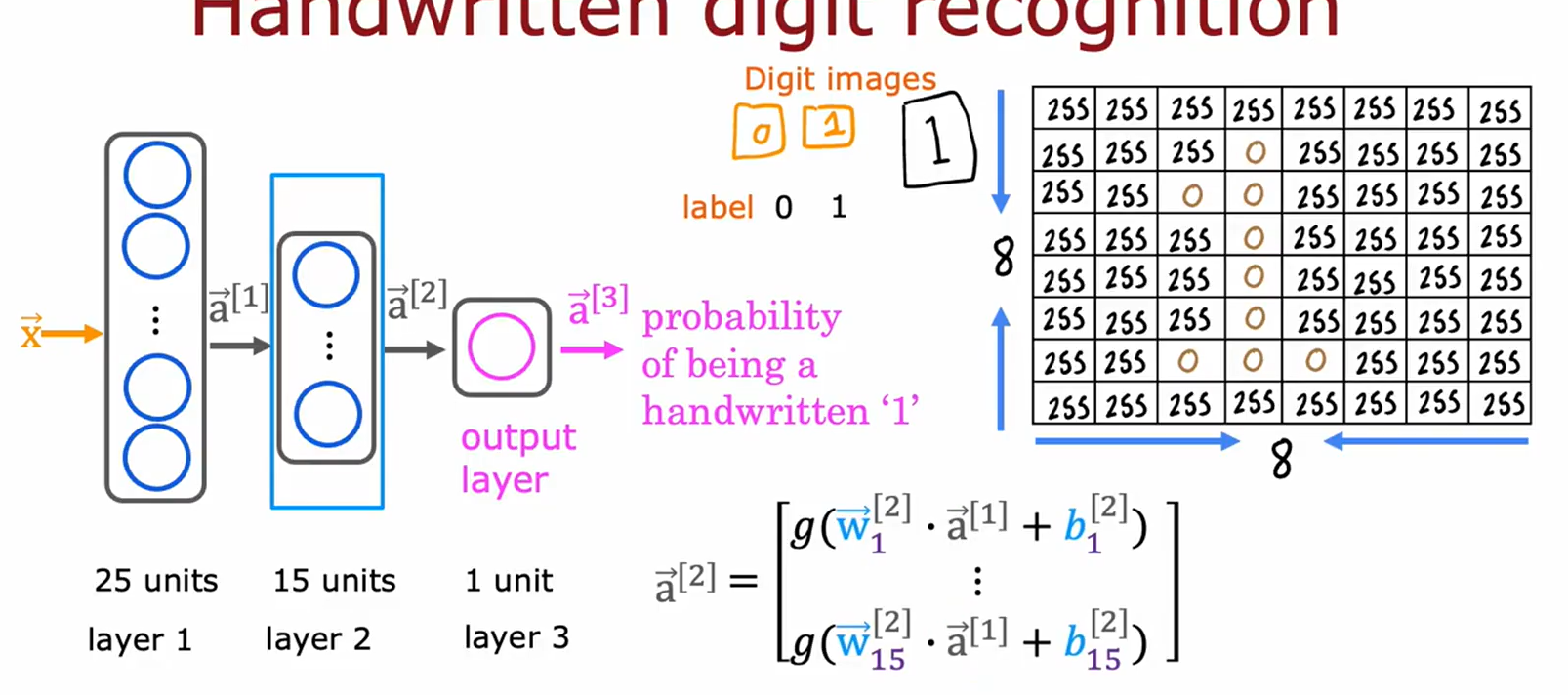
图片10:手写数字识别案例
• 主题:神经网络在图像分类中的应用。
• 关键内容:
• 输入:手写数字“1”的像素矩阵(255为白,0为黑)。
• 结构:输入层(25单元)→ 隐藏层(15单元)→ 输出层(1单元)。
• 输出:数字“1”的概率(二分类:0或1)。
• 用途:演示神经网络如何识别图像并输出概率。
总结
• 图片1-2:需求预测模型(单变量→多变量)。
• 图片3-9:神经网络架构与数学细节(结构、计算、符号)。
• 图片10:实际应用案例(手写数字识别)。
以下是针对用户上传的两张图片的核心内容解析及关键知识点总结:
图片111解析:手写数字识别的神经网络结构
-
网络架构:
• 输入层(25单元):接收手写数字图像的像素值(25维向量,图中像素值均为255,表示纯白背景)。
• 隐藏层(15单元):通过权重矩阵 W [ 2 ] W^{[2]} W[2] 和偏置 b [ 2 ] b^{[2]} b[2] 计算激活值 a [ 2 ] = g ( W [ 2 ] ⋅ a [ 1 ] + b [ 2 ] ) a^{[2]} = g(W^{[2]} \cdot a^{[1]} + b^{[2]}) a[2]=g(W[2]⋅a[1]+b[2])。
• 输出层(1单元):输出概率 a [ 3 ] a^{[3]} a[3],表示图像是数字“1”的概率(公式: a [ 3 ] = g ( W [ 3 ] ⋅ a [ 2 ] + b [ 3 ] ) a^{[3]} = g(W^{[3]} \cdot a^{[2]} + b^{[3]}) a[3]=g(W[3]⋅a[2]+b[3])。 -
关键公式:
• 激活函数(Sigmoid): g ( z ) = 1 1 + e − z g(z) = \frac{1}{1+e^{-z}} g(z)=1+e−z1,将输出压缩到0-1之间。
• 输入数据:右侧表格显示输入像素值(全255),可能为示例或空白图像。 -
流程图示:
• 数据从输入层 → 隐藏层 → 输出层流动,箭头标注计算步骤。
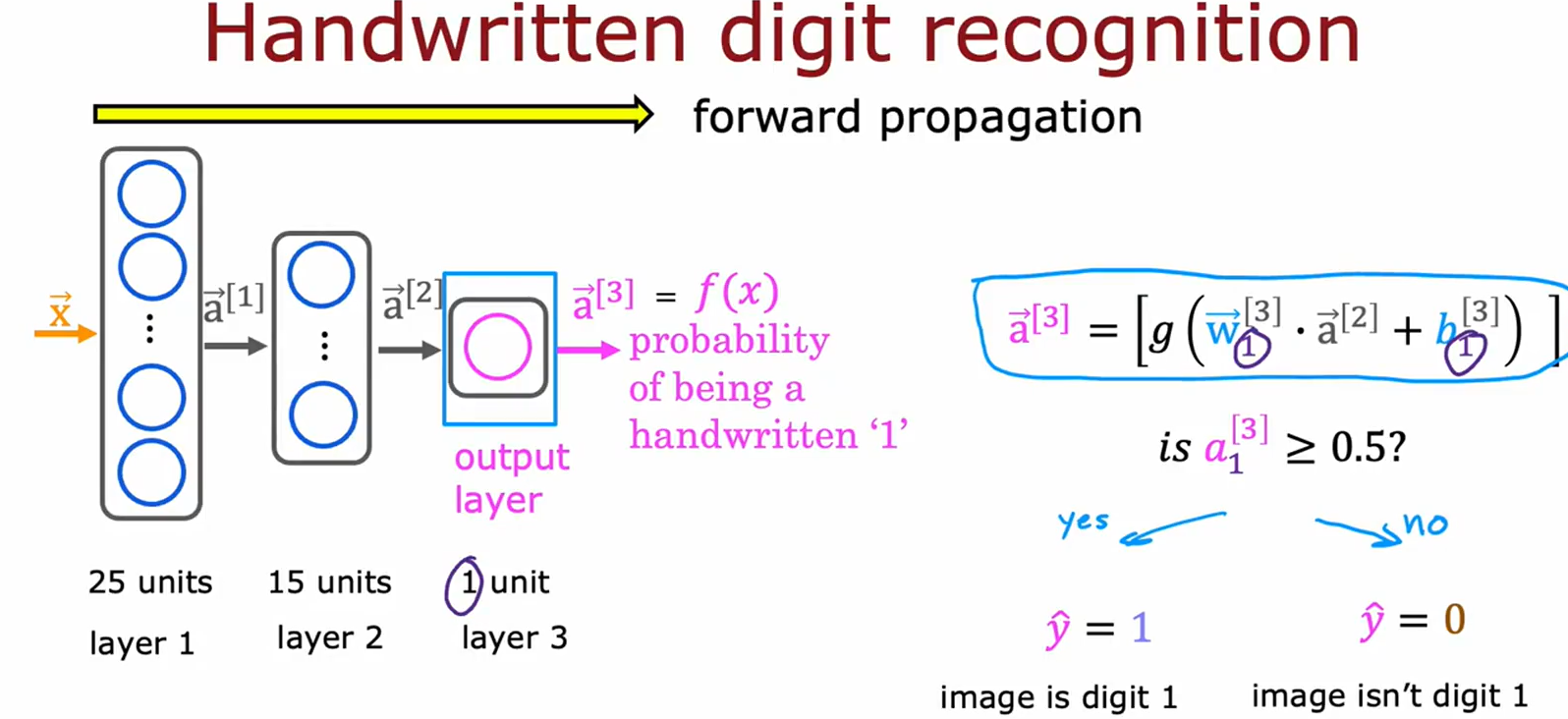
图片12解析:前向传播与分类决策
-
前向传播过程:
• 明确三层结构(25-15-1单元),输出 a [ 3 ] a^{[3]} a[3] 为概率值。
• 公式修正:图中公式显示不全,完整应为 a [ 3 ] = g ( W [ 3 ] ⋅ a [ 2 ] + b [ 3 ] ) a^{[3]} = g(W^{[3]} \cdot a^{[2]} + b^{[3]}) a[3]=g(W[3]⋅a[2]+b[3])。 -
分类规则:
• 阈值判断:若 a [ 3 ] ≥ 0.5 a^{[3]} \geq 0.5 a[3]≥0.5,预测为数字“1”(( y=1 ));否则非“1”(( y=0 ))。
• 图中用分支箭头(“yes/no”)直观展示决策逻辑。 -
应用场景:
• 适用于二分类任务(如区分“1”与非“1”数字)。


** 图13解析:二分类神经网络模型**
核心内容
• 输入数据:x = np.array([[200.0, 17.0]])(2个特征:价格200.0,运输成本17.0)
• 网络结构:
• Layer 1:Dense(units=3, activation='sigmoid') → 输出a1(3维向量)
• Layer 2:Dense(units=1, activation='sigmoid') → 输出a2(标量概率)
• 决策规则:若a2 ≥ 0.5,预测为1(是),否则为0(否)。
关键代码实现
import numpy as np
from tensorflow.keras.layers import Dense
# 输入数据
x = np.array([[200.0, 17.0]])
# 手动模拟权重(实际需训练)
W1 = np.random.randn(2, 3) # Layer 1权重
b1 = np.zeros(3) # Layer 1偏置
W2 = np.random.randn(3, 1) # Layer 2权重
b2 = np.zeros(1) # Layer 2偏置
# 前向传播
a1 = 1 / (1 + np.exp(-(x.dot(W1) + b1))) # Sigmoid激活
a2 = 1 / (1 + np.exp(-(a1.dot(W2) + b2))) # 输出概率
# 决策
yhat = 1 if a2 >= 0.5 else 0
print(f"预测概率: {a2[0][0]:.4f}, 分类结果: {yhat}")
图14解析:手写数字分类模型
核心内容
• 输入数据:x = np.array([[0.0, 245, ..., 240]])(25维向量,表示2×2像素图像)
• 网络结构:
• Layer 1:Dense(units=25, activation='sigmoid') → 输出a1
• Layer 2:Dense(units=15, activation='sigmoid') → 输出a2
• Layer 3:Dense(units=1, activation='sigmoid') → 输出a3
• 决策规则:若a3 ≥ 0.5,预测为1(数字1),否则为0(非1)。
关键代码实现
from tensorflow.keras.models import Sequential
# 定义模型
model = Sequential([
Dense(25, activation='sigmoid', input_shape=(25,)), # Layer 1
Dense(15, activation='sigmoid'), # Layer 2
Dense(1, activation='sigmoid') # Layer 3
])
# 编译模型(实际需训练)
model.compile(optimizer='adam', loss='binary_crossentropy')
# 模拟输入(25维归一化像素值)
x_digit = np.random.rand(1, 25) # 替换为实际图像数据
a3 = model.predict(x_digit)
yhat = 1 if a3 >= 0.5 else 0
print(f"数字1的概率: {a3[0][0]:.4f}, 预测结果: {yhat}")
解题要点
• 输入归一化:像素值需缩放到[0,1](如x_digit /= 255.0)。
• 多层网络:深层网络可学习更复杂特征,但需防止过拟合。
3. 两模型对比总结
| 特征 | 图片1模型(价格预测) | 图片2模型(数字分类) |
|---|---|---|
| 输入维度 | 2 (价格, 成本) | 25 (5×5图像展平) |
| 隐藏层 | 1层 (3单元) | 2层 (25→15单元) |
| 输出 | 二分类概率 | 二分类概率 |
| 激活函数 | Sigmoid | Sigmoid |
| 决策阈值 | 0.5 | 0.5 |
–


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









