







【机器学习10】-逻辑回归代价函数
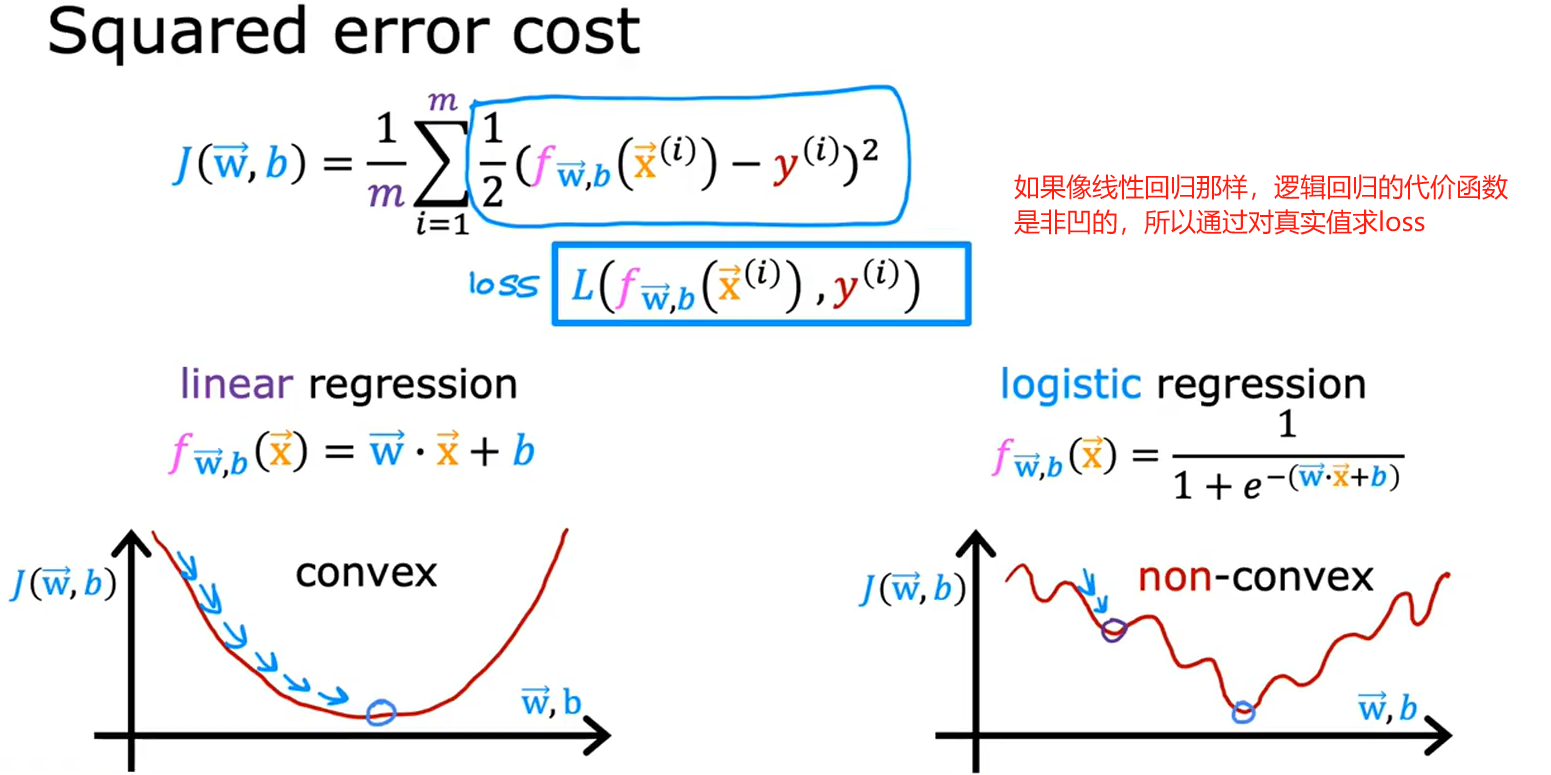
逻辑回归的代价函数采用交叉熵损失,定义为所有样本损失的均值。该函数是凸函数,保证了优化过程中梯度下降能够收敛到全局最优解,同时它等价于负对数似然函数的均值,使得最小化代价函数等同于最大化数据的似然估计。
1. 核心公式与定义
• 损失函数(单个样本):
L
(
f
w
,
b
(
x
(
i
)
)
,
y
(
i
)
)
=
−
[
y
(
i
)
log
(
f
w
,
b
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
log
(
1
−
f
w
,
b
(
x
(
i
)
)
)
]
L(f_{w,b}(x^{(i)}), y^{(i)}) = -[y^{(i)} \log(f_{w,b}(x^{(i)})) + (1-y^{(i)}) \log(1-f_{w,b}(x^{(i)}))]
L(fw,b(x(i)),y(i))=−[y(i)log(fw,b(x(i)))+(1−y(i))log(1−fw,b(x(i)))]
• 交叉熵形式:衡量预测概率
f
w
,
b
(
x
(
i
)
)
f_{w,b}(x^{(i)})
fw,b(x(i)) 与真实标签$ y^{(i)}$ 的差异。
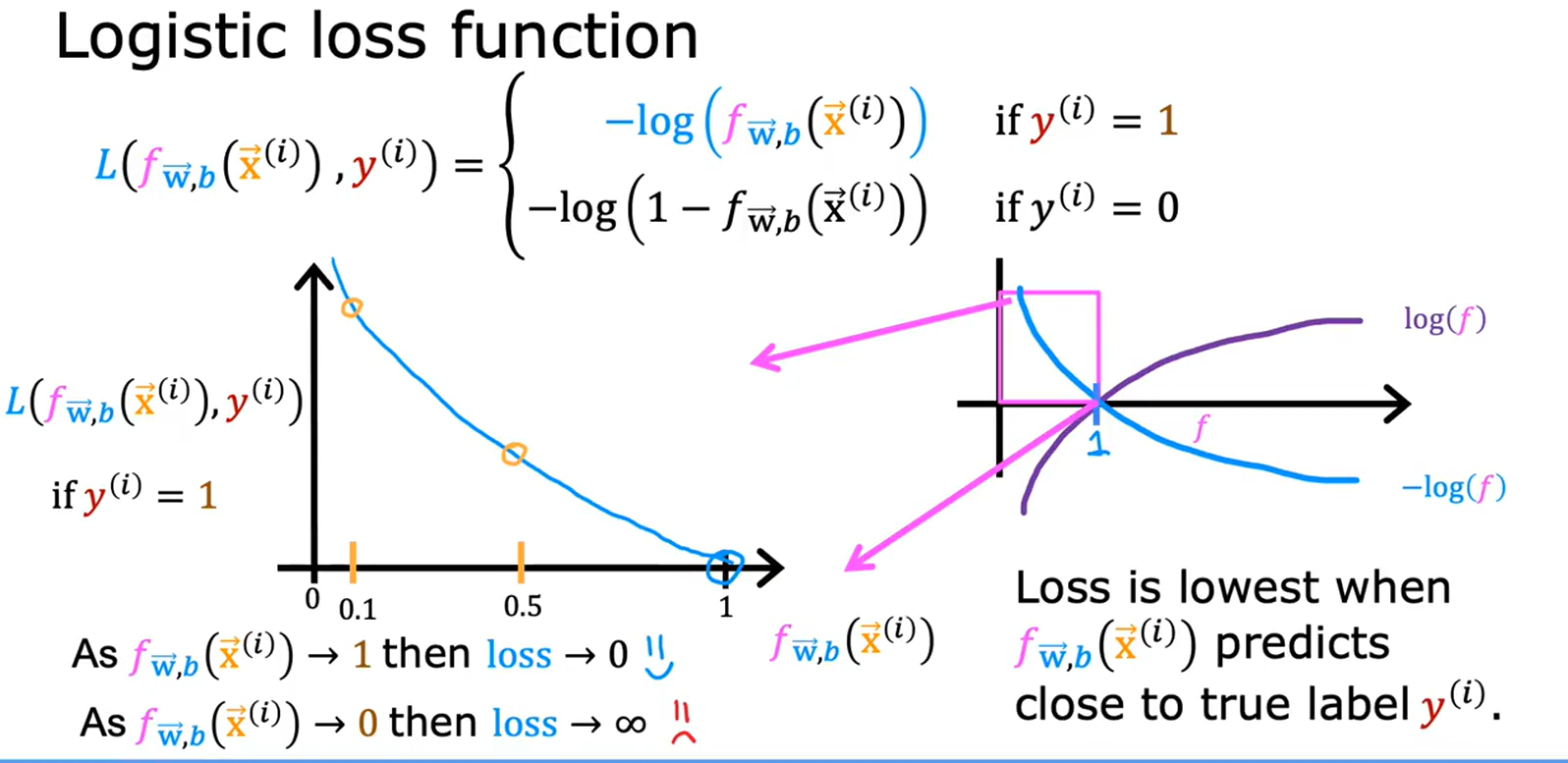
• 特性:
◦ 当
y
(
i
)
=
1
y^{(i)}=1
y(i)=1,损失为
−
log
(
f
w
,
b
(
x
(
i
)
)
)
-\log(f_{w,b}(x^{(i)}))
−log(fw,b(x(i)))(预测越接近1,损失越小)。
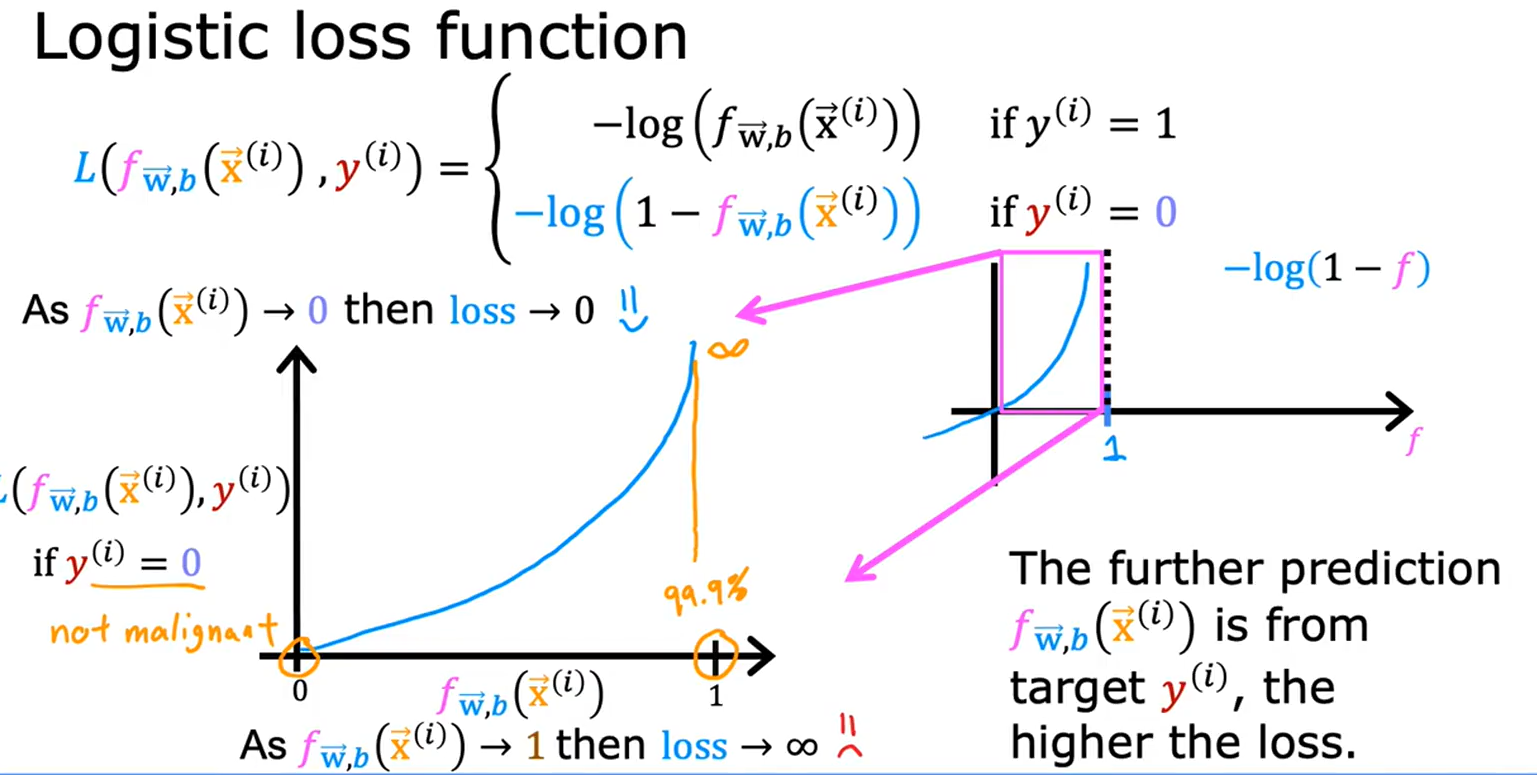
◦ 当
y
(
i
)
=
0
y^{(i)}=0
y(i)=0,损失为
−
log
(
1
−
f
w
,
b
(
x
(
i
)
)
)
-\log(1-f_{w,b}(x^{(i)}))
−log(1−fw,b(x(i)))(预测越接近0,损失越小)。

• 成本函数(全体样本):
J
(
w
,
b
)
=
1
m
∑
i
=
1
m
L
(
f
w
,
b
(
x
(
i
)
)
,
y
(
i
)
)
J(w,b) = \frac{1}{m} \sum_{i=1}^{m} L(f_{w,b}(x^{(i)}), y^{(i)})
J(w,b)=m1∑i=1mL(fw,b(x(i)),y(i))
• 含义:所有样本损失的平均值,优化目标是最小化
J
(
w
,
b
)
J(w,b)
J(w,b)。
2. 关键性质与推导
• 凸性(Convexity):
• 图片标注成本函数是凸函数(单全局最小值),保证梯度下降能收敛到最优解。
• 推导逻辑:
1. 逻辑回归的预测函数
f
w
,
b
(
x
)
=
1
1
+
e
−
(
w
T
x
+
b
)
f_{w,b}(x) = \frac{1}{1+e^{-(w^Tx + b)}}
fw,b(x)=1+e−(wTx+b)1(Sigmoid输出)。
2. 交叉熵损失对 ( w ) 的二阶导数为正,故函数凸。
• 最大似然估计(MLE):“maximum likelihood”
• 成本函数实际是负对数似然的均值,最小化
J
(
w
,
b
)
J(w,b)
J(w,b) 等价于最大化似然函数。
3. 解题思路(假设题目要求推导或应用成本函数)
问题示例:
“推导逻辑回归的成本函数,并解释其凸性意义。”
解答步骤:
-
定义预测函数:
f w , b ( x ) = σ ( w T x + b ) f_{w,b}(x) = \sigma(w^Tx + b) fw,b(x)=σ(wTx+b),其中 σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1+e^{-z}} σ(z)=1+e−z1。 -
写出似然函数:
L ( w , b ) = ∏ i = 1 m f w , b ( x ( i ) ) y ( i ) ( 1 − f w , b ( x ( i ) ) ) 1 − y ( i ) \mathcal{L}(w,b) = \prod_{i=1}^{m} f_{w,b}(x^{(i)})^{y^{(i)}} (1-f_{w,b}(x^{(i)}))^{1-y^{(i)}} L(w,b)=∏i=1mfw,b(x(i))y(i)(1−fw,b(x(i)))1−y(i). -
取负对数似然:
− log L ( w , b ) = ∑ i = 1 m − [ y ( i ) log f w , b ( x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − f w , b ( x ( i ) ) ) ] -\log \mathcal{L}(w,b) = \sum_{i=1}^{m} -[y^{(i)} \log f_{w,b}(x^{(i)}) + (1-y^{(i)}) \log(1-f_{w,b}(x^{(i)}))] −logL(w,b)=∑i=1m−[y(i)logfw,b(x(i))+(1−y(i))log(1−fw,b(x(i)))]. -
成本函数:
对似然取均值 J ( w , b ) = 1 m ∑ i = 1 m L ( f w , b ( x ( i ) ) , y ( i ) ) J(w,b) = \frac{1}{m} \sum_{i=1}^{m} L(f_{w,b}(x^{(i)}), y^{(i)}) J(w,b)=m1∑i=1mL(fw,b(x(i)),y(i)). -
凸性证明:
• 计算Hessian矩阵,证明其半正定性(利用Sigmoid导数 f ′ ( z ) = f ( z ) ( 1 − f ( z ) ) f'(z)=f(z)(1-f(z)) f′(z)=f(z)(1−f(z)))。
• 凸性保证梯度下降(如 w : = w − α ∂ J ∂ w w := w - \alpha \frac{\partial J}{\partial w} w:=w−α∂w∂J)收敛到全局最优。



















 1134
1134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









