




【读论文03】-时空预测-FMA-STGRN(特征多级注意力时空图残差网络)
摘要
目的:
为了提高水中氨氮浓度的预测精度,本研究开发了一种基于图神经网络的新型模型,称为特征多级注意力时空图残差网络 (FMA-STGRN)。
模型组成:
FMA-STGRN 模型利用气象因素和兴趣点数据等外部影响因素,以及水质监测站间氨氮浓度的时空关联信息,准确预测水中氨氮浓度。该模型由特征多级注意力模块、空间图卷积模块、时域残差分解模块和特征融合输出模块四个主要部分组成。
功能:
通过这四个模块的有机结合,FMA-STGRN 可以更有效地挖掘水质监测站之间复杂的时空关联关系,更准确地整合和利用外部影响因素,从而提高水中氨氮浓度的预测精度。
效果:
实验结果表明,FMA-STGRN 模型在各个方面都优于 RF、MART、MLP、LSTM、GRU、ST-GCN 和 ST-GAT 等其他基准模型。此外,还进行了一系列特征消融实验,以进一步揭示气象因素和兴趣点数据对模型性能的关键贡献。
1.引言
引出问题
全球水体氨氮污染问题日益严重,主要来源于工业排放、农业施肥和生活污水。高浓度的氨氮不仅危害水生生物,如导致鱼类死亡,还可能污染饮用水源,威胁人类健康。因此,准确预测水体氨氮浓度对污染治理至关重要。
存在缺陷
水体氨氮污染具有明显的时空关联性,例如上游水质会影响下游区域,且污染浓度会随时间动态变化。然而,现有研究大多未能充分整合这些时空特征,导致预测精度受限。因此,开发一种能够综合考虑时空关联性和外部环境因素的氨氮浓度预测模型,成为当前研究的关键挑战。
传统方法
在水体氨氮浓度预测中,传统方法(如物理化学模型)依赖水质参数与环境因素的机理关系进行预测,虽然精度较高,但需要大量实测数据和参数校准,实际应用较为复杂。此外,这类方法难以有效处理非线性关系和高维数据,限制了其适用性。因此,探索更高效、适应性更强的预测方法成为研究重点。
机器学习方法
与传统方法相比,机器学习和深度学习在氨氮浓度预测中展现出显著优势。支持向量机(SVM)能有效捕捉数据非线性特征,而深度神经网络(DNN)则通过多层次特征提取提升预测精度。然而,现有方法仍存在不足:多数模型仅基于单点监测数据,未能充分整合水体污染的时空关联性(如上下游影响、动态变化趋势)及外部环境因素(如气象、水文条件),导致预测结果与实际存在偏差。未来研究需重点突破时空特征融合与多源数据协同建模的技术瓶颈。
引出图神经网络
针对水体氨氮预测的现有技术瓶颈,图神经网络(GNN)展现出突破性潜力。该技术已在交通流预测、社交网络分析和药物研发等多个领域成功应用,其核心优势在于能同时建模复杂系统的时空关联与异构数据特征。例如,GNN既能解析上下游水体的空间拓扑关系,又能捕捉污染物的动态扩散过程,这种双重能力恰好契合水体氨氮预测的关键需求。通过借鉴GNN在其他领域的成功经验,构建面向水质预测的专用图神经网络架构,有望实现更精准的时空关联建模,为水质管理提供新一代智能决策工具。
本文方法
在此背景下,我们开发了一种基于图神经网络框架的新型模型,称为特征多级注意力时空图残差网络 (FMA-STGRN),专门用于预测水体氨氮浓度。该模型旨在充分利用外部影响因素,包括气象因素和兴趣点数据,并准确模拟多个水质监测站之间氨氮浓度的时空相关性。FMA-STGRN 由特征多级注意力模块、空间图卷积模块、时域残差分解模块和特征融合输出模块四个模块组成。特征多级注意力模块自动学习和理解不同外部因素影响氨氮浓度的重要性,空间图卷积模块有效捕捉监测站之间的空间关系,时域残差分解模块帮助理解和掌握水体氨氮浓度的时间特征。通过这四个模块的有机结合,FMA-STGRN 可以更有效地挖掘水质监测站之间复杂的时空相关性,更准确地整合和利用外部影响因素,从而提高水体氨氮浓度的预测精度。此外,该模型保持了良好的可解释性,有助于理解各种因素如何影响水体氨氮浓度,为城市水体管理提供更准确、更直观的决策依据。
2.材料和方法
2.1. 研究区域和数据收集
研究区域聚焦于华北地区重要的工业港口城市——天津。该市地处东经116°70′-118°06′、北纬38°55′-40°25′之间,总面积约1.19万平方公里,下辖16个行政区。本研究选择了几个水质监测站进行检查,并收集了有关氨氮浓度、气象因素和目标点 (POI) 的相关数据。其目的是构建基于图论的动态地图,用于多站点城市水质监测,从而为后续的水质预测和管理提供数据支持。
-
氨氮浓度数据
• 采集13个监测站2021-2022年的氨氮浓度连续监测数据 -
气象数据
• 选取5个气象站点的温度、风速、风向、云量和降水等参数,是从美国国家气候数据中心 (NCDC) 检索的链接 -
目标点 (POI) 数据
• 包括工业区、生活服务区、旅游消费区、交通设施区和其他相关设施等类别。手动排序的数据基于百度地图中的目标点
2.2. 基于图论的城市多站点水质监测动态图的构建
本研究采用动态图论方法构建水质监测网络,其核心建模框架如下:
• 顶点集V:顶点属性矩阵Xt∈ℝ¹³ˣ¹:13个水质监测站点(n=13)
• 边集E:基于地理距离或河流连接计算权重,构建的站点连接关系
• 权重矩阵W∈ℝ¹³ˣ¹³:量化站点间的空间关联强度
为了更好地挖掘气象因素、感兴趣点和水质参数之间的相关性,可以将这些数据集成到属性矩阵中。具体而言,属性矩阵Xt可以扩展到
Xt∈ℝn×(1+k₁+k₂)
- 整合了三类数据:
- 水质参数(氨氮浓度(1维))
- 气象因素(
k₁=5维): ▪ 温度 ▪ 风速 ▪ 风向 ▪ 云量 ▪ 降水 - POI数据(
k₂=5维): ▪ 工业区 ▪ 生活服务区 ▪ 旅游消费区 ▪ 交通设施区 ▪ 其他相关设施
步骤 1:确定顶点属性
在本研究中,折点表示水质监测站。每个顶点具有以下属性:1) 水质参数;2) 气象因素,包括温度、风速、风向、云量和降水;3) 包括工业区、生活服务区、旅游消费区、交通设施区和其他相关设施在内的目标点。
第 2 步:边权重计算和邻接矩阵构建
边表示水质监测站之间的关联程度。在本研究中,使用基于空间距离的方法计算边权重。最初,我们使用 Haversine 公式来计算每对监测站之间的地理距离(Robusto,1957)。用于计算地球表面两点间的大圆距离:Haversine距离公式
d ( i , j ) = 2 arcsin ( sin 2 ( lat i − lat j 2 ) + cos ( lat i ) cos ( lat j ) sin 2 ( lon i − lon j 2 ) ) d(i,j) = 2 \arcsin \left( \sqrt{\sin^2 \left( \frac{\text{lat}_i - \text{lat}_j}{2} \right) + \cos(\text{lat}_i) \cos(\text{lat}_j) \sin^2 \left( \frac{\text{lon}_i - \text{lon}_j}{2} \right)} \right) d(i,j)=2arcsin(sin2(2lati−latj)+cos(lati)cos(latj)sin2(2loni−lonj))
参数说明:
- d ( i , j ) d(i,j) d(i,j) 站点 i , j i,j i,j之间的地理距离
lat_i,lon_i:点i的纬度和经度(弧度制)lat_j,lon_j:点j的纬度和经度(弧度制)- 结果单位为弧度,实际距离需乘以地球半径(约6371km)
第 3 步:节点特征融合
为了将各种特征集成到一个统一的数据表示中,本研究采用了特征融合方法,将与监测站相关的水质参数、气象因素和兴趣点 (POI) 数据合并到一个多维特征向量中。具体来说,归一化水质参数、气象数据和 POI 指标根据特征维度连接起来,形成代表每个监测站的特征向量。
x i = [ x i w , x i m , x i p ] x_i = [x_i^w, x_i^m, x_i^p] xi=[xiw,xim,xip]
监测站特征向量公式
x i = [ x i w , x i m , x i p ] x_i=[x_i^w,x_i^m,x_i^p] xi=[xiw,xim,xip]
参数说明:
x_i^w:站点i的标准化水质参数x_i^m:站点i的标准化气象数据x_i^p:站点i的标准化POI指标[,]:表示向量连接运算
第四步:动态图构建。
- 以水质参数采集时间点为基准时间 t t t
- 气象数据选取:
- 选择最近气象站
- 取最接近 t t t时刻的数据
- 缺失值处理:采用插值方法填补
- 属性矩阵序列: X ( 1 ) , X ( 2 ) , . . . , X ( T ) X^{(1)},X^{(2)},...,X^{(T)} X(1),X(2),...,X(T)
- 特征张量构建:通过时间维度堆叠特征向量
单站单时刻特征向量:
X
t
i
=
[
x
t
i
1
,
x
t
i
2
,
.
.
.
,
x
t
i
m
]
X_t^i=[x_t^{i1},x_t^{i2},...,x_t^{im}]
Xti=[xti1,xti2,...,xtim]
2.3. 特征多级注意力时空图残差网络的构建
针对城市河流多站点水质参数联合预测的问题,本文提出了一种基于特征多层次注意力时空图残差网络(FMA-STGRN)的多站点水质参数预测模型。该模型综合考虑了空间和时间信息,以及特征之间的相关性,从而提高了预测精度。
FMA-STGRN 模型的整体架构包括四个主要组件:特征多级注意力模块、空间域图卷积模块、时域残差分解以及特征融合和输出模块。
首先,特征多级注意力模块对输入特征进行加权聚合,捕获不同特征之间的相关性,以提取重要的特征信息。其次,空间域图卷积模块通过捕获相邻站点之间的空间信息来处理空间依赖关系。接下来,时域残差分解 通过捕获历史数据中的时间依赖关系来处理时间序列数据。最后,特征融合和输出模块将前面模块的输出组合在一起,并生成预测结果。图 2 显示了 FMA-STGRN 模型的整体架构。
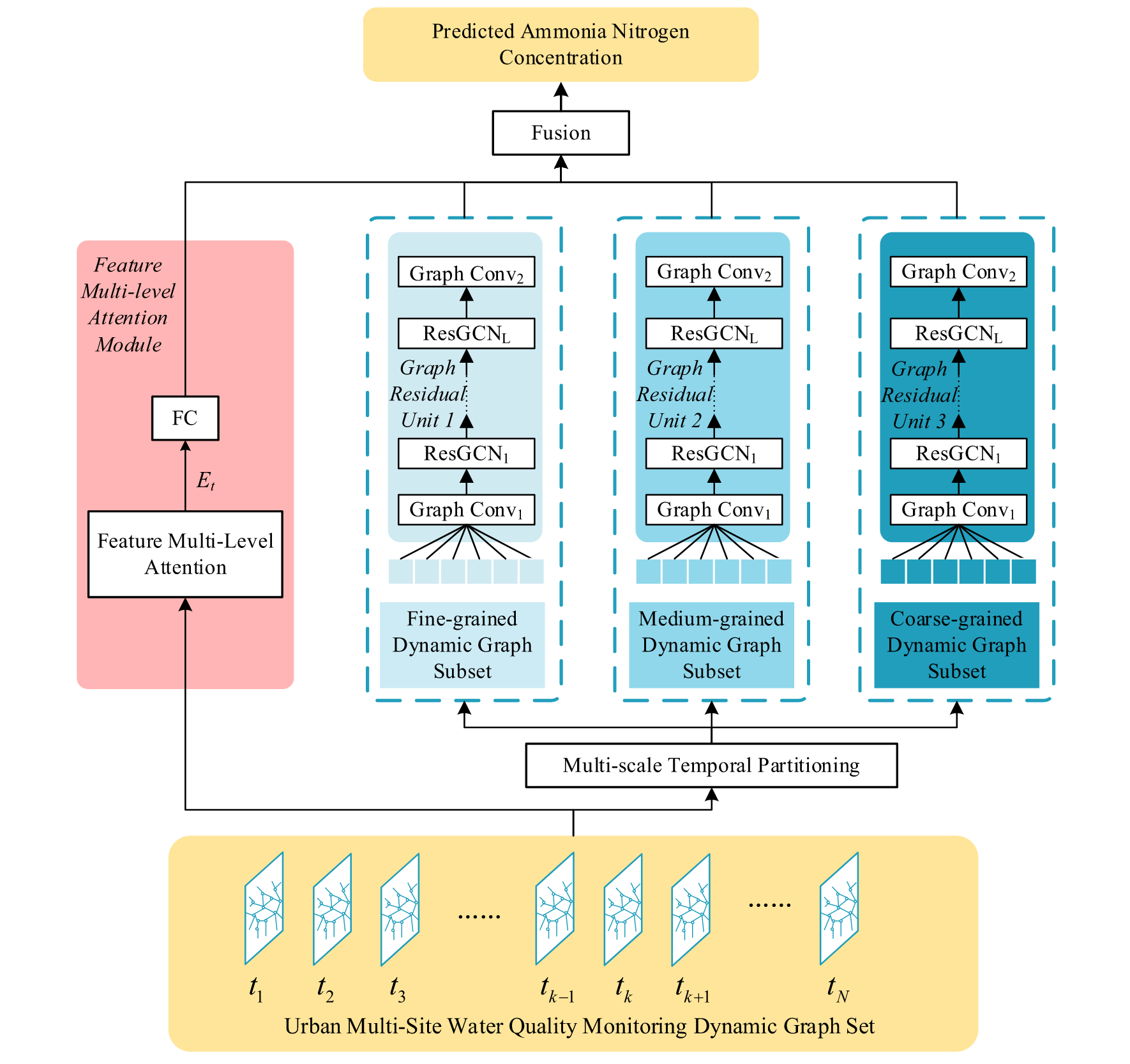
图 2
2.3.1. 特征多级注意力模块
特征多级注意力模块(FMAM)的主要作用是在特征层面捕捉外部因素(气象因素、兴趣点)和水质参数之间的相互依赖关系,以提取更具代表性的特征信息。该模块基于注意力机制设计,可以自适应调整不同特征之间的权重分配。
- 特征重要性学习:自动识别不同外部因素(气象/POI)对氨氮浓度的影响权重
- 多级注意力机制:通过层级结构捕捉特征间的复杂关系
注意力权重计算:
e
i
j
=
a
(
W
x
i
,
W
x
j
)
e_{ij}=a(Wx_i,Wx_j)
eij=a(Wxi,Wxj)
α
i
j
=
e
x
p
(
e
i
j
)
∑
k
e
x
p
(
e
i
k
)
\alpha_{ij}=\frac{exp(e_{ij})}{\sum_k exp(e_{ik})}
αij=∑kexp(eik)exp(eij)
2.3.2. 时域残差分解
在本研究中,为了充分探究不同时间粒度的水质监测数据特征,我们设计了一个时间残差分解模块。在本模块中,来自各个水质监测站的时空数据被组织成一个三维张量图。具体来说,三维张量图是一种数据结构,其中第一个维度表示时间,其余两个维度表示图结构(即节点和边)。从形式上讲,这涉及沿时间维度的不同时间点连接图形(Zhang et al., 2017)。这种组织方式允许模型同时考虑不同时间粒度的信息,例如细粒度、中粒度和粗粒度。在本研究中,步长为 1 、 6 和 30,分别代表 4 小时、 24 小时 (1 天) 和 120 小时 (5 天)。
三维张量图由以下部分组成:
•细粒度 (fg) 部分由具有相邻时间戳的图形组成,主要捕获短期动态。
•中粒度 (mg) 部分,由较长时间间隔(例如一天)内的图形组成,主要旨在捕获周期性特征。
•粗粒度 (cg) 部分由更长时间间隔(例如五天)内的图表组成,主要旨在捕捉长期趋势。
2.3.3. 空间域图卷积模块
空间图卷积模块 (SGCM) 的主要目标是捕获空间域中节点之间的依赖关系,从而充分利用多站点水质监测数据中的空间结构信息。该模块在不同时间戳接收一系列结构一致的图,
-
输入处理:
- 接收时间序列图数据: G t − p , . . . , G t − 1 G_{t-p},...,G_{t-1} Gt−p,...,Gt−1
- 采用加权邻接矩阵(非传统二值矩阵)
-
三级处理结构:
- 初始GCN模块(
N
1
=
3
N_1=3
N1=3层):
H l = σ ( D ~ − 1 2 W D ~ − 1 2 H l − 1 W l ) , 1 ≤ l ≤ N 1 H^l = \sigma(\tilde{D}^{-\frac{1}{2}}W\tilde{D}^{-\frac{1}{2}}H^{l-1}W^l), \quad 1 \leq l \leq N_1 Hl=σ(D~−21WD~−21Hl−1Wl),1≤l≤N1 - 残差GCN模块(
N
2
=
8
N_2=8
N2=8层):
H l = H l − 1 + σ ( D ~ − 1 2 W D ~ − 1 2 H l − 1 W l ) H^l = H^{l-1} + \sigma(\tilde{D}^{-\frac{1}{2}}W\tilde{D}^{-\frac{1}{2}}H^{l-1}W^l) Hl=Hl−1+σ(D~−21WD~−21Hl−1Wl) - 末端GCN模块( N 1 = 3 N_1=3 N1=3层)
- 初始GCN模块(
N
1
=
3
N_1=3
N1=3层):
空间域图卷积模块基于多级注意力特征模块获得的特征表示,通过空间域内的卷积运算更新多站点水质参数联合预测模型中的节点特征。通过堆叠多层图卷积,该模型可以捕获更高阶的空间依赖关系,从而充分利用多站点水质监测数据中的空间结构信息,为后续的时域建模提供更丰富的特征表示。
2.3.4 特征融合与输出模块
接收四个模块的输出:
- 多级特征注意力输出 O F M A O_{FMA} OFMA
- 细粒度空间卷积输出 O G R O_{GR} OGR
- 中粒度空间卷积输出 O M R O_{MR} OMR
- 粗粒度空间卷积输出 O C R O_{CR} OCR
核心计算过程
-
特征矩阵转换:
- 将各模块输出的图结构转为 n × m n \times m n×m矩阵
- n n n:监测站数量, m m m:特征维度
-
加权特征融合:
O f u s i o n = W F M A ⊙ O F M A + W G R ⊙ O G R + W M R ⊙ O M R + W C R ⊙ O C R O_{fusion} = W_{FMA} \odot O_{FMA} + W_{GR} \odot O_{GR} + W_{MR} \odot O_{MR} + W_{CR} \odot O_{CR} Ofusion=WFMA⊙OFMA+WGR⊙OGR+WMR⊙OMR+WCR⊙OCR- ⊙ \odot ⊙: Hadamard积(逐元素乘)
- W ∗ W_{*} W∗: 可学习权重矩阵
2.4 .1模型实现与性能评估
实验设置
-
数据集划分:
- 总样本量:3000个静态图(2021-2022年)
- 训练集:2021年1500个样本
- 测试集:2022年1500个样本
-
硬件环境:
- GPU: NVIDIA 3080Ti
- 系统: Windows 10
- 软件: Python 3.9.7 + PyTorch 1.12.0
-
训练配置:
- 优化器: Adam (初始学习率0.001)
- 损失函数: 均方误差(MSE)
M S E = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 MSE = \frac{1}{N}\sum_{i=1}^N (y_i - \hat{y}_i)^2 MSE=N1i=1∑N(yi−y^i)2
2.4.1评估指标
-
基础预测:
- 预测步长:1步(4小时预测)
-
多尺度预测:
- 6步(24小时)
- 12步(48小时)
- 18步(72小时)
-
核心指标:
平均绝对误差 (MAE)、均方根误差 (RMSE)、平均绝对百分比误差 (MAPE)、相关系数 r 和协议索引 (IA)。
2.4.2 比较模型
- 随机森林 (RF)
- 类型:集成学习/决策树
- 机制:通过Bootstrap采样构建多棵决策树,输出均值预测
- 优势:抗过拟合、可解释性强
- 局限:难以处理时空依赖性
- 多重加性回归树 (MART)
- 类型:Boosting集成
- 机制:迭代构建浅层决策树,梯度提升优化
- 优势:处理高维特征交互
- 局限:对异常值敏感
- 多层感知器 (MLP)
- 类型:前馈神经网络
- 结构:单隐藏层全连接
- 优势:通用函数逼近
- 局限:忽略时空结构
- 长短期记忆网络 (LSTM)
- 类型:递归神经网络
- 特性:门控机制保持长期记忆
- 优势:时序依赖建模
- 局限:仅处理单点时序
- 门控循环单元 (GRU)
- 类型:轻量级RNN
- 改进:合并LSTM门结构
- 优势:计算效率更高
- 局限:仍限于单点预测
- 时空图卷积网络 (ST-GCN)
- 类型:图神经网络
- 机制:联合时空卷积
- 优势:拓扑结构建模
- 局限:固定邻接关系
- 时空图注意力网络 (ST-GAT)
- 类型:图注意力网络
- 改进:动态邻域权重
- 优势:自适应空间关系
- 局限:计算复杂度高
2.4.3. 特征消融实验的构建与设计
为了探究特征多级注意力模块 (FMAM) 对预测性能的影响,本研究设计了一系列特征消融实验。在这些实验中,逐渐去除了特定的数据源,以分析不同数据对模型性能的影响。特征消融实验分为三组,设计如下:
第 1 组 (FMA-STGRN-0):气象因子数据和兴趣点 (POI) 数据均被删除。本实验仅依靠水质参数动态图数据预测水质,旨在评价仅考虑水质参数动态图信息时的模型性能。
第 2 组 (FMA-STGRN-1):仅使用气象因子数据,而排除了 POI 数据。本实验评估了将水质参数的动态图形信息与气象因子数据(不包括 POI 数据)相结合时的模型性能。
第 3 组 (FMA-STGRN-2):仅使用 POI 数据,而排除了气象因子数据。本实验评估了将水质参数动态图信息与 POI 数据(不包括气象因子数据)相结合时的模型性能。
通过这三组特征消融实验,本研究旨在揭示气象因子数据和 POI 数据在特征多级注意力模块中的贡献及其对水质参数预测性能的影响。接下来,我们将详细讨论特征消融实验的结果,以及每个实验组在不同水质参数预测中的表现。
| 实验组 | 使用数据源 | 目标评估内容 |
|---|---|---|
| FMA-STGRN-0 | 仅水质参数动态图 | 纯水质时序特征的预测能力 |
| FMA-STGRN-1 | 水质图 + 气象因子 | 气象要素对预测的贡献度 |
| FMA-STGRN-2 | 水质图 + POI数据 | 人类活动因素的预测价值 |
3. 结果和讨论
3.1. 使用我们的模型预测各个水质监测站的氨氮浓度
本研究利用特征多层次注意力时空图残差网络模型预测天津市 13 个水质监测站(标记为 A01 至 A13)的氨氮浓度。该模型的预测性能因不同的站点而异。我们将在以下各节中从多个角度分析这些差异。
首先,我们关注两个主要的误差指标:MAE (平均绝对误差) 和 RMSE (均方根误差)。根据表 3 中的数据,我们观察到大多数站点的预测误差相对较小。具体来说,站点 A04 和 A08 脱颖而出,它们的 MAE 值均为 0.038,这表明我们的模型在这些站点的预测准确性非常高。然而,A06 和 A07 站的 MAE 值较高,分别为 0.101 和 0.108。这表明这些地点可能存在独特的水质条件或数据特征,需要进一步深入调查。
3.2. 所提模型与其他方法的氨氮浓度预测结果对比
在本节中,我们将深入研究 FMA-STGRN 模型在预测氨氮浓度方面的性能,并将其与其他高级预测方法进行比较。
根据表 4 中的数据,很明显 FMA-STGRN 模型在两个关键指标上表现出优异的性能:平均绝对误差 (MAE) 和均方根误差 (RMSE)。首先,让我们关注 MAE 指标,它帮助我们了解模型预测的平均偏差水平。
通过分析 MAE 的平均值、最小值和最大值,我们可以观察到 FMA-STGRN 模型在预测氨氮浓度方面表现出更高的精度。其平均 MAE 为 0.048,明显低于 RF 和 MART 等其他方法,后者的平均 MAE 值分别为 0.092 和 0.219。特别是与 MART 和 MLP 方法相比,FMA-STGRN 模型显著降低了误差,表明它能够更准确地预测氨氮浓度。
通过进一步观察最大和最小 MAE 值,我们可以看到 FMA-STGRN 模型不仅提供最低的平均误差,而且误差范围相对较小。这表明 FMA-STGRN 模型不仅可以准确预测氨氮浓度,而且具有很高的稳定性和可靠性。
接下来,我们来分析均方根误差 (RMSE)。RMSE 是衡量预测误差的常用标准,可帮助我们更好地了解预测中的潜在最大误差。FMA-STGRN 模型再次展示了其在减少预测误差方面的强大能力。其平均 RMSE 为 0.122,低于其他方法,表明其在预测氨氮浓度方面具有优势。从图 4 中,我们可以观察到 FMA-STGRN 模型在大多数站点显示出更高的 r 和 IA 值,进一步证实了它在预测氨氮浓度方面的高精度和一致性。
综上所述,FMA-STGRN 模型在预测氨氮浓度方面表现出显著优势,不仅在准确性方面优于其他方法,而且在稳定性和可靠性方面均优于其他方法。这一表现凸显了 FMA-STGRN 模型在环境科学与工程领域的潜力和价值,为未来的研究和应用奠定了坚实的基础。
3.3. 特征多级注意力模块对预测性能的影响及对消融的实验研究
在探索多级特征注意力模块在预测性能中的决定性作用的同时,我们设计了一套特征消融实验。这些实验旨在通过逐步消除部分数据来分析不同数据源对模型性能的影响。这些实验分为三组:FMA-STGRN-0、FMA-STGRN-1 和 FMA-STGRN-2。本节将详细讨论从这些实验组获得的结果,以及它们在预测水体氨氮浓度方面的性能。
在比较每个实验组的误差时,我们发现 FMA-STGRN-0 的误差率最低,其次是 FMA-STGRN-2,FMA-STGRN-1 的误差率最高。这表明气象因素和 POI 数据在预测氨氮浓度方面起着重要作用。此外,与 FMA-STGRN-0 相比,FMA-STGRN-1 和 FMA-STGRN-2 表现出更高的预测性能,表明气象因素和 POI 数据都有一定的影响。特别是,FMA-STGRN-1 的精度高于 FMA-STGRN-2,强调气象因子比 POI 数据更能增强天津市水体氨氮浓度的预测。
3.4. 方法限制和未来讨论
3.4.1. 方法限制
在这项研究中,我们采用了基于地理空间距离的无向图神经网络来模拟城市河流的水质参数。虽然这种方法有效地捕获了水质监测点之间的空间依赖关系,但它也存在一些明显的局限性。首先,该模型完全依赖地理空间距离来建立图形结构,这可能无法完全捕捉河流网络内复杂的水文关系。例如,两个地理上接近的点在实际河流网络中可能具有错综复杂的上下游关系,这在仅基于地理空间距离的模型中可能会被忽略。此外,当前模型中未考虑河流中的河流交汇处,这些交汇处通常缺乏水质监测站。这种遗漏可能导致忽视这些河流交汇处在水质传播和变化中的关键作用。
3.4.2.为了进一步优化模型,我们预计会有以下增强功能:
1.将河流交汇处引入虚拟顶点:认识到河流交汇处在水质传播中的重要性,以及它们通常缺乏监测站,我们的目标是将它们作为虚拟顶点合并到图形模型中,从而更准确地模拟河流网络水动力学。
2.使用有向图表示河流流向:鉴于河流固有的方向性和流动性,我们计划利用有向图来更好地表示河流流向。这将增强对河流网络内水质传播和变化的模拟。
3.使用实际河流拓扑定义边权重:除了仅仅依赖地理空间距离之外,我们还打算考虑河流的真实拓扑属性,例如河流长度、流速和净流速,以分配边权重。这将捕获河流之间真正的相互依赖关系,并为模型提供更多的背景信息。
通过整合物理过程和河流的真实拓扑结构,我们的目标是实现对河流水质参数的更精确预测。通过这些增强功能,我们渴望开发一个更准确、更具代表性的图神经网络模型,为城市河流水质预测和分析奠定基础。
4. 结论
在这项研究中,我们引入并广泛研究了一种基于图神经网络的新型预测模型,称为特征多级注意力时空图残差网络 (FMA-STGRN)。该模型旨在通过结合各种外部影响因素,如气象因素、兴趣点 (POI) 数据和水质参数动态图形数据,准确预测水体中的氨氮浓度。
我们的研究结果表明,FMA-STGRN 模型在预测水氨氮浓度方面优于 RF、MART、MLP、LSTM、GRU、ST-GCN 和 ST-GAT 等其他基准模型。这一优势在很大程度上归功于特征多级注意力模块的引入,该模块可以自动学习和理解不同外部因素在影响氨氮浓度方面的重要性。通过一系列特征消融实验,我们进一步了解了气象因素和 POI 数据对模型性能的关键贡献。移除这些特征后预测性能的显著下降表明它们在预测水氨氮浓度方面的重要性。此外,我们的实验结果表明,气象因素对提高预测性能的影响大于 POI 数据,尽管两者都是模型的重要输入。
尽管 FMA-STGRN 模型在预测水氨氮浓度方面取得了显著成果,但仍有改进的余地。未来的工作可以考虑纳入更多类型的外部影响因素,并在更大的数据集上进一步验证和优化模型。
总体而言,我们认为 FMA-STGRN 模型为水质监测和城市水资源管理提供了强大而实用的工具。其优异的性能为预测和理解水氨氮浓度开辟了广阔的前景。我们期待着该领域未来的研究和应用。
参考文献
[1] Wang H, Zhang L, Zhao H, et al. Feature multi-level attention spatio-temporal graph residual network: a novel approach to ammonia nitrogen concentration prediction in water bodies by integrating external influences and spatio-temporal correlations[J]. Science of the Total Environment, 2024, 906: 167591.


















 2911
2911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









