




【机器学习02】梯度下降
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数J(w,b)J(w, b)J(w,b)的最小值。
梯度下降背后的思想是:开始时我们随机选择一个参数的组合(θ_0,θ_1,…,θ_n ),计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到到到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
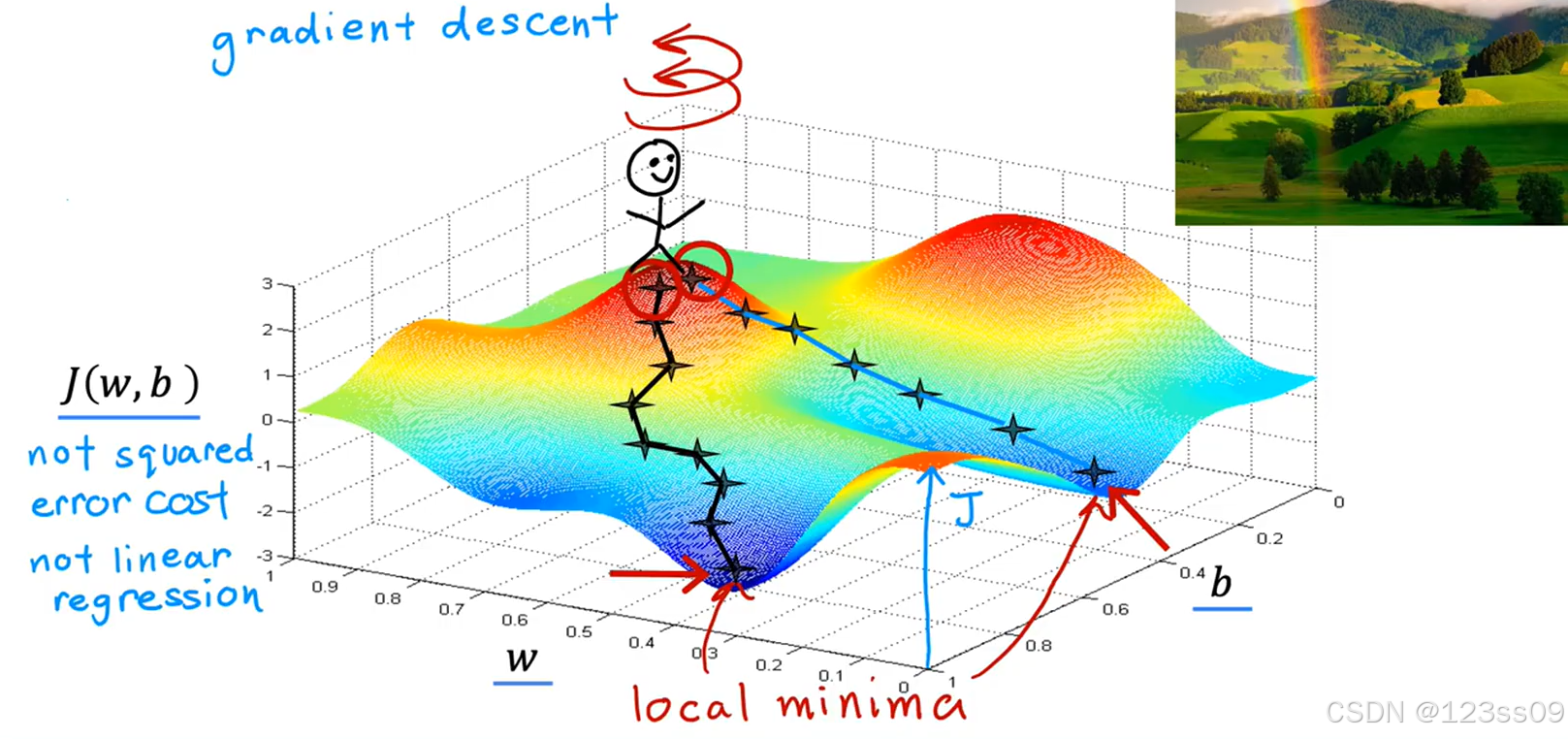
梯度下降算法更新步骤
1. 重复直到收敛
Repeat until convergence \text{Repeat until convergence} Repeat until convergence
2. 更新公式
w=w−α∂∂wJ(w,b)
w = w - \alpha \frac{\partial}{\partial w} J(w, b)
w=w−α∂w∂J(w,b)
b=b−α∂∂bJ(w,b)
b = b - \alpha \frac{\partial}{\partial b} J(w, b)
b=b−α∂b∂J(w,b)
3. 同步更新
temp_w=w−α∂∂wJ(w,b)
\text{temp\_w} = w - \alpha \frac{\partial}{\partial w} J(w, b)
temp_w=w−α∂w∂J(w,b)
temp_b=b−α∂∂bJ(w,b)
\text{temp\_b} = b - \alpha \frac{\partial}{\partial b} J(w, b)
temp_b=b−α∂b∂J(w,b)
w=temp_w
w = \text{temp\_w}
w=temp_w
b=temp_b
b = \text{temp\_b}
b=temp_b
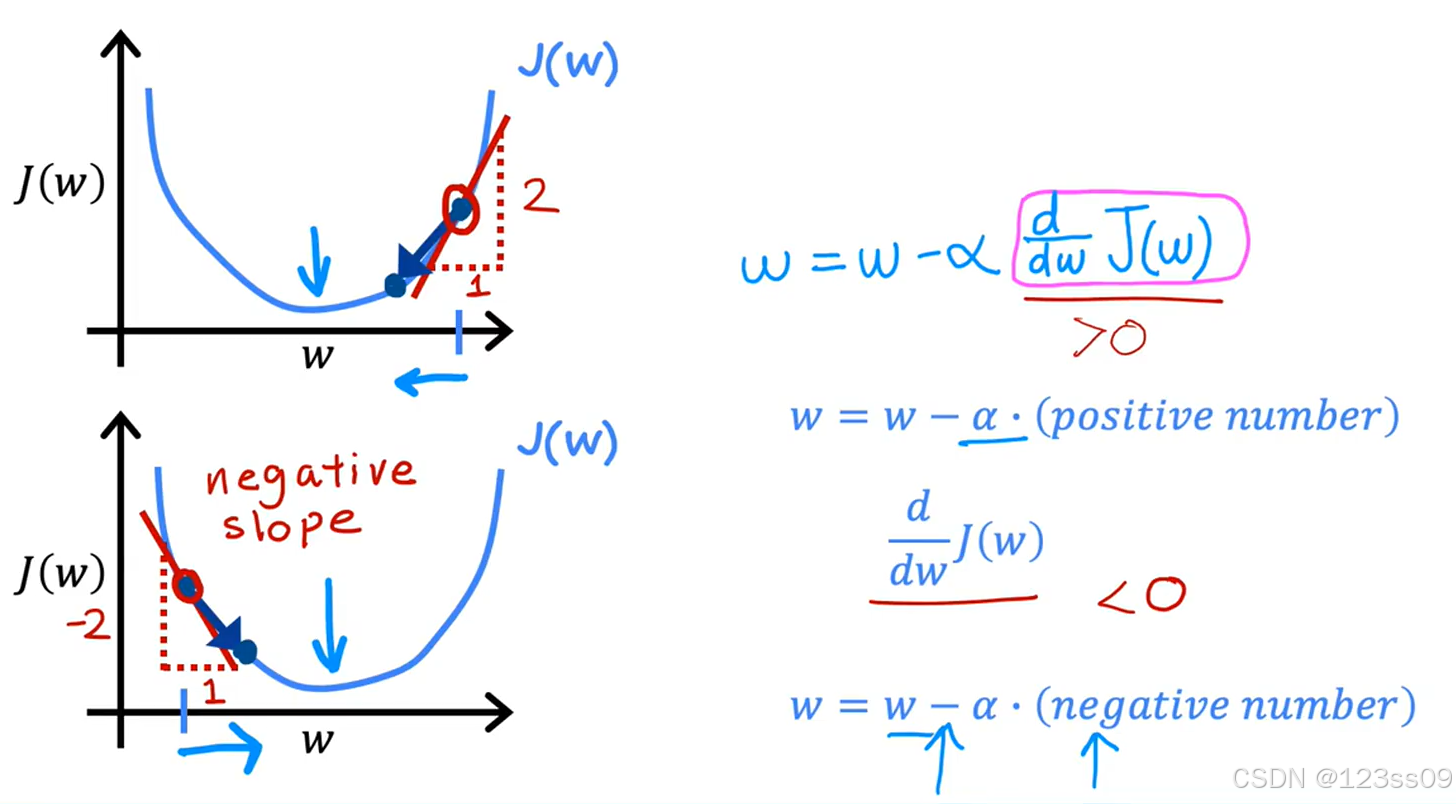
4. 强调内容
- 学习率:α\alphaα 控制每次更新的步长。
- 导数:偏导数表示成本函数在当前参数下的变化率。
- 同时更新:必须同时更新 www 和 bbb。
向量表示

进阶
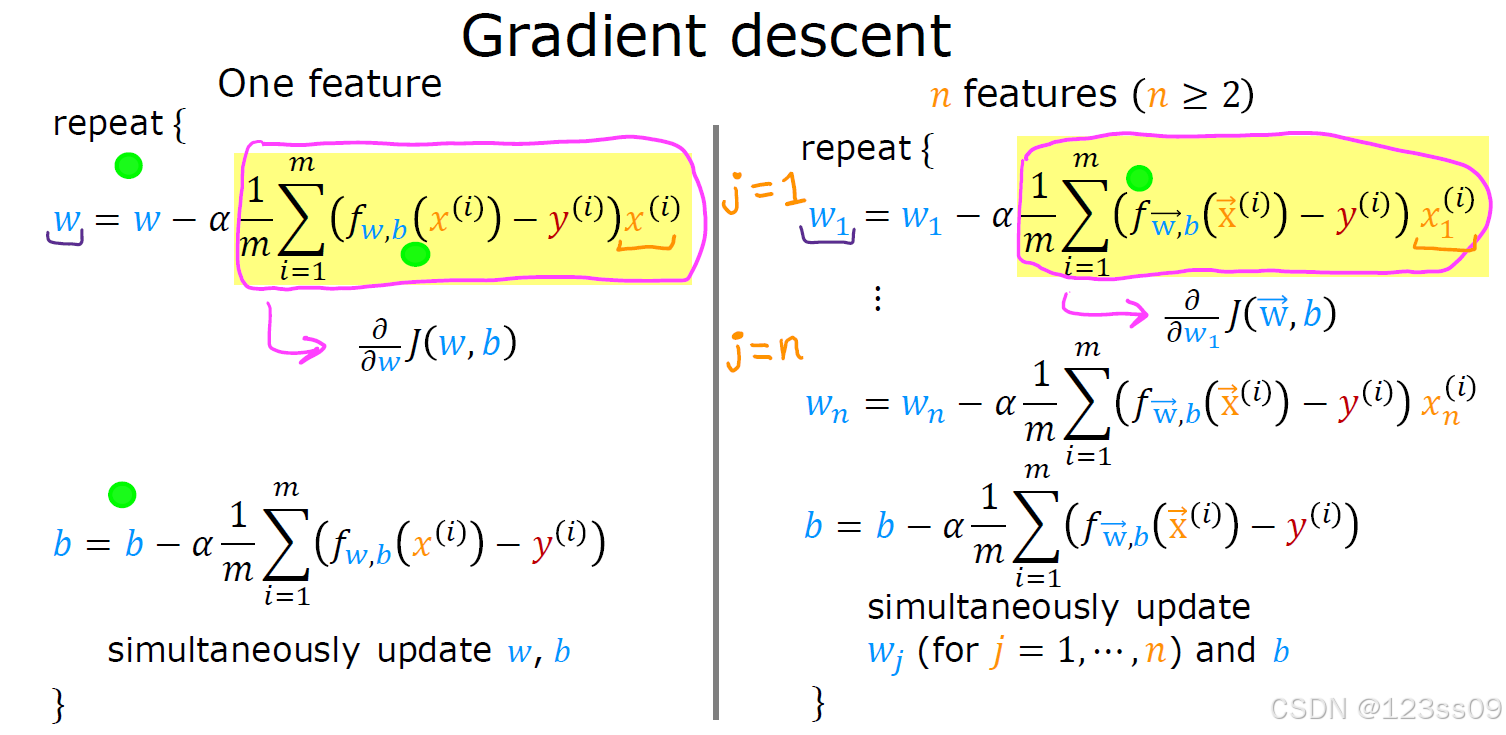
梯度下降算法更新步骤-进阶
1. 单特征
w=w−α1m∑i=1m(fw,b(x(i))−y(i))x(i)
w = w - \alpha \frac{1}{m} \sum_{i=1}^{m} (f_{w,b}(x^{(i)}) - y^{(i)}) x^{(i)}
w=w−αm1i=1∑m(fw,b(x(i))−y(i))x(i)
b=b−α1m∑i=1m(fw,b(x(i))−y(i))
b = b - \alpha \frac{1}{m} \sum_{i=1}^{m} (f_{w,b}(x^{(i)}) - y^{(i)})
b=b−αm1i=1∑m(fw,b(x(i))−y(i))
2. 多特征
wj=wj−α1m∑i=1m(fw⃗,b(x⃗(i))−y(i))xj(i)
w_j = w_j - \alpha \frac{1}{m} \sum_{i=1}^{m} (f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)}) x_j^{(i)}
wj=wj−αm1i=1∑m(fw,b(x(i))−y(i))xj(i)
b=b−α1m∑i=1m(fw⃗,b(x⃗(i))−y(i))
b = b - \alpha \frac{1}{m} \sum_{i=1}^{m} (f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)})
b=b−αm1i=1∑m(fw,b(x(i))−y(i))
3. 同步更新
- 单特征:同时更新 www 和 bbb。
- 多特征:同时更新 wjw_jwj(j=1,…,nj = 1, \dots, nj=1,…,n)和 bbb。
4. 示例
- 初始化:w=0w = 0w=0,b=0b = 0b=0
- 学习率:α=0.1\alpha = 0.1α=0.1
- 更新后:w=0.5w = 0.5w=0.5,b=0.3b = 0.3b=0.3

















 2277
2277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









