 BERT详解:分词、模型结构与编码器核心
BERT详解:分词、模型结构与编码器核心





 本文详细解读BERT模型的Tokenization分词步骤,包括BasicTokenizer和WordPieceTokenizer,以及BertModel的组成部分,如BertEmbeddings、BertEncoder的BertLayer,特别是BertAttention机制。深入解析了Transformer架构中关键模块的工作原理。
本文详细解读BERT模型的Tokenization分词步骤,包括BasicTokenizer和WordPieceTokenizer,以及BertModel的组成部分,如BertEmbeddings、BertEncoder的BertLayer,特别是BertAttention机制。深入解析了Transformer架构中关键模块的工作原理。
BERT结构:
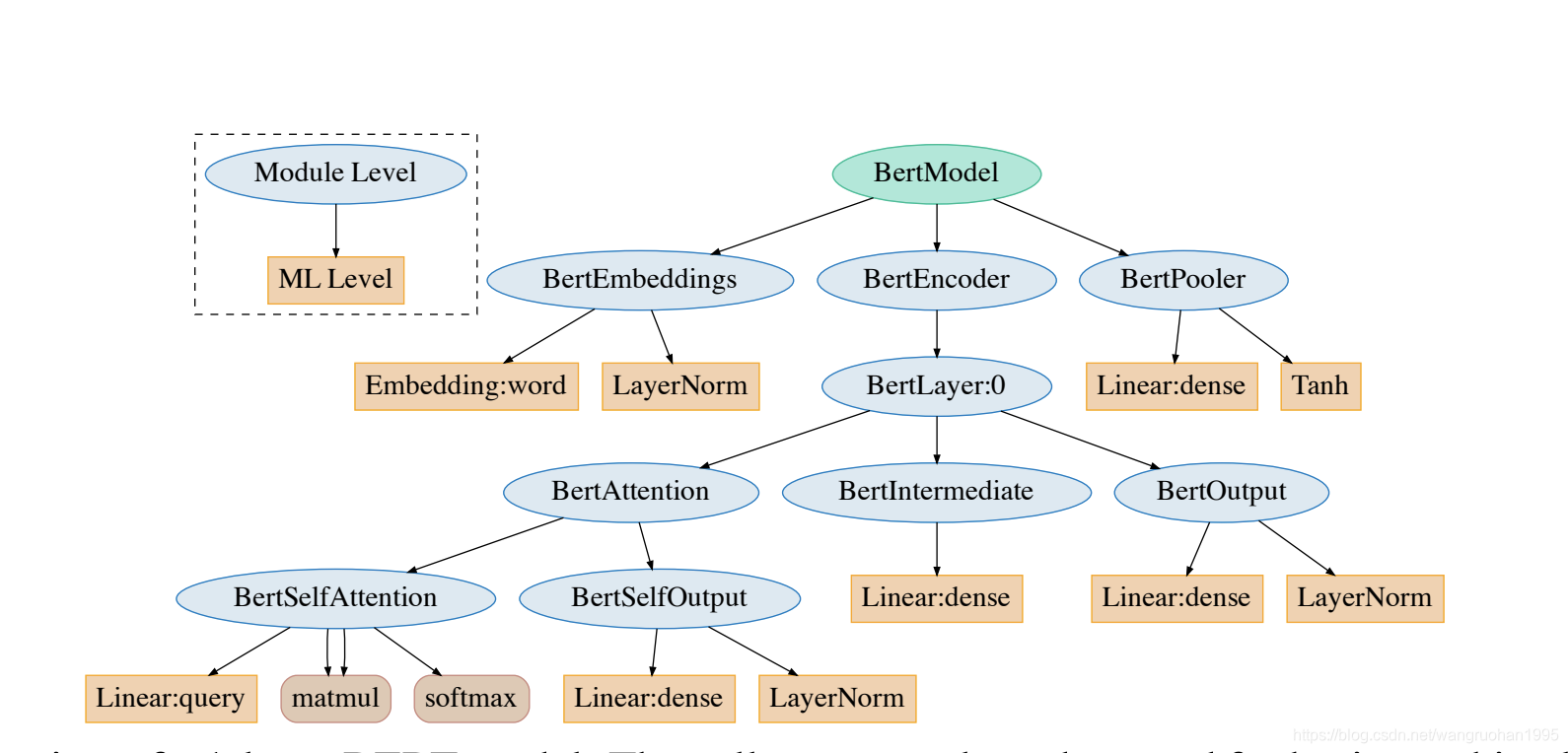
- BERT Tokenization 分词模型(BertTokenizer)
- BasicTokenizer负责处理的第一步——按标点、空格等分割句子,并处理是否统一小写,以及清理非法字符。
- WordPieceTokenizer在词的基础上,进一步将词分解为子词(subword)。
- BERT Model 本体模型(BertModel)
2.1 BertEmbeddings
根据单词符号获取对应的向量表示。
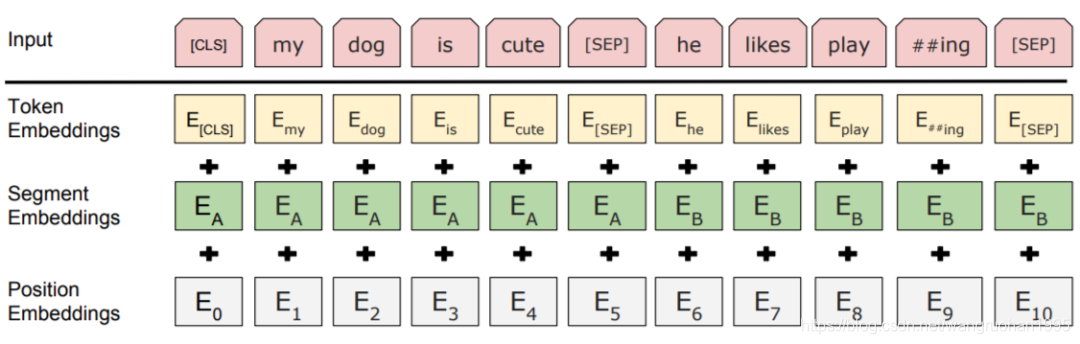
三个 embedding 不带权重相加,并通过一层 LayerNorm+dropout 后输出,其大小为(batch_size, sequence_length, hidden_size)。
2.2 BertEncoder
2.2.1 BertLayer
2.2.1.1 BertAttention
BERT结构的核心部分
2.2.1.2 BertIntermediate
全连接 + 激活
2.2.1.3 BertOutput
在这里又是一个全连接 +dropout+LayerNorm,还有一个残差连接 residual connect
2.2.2 BertPooler
这一层只是简单地取出了句子的第一个token,即[CLS]对应的向量,然后过一个全连接层和一个激活函数后输出:(这一部分是可选的,因为pooling有很多不同的操作)
Reference
https://github.com/datawhalechina/Learn-NLP-with-Transformers

















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









