



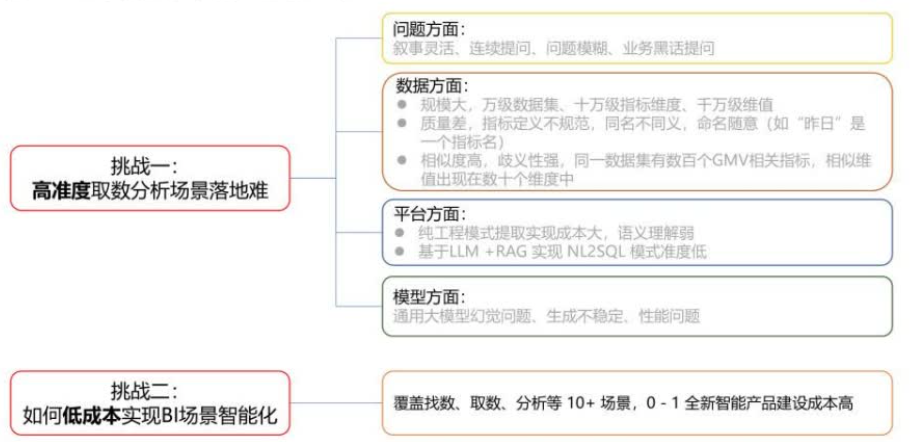
主要面临两大挑战:首先是高准度取数分析场景落地难。
问题方面-用户叙述方式灵活,如基于上下文的模糊提问或行业黑话提问。
数据方面-数据规模庞大(数十万数据集、数千万维值等),数据质量参差(指标定义不一致、命名随意等),数据重复与相似度高(如同一个数据集存在数百个GMV相关指标等)。
平台方面:基于NLP或规则实现成本高且语义理解弱;RAG+大模型生成SQL的模式在复杂场景下准确率低。
模型方面:通用大模型存在幻觉问题,生成不稳定,性能和成本难以平衡。
第二是实现成本高:建设全新智能产品需要投入大量资源,成本较高。
解决思路:
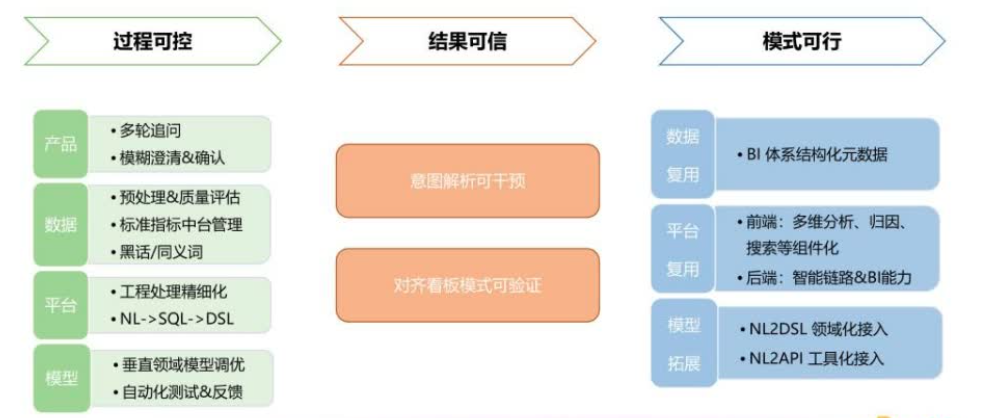
(1)过程可控
产品层面:支持上下文记忆与多轮追问;提供模糊问题的澄清和确认机制,解决无法同时查询的指标维度或存在歧义的问题。
数据层面:确保高质量的元数据接入,通过元数据预处理和元数据质量评估;对于质量较差的元数据,依托快手标准指标中台对元数据进行管理和规范化。
平台层面:实施精细化流程处理,拆解粗粒度流程,把每一步做到极致,例如:多路召回、重排序、多次大模型交互等优化,实现更高效的智能化操作。
模型层面:针对不同功能进行垂直领域模型训练与推理优化,并结合自动化测试与反馈机制来加速模型效果优化迭代节奏。
(2)结果可信
意图解析可干预:事中,通过对模糊问题澄清确认,进一步明确用户意图,从而得到准确的取数结果;事后,通过GUI进行分析要素编辑,实现”递进式的二次分析“。
通过复用模式(基于原图表)、联动模式(基于原图表+全局筛选)、洞察模式(基于原图表+扩展的分析要素)三种模式实现基于看板图表的“二次分析”,进而实现取数结果的可验证。
(3)模式可行
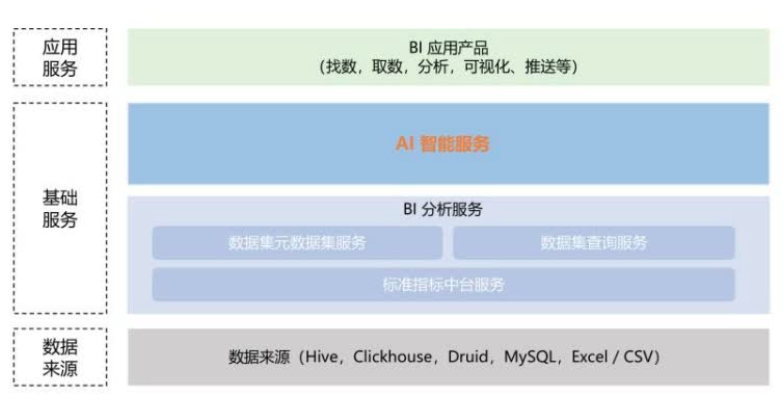
标准化指标中台服务:实现指标维度定义和管理,实现了一处定义、多处复用,解决了元数据质量差、口径不一致等问题。
统一数据集服务:整合标准和非标准数据集服务,提供元数据和查询支持,为智能取数打下基础。
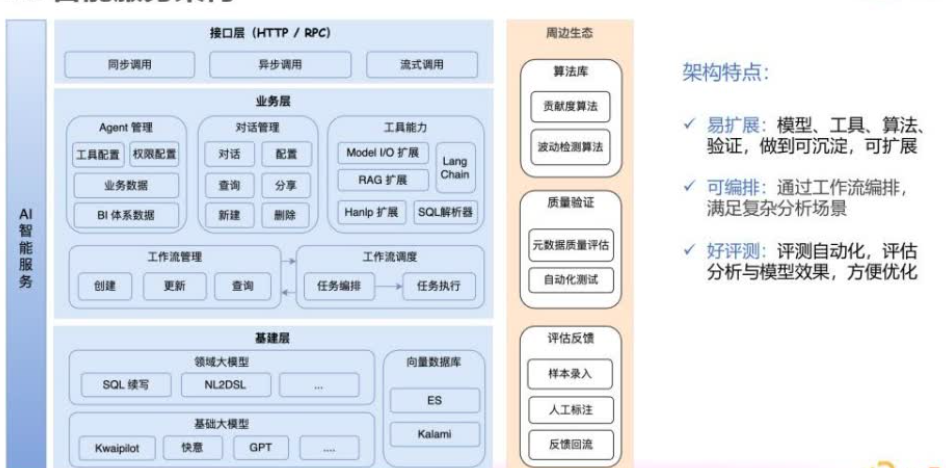
AI智能服务为“三横一纵”架构。
基建层:包含通用大模型、垂直领域模型,以及向量数据库等基础设施。
业务框架层:实现智能化核心逻辑,包括Agent管理、对话管理、复杂分析场景工作流编排等,并基于LangChain衍生出了一些核心工具能力。
接口层:通过HTTP、RPC协议开放智能服务能力,提高业务分析能力。
智能化周边生态能力:包括算法库、元数据质量评估、自动化评估等。
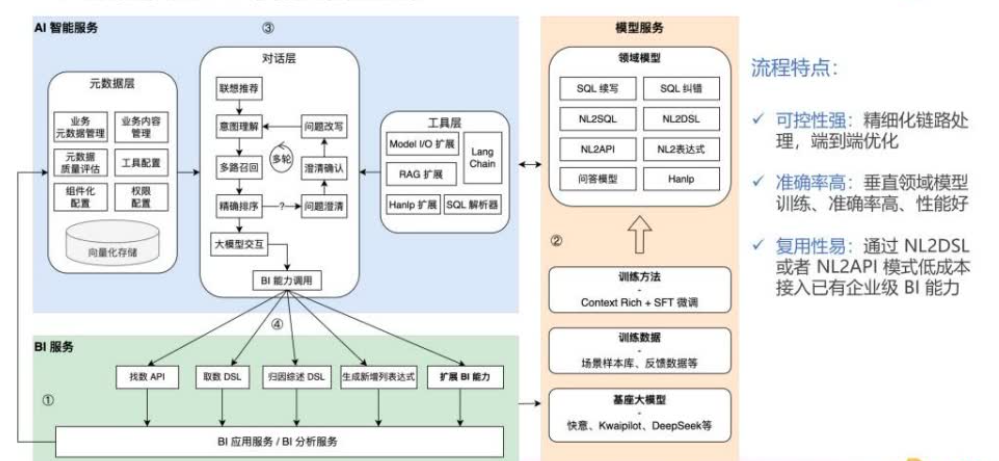
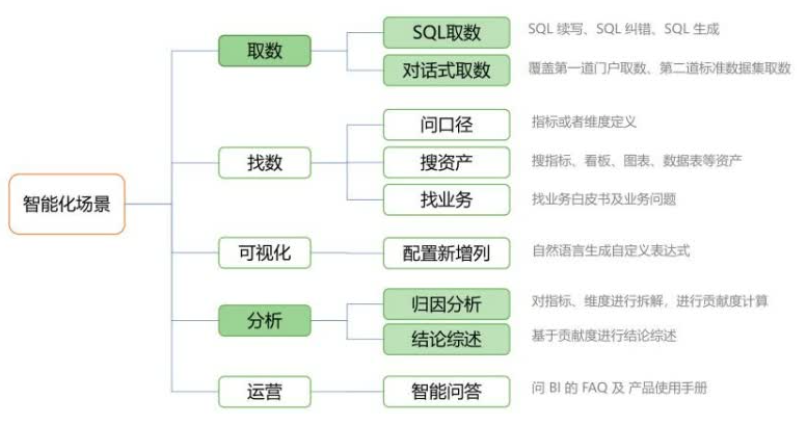
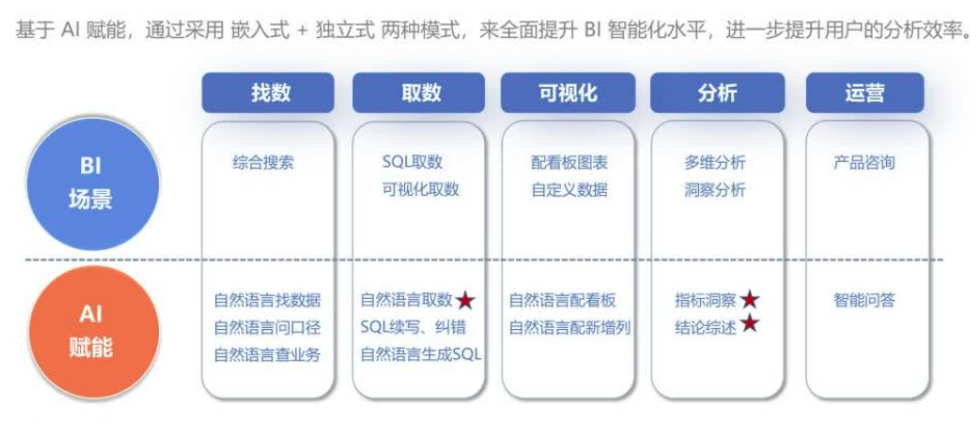
取数场景细分为SQL取数和对话式取数,实现了SQL续写、纠错,以及对话式(自然语言)取数等场景落地。
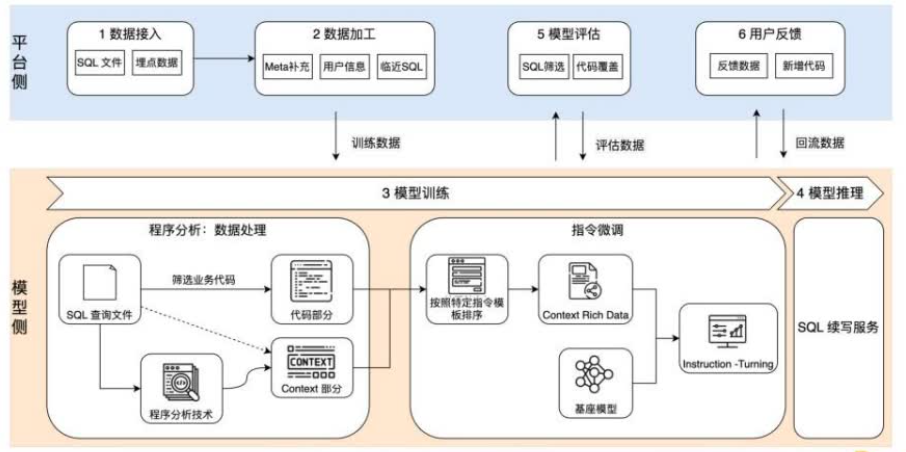
用户可通过智能SQL续写加速取数分析效率。SQL续写处理流程包括数据接入、数据加工、模型训练、在线推理服务、效果评估和用户反馈。核心技术为垂直领域模型训练(其借鉴了Java代码续写训练思路),包括程序分析和指令微调两大核心步骤。
对话式取数:

整体流程:意图理解、分析要素召回、排序、生成DSL和查询执行。
例如,一个取数问题为“昨日女装亲子的大盘GMV”,其中大盘GMV指的是风控后支付GMV。
经过分析要素召回,可以得到一个经营分析DEMO数据集,其中包括风控后支付GMV这一指标,以及8个与女装相关的维度
进一步需要做维值澄清,以明确用户意图。
澄清后进行问题改写,得到较为明确的问题,再次经过分析要素召回和排序等处理流程,得到唯一符合预期的维度,再调用大模型结合分析要素,生成取数DSL,最终执行该DSL,得到取数结果。
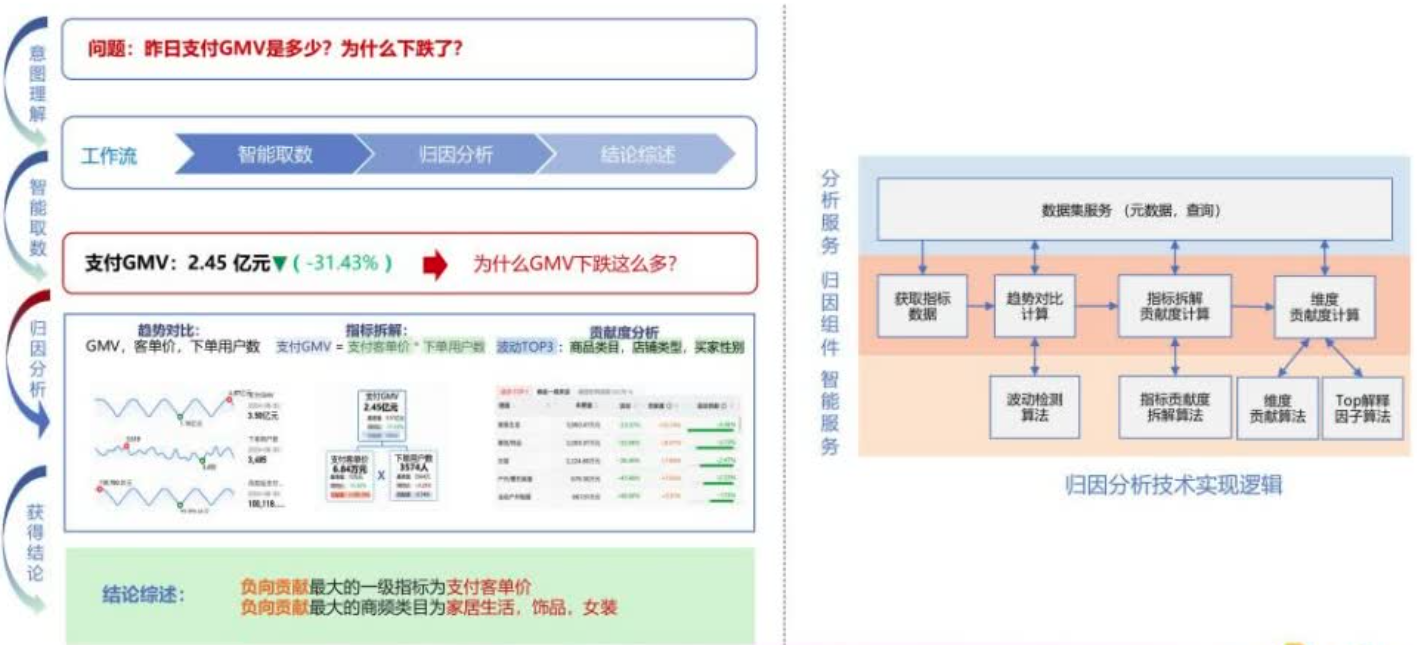
经过意图理解,得到一个工作流,首先是智能取数,接着进行归因分析,联动BI归因组件进行趋势对比、指标拆解和贡献度计算等固定编排,最终给出结论综述。

















 1527
1527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









