



1、refresh_interval
控制索引刷新的时间间隔。增大这个值可以减少I/O操作,从而提升写入性能,但会延迟新文档的可见性
查看
GET /content_erp_nlp_help_202503191453/_settings?include_defaults=true
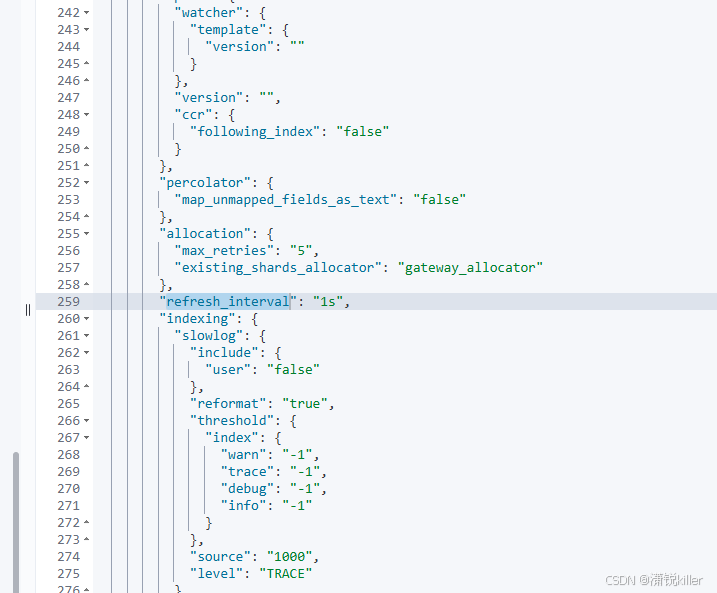
- 动态修改:
refresh_interval是一个动态设置,可以在运行时通过_settingsAPI修改。 - 全局默认值:如果你没有为索引单独设置
refresh_interval,它会使用集群级别的默认值1s。 - 性能影响:调整
refresh_interval会影响数据的实时性和写入性能。较大的值(如30s或60s)适合批量写入场景,较小的值(如1s)适合实时搜索场景。
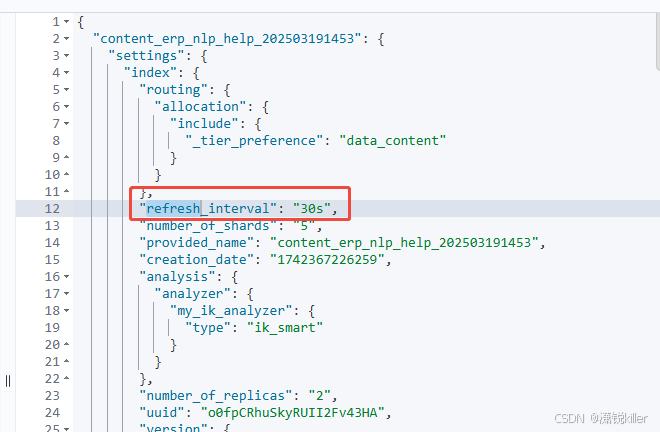
PUT /content_erp_nlp_help_202503191453/_settings
{
"index.refresh_interval": "30s"
}
GET /_cat/thread_pool?v&h=id,name,active,rejected,completed,size,queue
在 Elasticsearch 8.14 中:
默认 thread_pool.search.size = CPU 核心数 × 3。
默认 thread_pool.search.queue_size = 1000。

















 1608
1608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









